Sommaire
- Chapitre 1 : Notions fondamentales
- Chapitre 2 : Architecture d'un ordinateur
- Chapitre 3 : Microprocesseur
- Chapitre 4 : Mémoires
- Chapitre 5 : L'architecture Core
- Chapitre 6 : Optimisation : au coeur du core
- Bibliographie
3. Microprocesseur
3.1 Introduction
Pour comprendre comment fonctionne un ordinateur, il faut avant tout comprendre son mode de fonctionnement interne.
Les circuits électroniques sont capables de réaliser des calculs complexes en utilisant une représentation de l'information binaire.
Nous nous focaliserons plus particulièrement, au cours de ce chapitre, sur le microprocesseur vu en tant qu'élément d'un dispositif permettant d'exécuter les programmes. Notre but étant d'apprendre à programmer en assembleur, le langage exécuté par les microprocesseurs.
3.1.1 L'invention du transistor
L'invention du transistor date du 23 Décembre 1947, lorsque William Shockley, Walter Brattain et John Bardeen mirent au point le transistor avec point de contact (point-contact transistor) aux Bell Laboratories.
Leur invention fut révélée au public en 1948 et ils obtinrent le prix Nobel en 1958.

The point contact transistor (size 1.25 inch)
From State of the Art, A Photographic History of the Integrated Circuit
Stan Augarten, Ticknor and Fields, 1983.
"L'une des plus importantes découverte du 20ème siècle, le transistor, fut une conséquence de la recherche sur les radars effectuée aux USA et en Grande Bretagne durant la seconde guerre mondiale. Alors qu'ils travaillaient sur une nouvelle méthode de détection d'objets volants, les scientifiques ont commencé à étudier une gamme de solides peu connus appelés semiconducteurs. Des matériaux comme le Silicium et le germanium, qui occupent la même colonne dans la table périodique des éléments, semblaient disposer d'un grand potentiel en tant qu'amplificateurs de courant et apparaissaient comme des substituts intéressants des tubes à vides."
(voir [Augarten 83], page 2)
Le but du projet initié aux Bell Labs en 1945 était de trouver une alternative au tubes à vides qui souffraient de plusieurs défauts :
- ils étaient fragiles,
- leur production coûtait relativement cher,
- ils consommaient énormément d'énergie que ce soit en tant qu'amplificateur ou qu'interrupteur.
L'ampoule électrique fut inventée par Henry Woodward en 1874. Son invention fut ensuite améliorée par Thomas Edison, puis John Ambrose Fleming qui créa la diode en 1904. Enfin Lee De Forest eut l'idée en 1906 d'ajouter troisème electrode à la diode et créa le tube à vide qu'il baptisa audion, mais fut plus connu sous l'appelation triode.

Quelques dates :
- 1947 : transistor à point de contact, Bell Labs
- 1950 : transistor à jonction, Bell Labs
- 1958 : premier circuit électronique, Texas Instruments
- 1962 : transistor MOS, RCA
- 1970 : première RAM statique 256 bits, 4100, Fairchild
- 1970 : première RAM dynamique, 1024 bits, 1103, Intel
- 1971 : le premier microprocesseur, 4004, Intel
- 1971 : la première EPROM, 1702, Intel
- 1972 : le premier microprocesseur 8 bits, 8008, Intel
- 1975 : microprocesseur 6502, Synertek
- 1976 : microprocesseur Z80, Zilog
- 1977 : première RAM dynamique 64 ko, IBM
- 1979 : microprocesseur 68000, Motorola
- 1981 : première RAM dynamique 288 ko, IBM
- 1981 : premier microprocesseur 32 bits, Hewlett packard
3.1.2 Fonctionnement du transistor
Transistor MOSFET
De nos jours la grande majorité des transistors des circuits intégrés sont de type MOSFET. Le Metal Oxide Semiconductor Field Effect Transistor - MOSFET) est dérivé du transistor à effet de champs (Field Effect Transistor - FET).
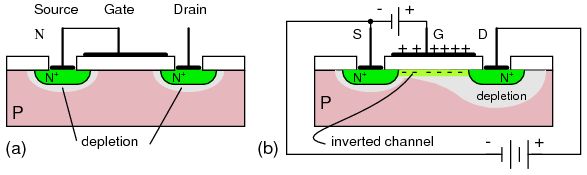
Transistor MOSFET (image issue de all about circuits)
- Une charge positive appliquée à la porte (GATE) génère une charge positive au dessus de la porte
- le substrat P-type sous la porte prend une charge négative
- il se forme alors une région d'inversion (zone de déplétion) avec un excès d'électrons qui crée un canal qui permet aux électrons de circuler de la source vers le drain
la finesse de gravue d'un circiut
La finesse de gravure (logic process) joue un rôle majeur dans l'amélioration des performances des transistors et donc des circuits intégrés. Son évolution est définie par l'ITRS (International Technology Roadmap for Semiconductors)
Un Wafer : galette de Silicium
Si on est capable de graver plus finement un circuit, celui-ci occupera moins de place sur un morceau de Silicium : si on divise par 2 la taille du tracé, on divise par 4 la surface occupée par le circuit.
- on peut donc utiliser ce gain de place pour graver plus de circuits sur une même surface et donc augmenter son rendement ou ajouter de nouvelles fonctionnalités au circuit : comme l'intégration du coprocesseur au sein du 80486 en 1989.
- en outre, un circuit dégage de la chaleur (dissipation thermique) qui est proportionnelle à la surface du circuit.
Pour un wafer de diamètre [d, mm] et un circuit de taille [S, mm2], le nombre de circuits que l'on peut placer sur le wafer est de de l'ordre de (Die Per Wafer [DPW]) :
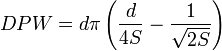
Le prix d'un wafer varie entre \$200 et \$10000 en fonction de matériau (Silicon, Gallium Arsenide, Germanium), le dopage (Phosphore, Bore), la résistivité, l'épaisseur...
| Procédé | Lithographie | Longueur porte | Wafer (mm) | Année |
| Px60 | 130 nm | 70 nm | 200/300 | 2001 |
| P1262 | 90 nm | 50 nm | 300 | 2003 |
| P1264 | 65 nm | 35 nm | 300 | 2005 |
| P1266 | 45 nm | 25 nm | 300 | 2007 |
| P1268 | 32 nm | 18 nm | 300 | 2009 |
| P1270 | 22 nm | ? | ? | 2011 |
| P1272 | 14 nm | ? | ? | 2013 |
| P1274 | 10 nm | ? | ? | 2015 |

Par exemple, avec une gravure en 32nm des circuits SRAM (mémoire cache), 291 Mbits sont formés par 1,9 Milliards de transistors (soit 6,22 T/bit).

| Processeur | Transistors | Année |
| 4004 | 2.300 | 1971 |
| 8008 | 3.500 | 1972 |
| 8080 | 4.500 | 1974 |
| 8086 | 29.000 | 1978 |
| 80286 | 134.000 | 1982 |
| 80386 | 275.000 | 1985 |
| 80486 | 1.200.000 | 1989 |
| Pentium | 3.100.000 | 1993 |
| Pentium Pro | 5.500.000 | 1995 |
| Pentium II | 7.500.000 | 1997 |
| Pentium III | 9.500.000 | 1999 |
| Pentium 4 | 42.000.000 | 2000 |
| Itanium | 25.000.000 | 2001 |
| Itanium 2 | 220.000.000 | 2002 |
| Pentium D | 376.000.000 | 2006 |
| Core 2 Duo (Conroe, 65 nm) | 291.000.000 | 2006 |
| Core 2 Duo (Penryn, 45 nm) | 410.000.000 | 2007 |
| Core 2 Quad (Penryn, 45 nm) | 820.000.000 | 2007 |
| Processeur | Millions T. | Taille (mm2) |
| Xeon 5300 (65nm) | 582 | 143 |
| Core 2 Quad (Penryn, 45nm, 2007) | 820 | 107 |
| Core i7 960 (4C,8T) (45nm, 2009) | 731 | 263 |
| Core i7 980X (Gulftown, 6C,12T) (32nm, 2010, 12 Mo L3) | 1170 | 240 |
| Intel Dunnington (45 nm, 6C) | 1900 | 503 |
| Intel Nehalem-EX (45 nm, 8C) | 2300 | 984 |
| Intel Westmere-EX (32 nm, 10C) | 2600 | 513 |
Intel 22 nm 3D Tri-Gate transistor
Pour plus d'informations : Anandtech.
Transistors 5nm (Juin 2017)
voir l'article de Tomshardware : Comparativement au 10 nm, la nouvelle finesse de gravure permettrait de concevoir des puces 40 % plus performantes ou consommant 75 % d’énergie en moins. Pour arriver à leurs fins, les chercheurs ont utilisé des transistors avec grilles circulaires (GAAFinFET ou Gate All Around FinFET) apposés sur des nanofilms permettant de mieux contrôler les performances des circuits. Ces wafers en 5 nm ont été gravés avec des lasers à ultra violet extrêmes (EUV).
Arséniure de Bore (Juillet 2018)
voir l'article de Tomshardware : Nouveau semi-conducteur offrant les mêmes performances que le silicium, mais avec une conductivité thermique beaucoup plus élevée.
- Silicium : 150 W/mK (Watts par mètres kelvin)
- Cuivre : 400 W/mK
- Diamant : 2200 W/mK
- arséniure de bore : 1000 W/mK
la loi de Moore
On April 19, 1965 Electronics Magazine published a paper by Gordon Moore in which he made a prediction about the semiconductor industry that has become the stuff of legend. Known as Moore's Law, his prediction has enabled widespread proliferation of technology worldwide, and today has become shorthand for rapid technological change. (Intel)
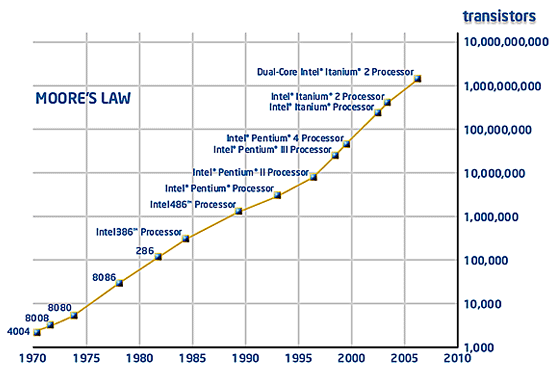
Loi de Moore (Source Intel)
Finesse de gravure et rentabilité
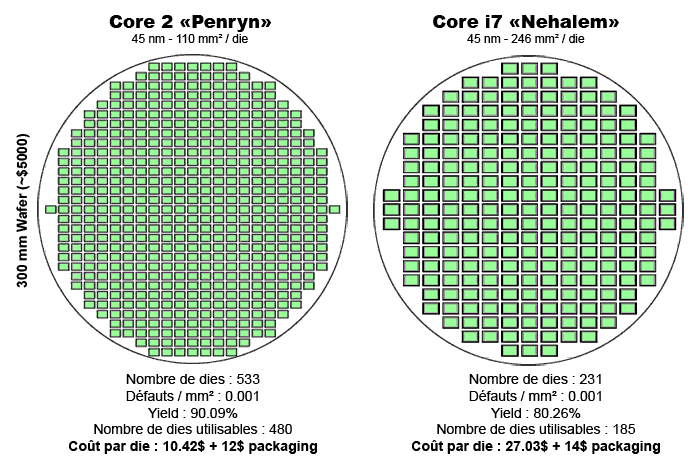
Image issue du site canardpc
Voici un petit comparatif de rentabilité entre Core 2 et Core i7 :
- les Core 2 Penryn (Dual Core) 45nm comportent 410 millions de transistors et occupent une surface de 110mm2
- les Core i7 Nehalem (Quad Core, successeur du Penryn et qui intègre un contrôleur mémoire et PCI-Express) 45nm comportent 731 millions de transistors et occupent une surface de 246mm2
Quel est le coût de revient dans chacun des deux cas pour produire 10_000 processeurs ?
- Penryn : 0,9 * 533 = 479 processeurs viables donc 10_000 / 479 = 20,87 soit 21 wafers, le coût de revient est de 21 * 5_000 + 10_000 * 22.42 = 329_200 \$.
- Nehalem : 0,8 * 231 = 184 processeurs viables donc 10_000 / 184 = 54,34 soit 55 wafers, le coût de revient est de 55 * 5_000 + 10_000 * 41.03 = 685_300 \$.
- soit un rapport de 2,08 = 685_300 / 329_200
Voir l'article suivant : Intel reveals Ice Lake Core architecture 10nm+
Tendances technologiques
Intel Tick Tock (2007)
Depuis quelques années Intel s'organise pour faire évoluer ses processeurs suivant le modèle Tick/Tock (2007) :
- Tock : mise au point d'une nouvelle architecture
- Tick : diminution de la finesse de gravure

| Architecture | Finesse | Tick ou Tock | Année |
| Conroe/Merom | 65nm | Tock | 2006 |
| Penryn | 45nm | Tick | 2007 |
| Nehalem | 45nm | Tock | 2008 |
| Westmere | 32nm | Tick | 2010 |
| Sandy Bridge | 32nm | Tock | 2011 |
| Ivy Bridge | 22nm | Tick | 2012 |
| Haswell | 22nm | Tock | 2013 |
| Broadwell | 14nm | Tick | 2014 |
| Skylake | 14nm | Tock | 2015 |
| Kaby Lake | 14nm+ | Tock | 2016 |
| Coffee Lake | 14nm++ | 2017 | |
| Cannon Lake | 10nm | 2018? | |
| Ice Lake | 10nm+ | 2018? | |
| Tiger Lake? | 10nm++? | 2019? |
Intel PAO (Process-Architecture-Optimization - 2016)
En 2016, Intel a modifié le modèle de développement Tick Tock en PAO :
- Process : mise en place d’une nouvelle finesse de gravure sur la base d’une architecture déjà maîtrisée
- Architecture : prévoit la seconde année l’arrivée d’une nouvelle micro-architecture
- Optimization : pour la troisième année, optimisation de l'architecture en place
3.1.a) le marché des semi-conducteurs en 2007
En 2007, le marché des semi-conducteurs est estimé à 271 milliards de dollars.
| rang 2006 | rang 2007 | société | % du marché mondial |
| 1 | 1 | Intel | 12,5 |
| 2 | 2 | Samsung Electronics | 7,4 |
| 4 | 3 | Toshiba | 4,6 |
| 3 | 4 | Texas Instruments | 4,5 |
| 8 | 11 | Advanced Micro Devices | 2,1 |
3.2 Algèbre de Boole et circuits numériques
algèbre de Boole
- postscript (à visionner avec Ghostview)
- pdf (à visionner avec Acrobat Reader)
circuits numériques
- postscript (à visionner avec Ghostview)
- pdf (à visionner avec Acrobat Reader)
3.3 Microprocesseur
L'invention du microprocesseur date de 1971, lorsque la société Intel réalisa le 4004.
Depuis l'apparition du Intel 4004, l'architecture n'a eu de cesse d'évoluer et nous vivons une course constante à la performance que se livrent les deux géants que sont Intel et son concurrent AMD.
La recherche de performance, si elle ne semble pas nécessaire pour les machines destinées aux particuliers, est en revanche primordiale pour l'industrie ou les domaines de recherche à la pointe du progrès, comme par exemple :
- la prédiction météorologique
- la simulation nucléaire
- la conception automobile, aéronautique et spatiale
- la bioinformatique : analyse du génome, du transcriptome
- les films d'animation en images de synthèse
Ainsi que nous l'avons vu (cf chapitre 2), l'architecture des microprocesseurs grand public repose sur l'architecture dite de Von Neumann pour laquelle l'unité de traitement des instructions et des données (le microprocesseur pour nous) se décompose en deux sous unités :
- l'ALU : unité aritmétique et logique (UAL), chargée de réaliser les calculs
- l'UC : unité de contrôle, chargée de la traduction et l'exécution des commandes (instructions)
3.3.1 Notion de registre
Afin de stocker temporairement les opérandes et les résultats des calculs, un microprocesseur est doté de registres qui sont des cellules mémoires.
Définition : registre
Un registre est un espace mémoire situé à l'intérieur du microprocesseur chargé de stocker des données temporaires qui peuvent être :
- une adresse mémoire
- des opérandes (des données en entrée d'une opération arithmétique ou logique)
- le résultat d'un calcul effectué par l'UAL.
Par exemple, sur l'Intel 8086, on trouve des registres d'une taille de 16 bits :
- 8 registres généraux : AX, BX, CX, DX, BP, SP, SI, DI
- 4 registres de segment : CS, DS, ES, SS
- 1 registre (compteur de programme) : IP
- 1 registre d'état : FLAGS
3.3.2 Caractéristiques
deux paramètres principaux permettent de caractériser un microprocesseur :
- son architecture
- sa fréquence
Viennent ensuite d'autres paramètres qui sont spécifiques aux différentes architectures, comme par exemple :
- taille des registres généraux : 32 ou 64 bits
- niveaux de cache : L1, L2, L3
- taille de la mémoire cache
- nombre de coeurs, présence de l'HyperThreading, de la Virtualisation
- jeu d'instructions SSE, AVX
- ...
Ces 2 facteurs principaux (architecture, fréquence) conditionnent les performances de la machine qui sont mesurées :
- soit en MIPS (million of instructions per second) : pour les instructions sur les entiers
- soit MFLOPS (million of floating point operations per second) : pour les calculs sur les réels
- soit en secondes par l'intermédiaire d'applications spécifiques (bureautique, jeux, multimédia, ...)
Remarque : deux processeurs ayant la même fréquence de fonctionnement ne possèdent pas forcément les mêmes performances (cf suite du cours).
Voir le site www.spec.org
3.3.3 Architectures RISC et CISC
Le microprocesseur ou Central Processing Unit - CPU en anglais, n'est en fait capable de réaliser que 3 types d'instructions :
- charger dans un registre une donnée située en mémoire à une adresse fournie en paramètre:
LOAD R,[mem] - stocker une donnée contenue dans un registre dans la mémoire à une adresse fournie en paramètre :
STORE [mem],R - réaliser un calcul entre 2 registres (R3 <- R1 OPERATOR R2) où OPERATOR = +, -, /, *, ... :
OPERATOR R3, R1, R2
Pour les microprocesseurs x86, on note :
OPERATOR R1, R2
ce qui correspond à
R1 <- R1 OPERATOR R2
- l'opérande R1 est appelée destination
- l'opérande R2 est appelée source
On distingue deux classes d'architectures pour les micrprocesseurs :
- RISC = Reduced Instruction Set Computer
(On devrait plutôt dire simplifié au lieu de réduit) : dans ce type d'architecture, on utilise le format d'instruction précédent et l'adressage mémoire reste simple (i.e. qu'il n'existe que peu de manières différentes d'accèder à une cellule mémoire)
- CISC = Complex Instruction Set Computer
pour ce type d'architecture, on a tendance à combiner une instruction de chargement ou de stockage avec un calcul et l'adressage mémoire peut être complexe. Par exemple l'instruction :ADD [EBX+ECX*4+8], EAXréalise plusieurs opérations :
- calcul de l'adresse mémoire : EBX+ECX*4+8
- chargement de la donnée stockée sur 4 octets à l'adresse calculée
- addition de la donnée avec le registre EAX et écriture du résultat à l'adresse calculée
| Architecture | Sigle | Description |
| RISC | MIPS | Microprocessor without Interlocked Pipeline Stage |
| RISC | ARM | Acorn Risc Machine (1987) ou Advanced Risc Machine |
| RISC | POWER | Performance Optimization With Enhanced RISC 1-8 |
| CISC | x86 | Intel, AMD |
| CISC | 680x0 | Motorola |
a) Historique
La conception d'un microprocesseur pose de nombreux problèmes. Plus la structure du CPU est complexe, plus les procédures de test sont longues et plus il est difficile de déterminer d'éventuels défauts de conception. Un processeur RISC, de structure moins complexe qu'un processeur CISC, est donc plus simple à mettre en oeuvre.
Plusieurs facteurs ont encouragé par le passé la conception de machines à jeu d'instruction complexe (CISC) :
- premièrement, la lenteur de la mémoire par rapport au processeur laissait à penser qu'il était plus intéressant de soumettre au CPU des instructions complexes. Pour réaliser un traitement donné, il était préférable de définir une instruction complexe plutôt que plusieurs instructions élémentaires. De plus une instruction complexe prend alors moins de temps de chargement depuis la mémoire qu'une série d'instructions,
- deuxièmement, le développement des langages de haut niveau (Fortran, Pascal, Ada) a posé de nombreux problèmes quant à la conception de compilateurs capables de traduire efficacement des programmes d'un langage évolué vers l'assembleur. On a donc eu tendance à incorporer au niveau processeur des instructions plus proches de la structure de ces langages.
En effet, dans les années 70 les ordinateurs utilisaient de la mémoire magnétique (réalisée à partir de tores) pour stocker les programmes. Ce type de mémoire était cher et lent. Un premier changement s'opéra avec l'arrivée des DRAM mais restait l'épineux problème du prix des DRAM :
- en 1977, 1 Mo de DRAM coûtait $5000
- alors qu'il ne valait plus que $6 en 1994
Le prix prohibitif des mémoires RAM et la lenteur des disques faisait qu'un code de programme était considéré comme intéressant s'il était compact.
Le processus de compilation des langages de haut niveau comme Pascal et C était lent et le code assembleur obtenu n'était pas toujours optimisé : mieux valait coder à la main.
Certains proposèrent de combler le fossé sémantique entre langage de haut niveau et assembleur afin de faciliter la tâche des programmeurs : en d'autres termes ils proposaient de faire en sorte que les instructions assembleur ressemblent aux instructions des langages de haut niveau.
On a toujours considéré que le code provenant d'un compilateur serait toujours moins performant que le code écrit à la main en assembleur par un programmeur. Cependant de nombreux progrès ont été réalisés depuis 1970.
Soit l'exemple suivant :
void swap(int t[], int k) {
int temp = t[k];
t[k] = t[k+1];
t[k+1] = temp;
}
void sort(int n, int t[]) {
int i, j;
for (i=0; i < n; i++)
for (j=i-1; j >= 0; --j)
if (t[j] > t[j+1]) swap(t,j);
}
Ce morceau de code a été traduit en assembleur par un programmeur et par un compilateur C. Le code produit par le compilateur C a obtenu un meilleur résultat à l'exécution :
| programmeur : | 37,9s |
| Compilateur C : | 25,3s |
Au milieu des années 70, deux facteurs sont venus ébranler les idées ancrées dans les esprits par les décennies précédentes :
- d'une part les mémoires sont devenues plus rapides qu'elles ne l'étaient auparavant,
- d'autre part, des études réalisées par Knuth (1971), Wortman (1972) et Patterson (1982) conduites sur des langages de haut niveau montrèrent que
- les programmes sont constitués à 85% d'affectations, d'instructions if et d'appels de procédures,
- 80% des affectations sont de la forme variable = valeur
Les résultats précédents peuvent se résumer par la phrase suivante : 80% des traitements des langages de haut niveau font appel à 20% des instructions du CPU. D'où l'idée d'améliorer la vitesse de traitement des instructions les plus souvent utilisées.
b) Architectures RISC (SPARC, Power PC, Alpha)
Des études réalisées en 1974 par John Cocke d'IBM (NY) et David Patterson 1975 montrèrent que seules 20 % des instructions d'un processeur réalisent 80 % des traitements d'un programme.
Durant les années 1980, les processeurs RISC-I et RISC-II de l'université de Berkeley virent le jour. Au début des années 1990, Apple, IBM et Motorola s'allièrent pour contrer Intel et sa prédominence sur le marché. De leur union naquit le PowerPC. On peut en outre évoquer la société MIPS qui a produit depuis 1984 des processeurs à architecture RISC ainsi que Sun Microsystems avec son SPARC (Scalable Processor ARChitecture).
Le concept RISC consiste à créer un jeu d'instructions simples mais très rapides. L'accès à la mémoire est simplifié grâce à l'utilisation de deux instructions (LOAD et STORE).
On peut ainsi :
- développer et tester un microprocesseur plus rapidement
- monter plus haut en fréquence de fonctionnement
- utiliser moins de transistors pour les décodeurs et obtenir des circuits plus petits.
- la place libérée est utilisée pour augmenter le nombre de registres et la taille des caches.
c) Architectures CISC (Intel, AMD)
Par opposition au RISC, l'architecture CISC désigne des microprocesseurs disposant d'un jeu d'instructions autorisant différents types d'accès aux données. Le but est ici de "coller" au plus près à la syntaxe des langages de programmation de haut niveau en fournissant des instructions proches de celles de ces langages.
Par exemple la grande majorité des instructions permet de faire référence à la mémoire.
d) Comparaison RISC / CISC
Chaque architecture possède des avantages et des inconvénients :
- pour le RISC, la complexité est reportée au niveau du compilateur,
- pour le CISC le décodage est plus pénalisant car les instructions sont complexes et de longueur variable, alors que pour une architecture RISC les instructions sont de longueur fixe.
En fait les processeur CISC se sont orientées progressivement vers une architecture avec un coeur d'exécution RISC, les instructions CISC sont traduites en micro-opérations RISC traitées par le coeur du processeur.
Exemple : copie mémoire
Voici un simple exemple de copie d'une tableau source vers un tableau destination qui permet d'appréhender les différences entre CISC / RISC.
- void copy(int *dst, int *src, int n) {
- while (n != 0) {
- *dst++ = *src++;
- --n;
- }
- }
1. Version MIPS (RISC)
on dispose de 32 registres.
- les paramètres sont passés dans les registres
- l'accès mémoire se fait par lw (load word) et sw (store word)
- on dispose d'instructions de style beqz, bnez qui font à la fois la comparaison et le branchement
- ; $6 = n
- ; $4 = dst
- ; $5 = src
- copy:
- beqz $6, $BB0_2 ; if (n == 0) then exit
- nop
- $BB0_1:
- lw $1, 0($5) ; $1 = *src, load word
- sw $1, 0($4) ; *dst = $1, store word
- addiu $4, $4, 4 ; ++dst
- addiu $5, $5, 4 ; ++src
- addiu $6, $6, -1 ; n = n - 1
- bnez $6, $BB0_1 ; if (n != 0) then goto BB0_1
- $BB0_2:
- jr $ra ; jump register return address
2. Versions x86 (CISC)
a) Traduction non optimisée
- copy1:
- push ebp
- mov ebp, esp
- push esi
- push edi
- mov edi, [ebp + 8]
- mov esi, [ebp + 12]
- mov ecx, [ebp + 16]
- test ecx, ecx
- jz .end
- .for:
- mov eax, [esi]
- mov [edi] ,eax
- add esi, 4
- add edi, 4
- dec ecx
- jnz .for
- .end:
- pop edi
- pop esi
- mov esp, ebp
- pop ebp
- ret
b) Amélioration avec rep movsd
- copy2:
- push ebp
- mov ebp, esp
- push esi
- push edi
- mov edi, [ebp + 8]
- mov esi, [ebp + 12]
- mov ecx, [ebp + 16]
- rep movsd
- pop edi
- pop esi
- mov esp, ebp
- pop ebp
- ret
c) Amélioration avec passage des arguments dans les registres (fast call)
- ; fast call
- ; esi = src
- : edi = dst
- ; ecx = n
- copy3:
- push esi
- push edi
- rep movsd
- pop edi
- pop esi
- ret
3.3.4 Langage machine / langage assembleur
Le langage machine est le langage compris par le microprocesseur. Il existe différents langages machines qui dépendent du type de microprocesseur. Ce langage est difficile à maitriser puisque chaque instruction est codée par une séquence propre de bits. Afin de faciliter la tâche du programmeur, on a créé le langage assembleur qui utilise des mnémoniques pour le codage des instructions :
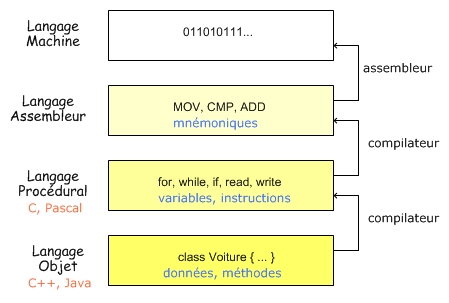
| Langage machine |
Langage assembleur |
EZ-language |
a1 18 a0 04 08
|
MOV AX,[0x804a018]
|
a,b,c are integer
|
3.3.5 Langage assembleur des Intel 80x86 32 bits
Dans cette section, nous allons donner un aperçu du langage assembleur des microprocesseurs Intel de la famille 80x86 afin de pouvoir utiliser ce langage par la suite.
Le Pentium, qui est dérivé du 80486, est un microprocesseur CISC capable d'exécuter un programme dans différents modes de fonctionnement :
- le mode protégé multitâche permet d'utiliser toute la puissance du processeur. Les registres sont des registres 32 bits.
- le mode virtuel permet à des applications 8086 (environnement DOS) de s'exécuter dans le mode protégé,
- le mode réel correspond au fonctionnement d'un 8086. Les registres 32 bits (EAX, ...) ne sont pas disponibles, on utilise des registres de 16 bits (AX, ...) et on ne peut accéder qu'à 1 Mo de mémoire.
a) Registres
Il existe 8 registres généraux (General Purpose Registers) :
- en 16 bits : AX, BX, CX, DX, DI, SI, BP, SP
- en 32 bits : EAX, EBX, ECX, EDX, EDI, ESI, EBP, ESP dont la partie basse (16 premiers bits) peut être manipulée séparément de la partie haute, on utilise alors les dénominations AX, BX, CX, DX, DI, SI, BP, SP.
- en 64 bits : RAX, RBX, RCX, RDX, RDI, RSI, RBP, RSP dont la partie basse (32 premiers bits) peut être manipulée séparément de la partie haute (cf 32 bits).
Parmi ces registres on distingue :
-
les registres de données : EAX, EBX, ECX, EDX dont la partie basse (les 16 premiers bits) se subdivise en 2 sous registres de 8 bits l'un appelé partie haute (H) et l'autre appelé partie basse (L). Par exemple : AX de décompose en AL, AH.
- EAX (accumulateur) est utilisé pour les multiplications et divisions, c'est le plus rapide pour la réalisation d'opérations arithmétiques et logiques,
- EBX (base) est utilisé comme opérande ou comme registre pointeur (cf. ci-après),
- ECX (compteur) est utilisé comme compteur dans les opérations itératives comme le transfert de données (LODSB, STOSB), EDX (data) est utilisé pour les multiplications et divisions ainsi que l'accès aux circuits d'entrées et sorties.
- les registres pointeurs et index :
- ESP (Stack Pointer) est le pointeur de pile
- EBP (Base Pointer) est généralement utilisé par le programmeur pour faire référence aux paramètres des procédures et fonctions qui sont passés dans la pile
- ESI (Source Index) permet de faire référence à la mémoire (cf. MOVSB, LOADSB, SCASB)
- EDI (Destination Index) permet de faire référence à la mémoire (cf. MOVSB, STOSB, SCASB)
- un registre à part est EIP (Instruction Pointer) représente le pointeur d'instruction, il est non modifiable par le programmeur. Seules les instructions comme CALL, RET, JMP, JNC, ... peuvent le modifier
-
les registres de segments qui combinés aux registres pointeurs et index permettent d'adresser les données.
- CS (Code Segment) : segment courant du code (CS:EIP contient l'adresse de la prochaine instruction à exécuter),
- DS (Data Segment) : segment courant des données,
- SS (Stack Segment) : segment courant de la pile,
- ES (Extra Segment) : segment additionnel,
- FS (Extra Segment) : segment additionnel,
- GS (Extra Segment) : segment additionnel.
-
un registre d'état EFLAGS (voir wikipedia pour une description détaillée) de 32 bits comprenant des indicateurs (status flags) chacun codé sur un bit :
- AF (Auxiliary Flag) : indicateur de retenue auxiliaire, mis à 1 lorsqu'il y a une retenue du quartet de poids faible dans le quartet de poids fort,
- CF (Carry Flag) : indicateur de retenue, mis à 1 lorsqu'un calcul produit une retenue sur 8 ou 16 bits,
- OF (Overflow Flag) : indicateur de débordement indiquant que l'on a dépassé les possibilités de stockage et qu'un bit significatif a été perdu,
- SF (Sign Flag) : indicateur de signe, utilisé pour les opérations sur les nombres signés,
- PF (Parity Flag) : indicateur de parité, mis à 1 si le résultat d'une opération contient un nombre pair de 1,
- ZF (Zéro Flag) : indicateur de 0, mis à 1 quand le résultat d'une opération est 0.
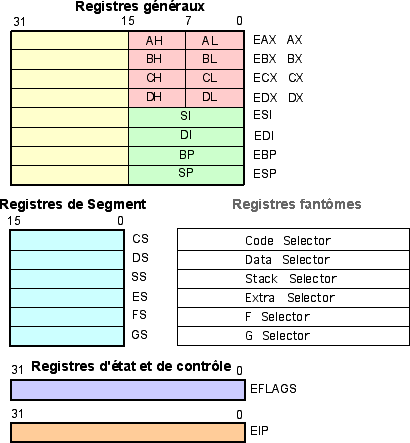
Registres du Pentium 4 avec architecture 64 bits
(image issue du site de Pierre Marchand, Université de Laval, Canada)
b) Adresse mémoire
Le calcul d'une adresse mémoire physique dépend du mode de fonctionnement du processeur.
- en mode protégé une adresse s'exprime sur 32 bits ce qui permet d'adresser jusqu'à 4 Go. Nous n'expliquerons pas le calcul de l'adresse dans ce mode.
- en mode réel (mode du 8086), les registres de données sont sur 16 bits et les adresses s'expriment sur 20 bits (1 Mo).
Pour solutionner ce problème on utilise une technique appelée ségmentation qui consiste à combiner deux registres de 16 bits pour obtenir une adresse sur 20 bits suivant la formule :
adresse 20 bits = registre segment × 16 + offset
L'offset peut être une valeur numérique, un registre ou une combinaison des deux. Toutes les combinaisons entre registre segment et registre index ne sont pas possibles :
| Registre Segment |
Registre Pointeur |
Spécification |
| CS | IP | Compteur ordinal |
| SS | SP | Sommet de pile |
| SS | BP | Accès à la pile |
| DS | SI | Source pour LODSB/W |
| ES | DI | Destination pour STOSB/W |
| DS | BX |
Pour être plus exact, la description de l'offset en mode protégé est donnée par :
Offset = Base + Index × Echelle + deplacement
avec :
- base est un registre général 32 bits ou une adresse mémoire,
- la partie Index × Echelle est facultative : Index est un registre général 32 bits (excepté ESP) multiplié par un facteur d'Echelle qui est de 1, 2, 4 ou 8. Il est de 1 par défaut,
- la partie deplacement est facultative : deplacement est une constante de 8,16 ou 32 bits
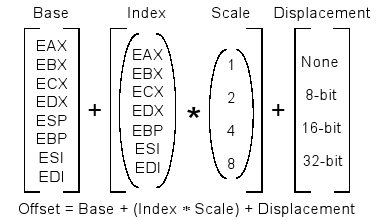
typedef struct {
char *name;
int age;
} Person;
Person tab[10];
tab[3].age = 10;
sera traduit par en mode 32 bits en :
mov ebx, 0x.... ; adresse du tableau 'tab'
mov ecx, 3
mov [ebx + ecx * 8 + 4], 10
3.3.6 Types de données
| Dénomination | Qté en bits | Codage Assembleur |
| bit | 1 | DBIT |
| byte (octet) | 8 | DB |
| word (mot) | 16 | DW |
| double word | 32 | DD |
| quad word | 64 | DQ |
Le Pentium est capable de traiter des quantités allant jusqu'à 64 bits, soit deux doubles mots de 32 bits, voire jusqu'à 80 bits pour les réels (au niveau du coprocesseur).
a) Taille des instructions
La taille des instructions varie de 1 à plusieurs octets, par exemple :
| Taille (en bits) | 8 | 16/32 |
| Instruction | CALL | adresse |
| Taille (en bits) | 5 | 3 |
| Instruction | PUSH | Reg |
b) Ecriture d'un programme Assembleur
Il existe conventionnellement dans les programmes élémentaires écrits en assembleur entre 2 à 3 segments :
- le segment de pile (facultatif ou défini par défaut) pour lequel on indique la taille de la pile,
- le segment de données dans lequel on définit les variables (attention, en C on distingue les données initialisées .data des données non initialisées .bss - Block Started by Symbol),
- le segment de code (.text en C) qui contient le code du programme.
Un programme assembleur aura donc la structure suivante (cas MASM/TASM) :
STACK SEGMENT 4096 ; Pile de 4096 octets
DATA SEGMENT PUBLIC
var0 DB ?
var1 DW 1234
var2 DD ?
...
DATA ENDS
CODE SEGMENT PUBLIC
ASSUME DS:DATA, CS:CODE
MOV AX,var0
...
CODE ENDS
Pour un programme écrit en NASM, la syntaxe diffère :
; GLOBAL indique que main est un sous-programme visible des autres fichiers objets
global main
; EXTERN indique que les sous-programmes existent dans d'autres fichiers objets
extern printf
extern scanf
; ========================
; ===== DATA SECTION =====
; ========================
section .data
msg_1: db 'la somme des éléments du tableau est %d',10,0
msg_2: db 't[%d]=%d',10,0
taille EQU 20
tableau: times taille dd 0
; COMMON indique l'existence d'une donnée dans un autre fichier objet
; qui occupe 4 octets
common n 4
; ========================
; ===== CODE SECTION =====
; ========================
section .text
main:
push ebp
mov ebp,esp
...
d) Instructions
Dans la suite de cette section nous décrivons les instructions de bases pour écrire des programmes simples en assembleur.
α) Instruction de transfert des données : MOV
De manière synthétique, les différents formats de MOV sont les suivants, cf page 640 du Intel Instruction Set Reference (A-M), ou mov.pdf.
Les instructions de transfert permettent l'affectation de valeurs entre registres et mémoire.
-
MOV dst, src
l'instruction MOV attribue la valeur de la source à l'opérande de destination. src peut également être une valeur constante, -
MOVSX dst, src
cette instruction se comporte comme MOV sauf qu'elle permet de convertir une valeur de 8 en 16 bits ou de 16 en 32 bits en une valeur signée, -
MOVZX dst, src
cette instruction se comporte comme MOV sauf qu'elle permet de convertir une valeur de 8 en 16 bits ou de 16 en 32 bits en une valeur non signée,
Exemples :
- MOV AH,BL (mettre la valeur de BL dans AH)
- MOV AX,100 (mettre la valeur constante 100 dans AX)
- MOV EAX,[1000] (mettre dans EAX la valeur codée sur 32 bits stockée à l'adresse 1000 en mémoire)
- MOV EDX,[EBX+ESI*4+8]
- MOVZX EAX,BYTE [ESI] ≡ MOV EAX,0 et MOV AL,BYTE [ESI]
β) Instructions arithmétiques : ADD, SUB, INC, SEC, NEG, MUL, DIV
Les instructions arithmétiques sont les suivantes :
-
ADD dst, src
réalise l'addition de dst avec src et dépose le résultat dans dst -
SUB dst, src
réalise la soustraction de dst avec src et dépose le résultat dans dst -
INC dst
incrémente la valeur pointée par dst -
DEC dst
décrémente la valeur - NEG dst réalise le complément à 2 de la valeur pointée par dst
-
MUL src (voir également IMUL)
MUL réalise une multiplication non signée entre l'accumulateur et un autre registre ou une valeur en mémoire, alors que IMUL réalise une multiplication signée. En fonction de la taille des données on obtiendra le résultat dans des registres différents :- AL × 8 bits -> AX
- AX × 16 bits -> DX:AX
- EAX × 32 bits -> EDX:EAX
On notera que MUL accepte 1 opérande de type r/m(8/16/32/64), alors que IMUL en accepte 1, 2 ou 3 (cf Intel Instruction Set Reference (A-M))
-
DIV src (voir également IDIV)
DIV opère une division non sign\'ee entre l'accumulateur et un autre registre ou une valeur, alors que IDIV réalise une division signée. En fonction de la taille des données on obtiendra le résultat dans des registres différents :- AX / 8 bits -> AL quotient, AH reste
- DX:AX / 16 bits -> AX quotient, DX reste
- EDX:EAX / 32 bits -> EAX quotient, EDX reste
Exemples :
- ADD AX,BX (ajouter la valeur de BX à AX)
- SUB EBX,100 (soustraire la valeur constante 100 à EBX)
- INC DWORD [EBX] (incrémenter la valeur 32 bits stockée en mémoire à l'adresse stockée dans EBX)
- MUL ECX (multiplier EAX par la valeur stockée dans ECX)
- DIV WORD [EBX+ESI*2] (diviser DX:AX par la valeur sur 16 bits stockées en mémoire à l'adresse obtenue par le calcul de EBX+ESI*2)
γ) Instructions logiques : AND, OR, XOR, NOT
-
AND dst, src
réalise le ET logique entre les opérandes -
OR dst, src
réalise le OU logique -
XOR dst, src
réalise le OU-exclusif logique -
NOT dst
réalise le complément
δ) Instructions de comparaison : CMP, TEST
-
CMP src2, src1
réalise la comparaison de deux valeurs. On effectue en fait une soustraction entre les 2 valeurs mais seuls les bits du registres EFLAGS sont positionnés en conséquence. -
TEST src2, src1
réalise la comparaison de deux valeurs. On effectue en fait un ET binaire entre les 2 valeurs mais seuls les bits du registres EFLAGS sont positionnés en conséquence.
Exemples :
- CMP AL,CH
- CMP EBX,100
- TEST EAX, DWORD [EBX]
ι) Instructions de saut et de branchement : CALL, RET, JMP, JE, JNE, JL, JLE, JG, JGE
-
JMP adr
saut à l'adresse adr, -
CALL adr
appel de sous-programme, -
RET
retour de sous-programme, -
JE,JZ adr
Jump On Equal, ou Jump on Zero, correspond au cas ZF = 1 -
JG adr
Jump on Greater, SF = OF et ZF = 0 -
JGE adr
Jump on Greater or Equal, SF = OF -
JL adr
Jump on Less, SF != OF -
JLE adr
Jump on Less or Equal, SF != OF ou ZF = 1
| Instruction | Signification | Signé (S) ou non (U) |
| ja | Jump if above | U |
| jae | Jump if above or Equal | U |
| jb | Jump if below | U |
| jbe | Jump if below or Equal | U |
| jc | Jump if Carry | |
| jcxz | Jump if CX is Zero | |
| je | Jump if Equal | |
| jecxz | Jump if ECX is Zero | |
| jz | Jump if Zero | |
| jg | Jump if greater | S |
| jge | Jump if greater or Equal | S |
| jl | Jump if less | S |
| jle | Jump if less or Equal | S |
| jmp | Unconditional jump | |
| jna | Jump Not above | U |
| jnae | Jump Not above or Equal | U |
| jnc | Jump if Not Carry | |
| jncxz | Jump if CX Not Zero | |
| jne | Jump if Not Equal | |
| jng | Jump if Not greater | S |
| jnge | Jump if Not greater or Equal | S |
| jnl | Jump if Not less | S |
| jnle | Jump if Not less or Equal | S |
| jno | Jump if Not Overflow | |
| jnp | Jump if Not Parity | |
| jns | Jump if Not signed | |
| jnz | Jump if Not Zero | |
| jo | Jump if Overflow | |
| jp | Jump if Parity | |
| jpe | Jump if Parity Even | |
| jpo | Jump if Parity Odd | |
| js | Jump if signed | |
| jz | Jump if Zero |
e) Spécificités de nasm
documentation de nasm : documentation
On peut créer des macro-commandes qui permettent de rendre l'écriture d'un programme moins pénible :
- macros_nasm.asm
- exemple_macro_et_struc.asm (exemple avec macro et utilisation de struc, endstruc, istruc, iend)
f) obtention du code assembleur avec gcc
on utilise gcc -S -masm=intel a.c afin d'obtenir un fichier a.s qui contient le code assembleur.
g) désassemblage sous Linux
Désassembler un programme consiste à obtenir son code source assembleur à partir de son exécutable.
Pour désassembler un programme sous Linux il faut utiliser la commande objdump :
objdump -d -M intel -r -S -l --no-show-raw-insn -j .text <monexe>
- -d : désassemble
- -M intel : affiche le code au format Intel
- -r : relocation
- -S : affiche une partie du code source si possible
- -l : numéro de ligne du source
- --no-show-raw-insn : ne pas afficher les octets qui codent les instructions
- -j name : nom de la section à désassembler
Pour vous simplifier la vie, créer un alias dans votre fichier ~/.bashrc :
alias myobjdump='objdump -d -M intel -r -S -l --no-show-raw-insn -j .text'
3.3.7 Appel de sous-programmes, passage de paramètres et variables locales
En 32 bits, le passage de paramètres à des sous-programmes (procédures ou fonctions) est effectué de manière générale au travers de la pile. Les variables locales sont également allouées dans la pile. Lors de l'appel d'un sous-programme on réalise les opérations suivantes :
- on commence par empiler les paramètres du sous-programme sur la pile,
- on empile l'adresse CS:EIP de la prochaine instruction à exécuter après appel du sous-programme,
- on modifie CS:EIP pour lui donner l'adresse du sous-programme,
- on exécute le sous-programme jusqu'à atteindre une instruction RET
- avec RET, on dépile l'adresse de la prochaine instruction à exécuter et on l'affecte à CS:EIP
Fonctionnement de la pile
La pile possède une taille maximale : 4, 8 ou 16 ko en général. Au début le pointeur de pile ESP prend la taille maximale de la pile. Lorsque l'on empile une valeur on décrémente ESP. Les instructions PUSH et POP ont donc le comportement suivant :
- PUSH EAX est équivalent à ESP = ESP - 4; Mem[SS:ESP] = EAX,
- POP EAX est équivalent à EAX = Mem[SS:ESP]; ESP = ESP + 4.
Lors du retour de sous-programme les paramètres sont toujours présents dans la pile, il faut donc les supprimer. Il existe ici deux manières de procéder :
- suppression par l'appelant : (cas du langage C)
c'est le sous-programme appelant (main) qui supprime les paramètres : dans ce cas, après l'appel de sum on ajoute l'instruction ADD ESP,8, - suppression par l'appelé : (cas du langage Pascal)
c'est le sous-programme appelé (sum) qui supprime les paramètres : dans ce cas on utilise l'instruction RET avec un paramètre : RET 8.
Enfin, lors de l'appel de fonctions, on peut utiliser la pile pour passer la valeur de retour de la fonction ou un registre comme c'est le cas dans l'exemple précédent.
Exemple d'appel et traduction
// sous-programme appelé
int sum( int a, int b ) {
int r;
r = a + b;
return r;
}
// sous-programme appelant
int main( ) {
sum(1,2);
return 0;
}
A l'intérieur d'un sous-programme on utilise généralement la pile afin d'allouer les variables locales. Afin de faciliter l'accès aux paramètres et aux variables locales on utilise le registre EBP.
| Adresse | Code | Instructions (main) | 08048A20 | 68 02 00 00 00 | PUSH DWORD 2 |
| 08048A25 | B8 01 00 00 00 | MOV EAX,1 |
| 08048A2A | 50 | PUSH EAX |
| 08048A2B | E8 23 00 00 00 | CALL 08048A53 |
| 08048A30 | ... | ... |
| Adresse | Code | Instructions (sum) |
| 08048A53 | 55 | PUSH EBP |
| 08048A54 | 89 E5 | MOV EBP,ESP |
| 08048A56 | 81 EC 04 00 00 00 | SUB ESP,4 ; (variable r, équivalent à PUSH EAX) |
| 08048A5C | 8B 45 08 | MOV EAX,[EBP+8] |
| 08048A5F | 03 45 0C | ADD EAX,[EBP+12] |
| 08048A62 | 89 45 FC | MOV DWORD [EBP-4],EAX |
| 08048A65 | 8B 45 FC | MOV EAX,DWORD [EBP-4] |
| 08048A68 | 89 EC | MOV ESP,EBP |
| 08048A6A | 5D | POP EBP |
| 08048A6B | C3 | RET |
Voici l'état de la pile une fois à l'intérieur de la fonction sum :
| ESP | Valeur (hexa) | EBP | Indication |
| ESP-4 | 00.00.00.02 | EBP+12 | second paramètre |
| ESP-8 | 00.00.00.01 | EBP+8 | premier paramètre |
| ESP-12 | 08.04.8A.30 | EBP+4 | adresse de retour du sous-programme |
| ESP-16 | ??.??.??.?? | EBP+0 | ancienne valeur de EBP |
| ESP-20 | ??.??.??.?? | EBP-4 | variable temporaire r |
Question : pourquoi le langage C utilise t-il une suppression des paramètres par l'appelant ?
Question : quelle est la taille de la pile sous Linux ?
ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 64159
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 64159
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
conventions d'appel
- En mode 32 bits
- en général, on commencera par empiler le dernier paramètre (cas du langage C),
- il se peut également que l'on commence par empiler le premier paramètre (cas du langage Pascal)
- cdecl : la procédure appelante qui supprimera les paramètres mis dans la pile (option __attribute__((cdecl)) de gcc)
- stdcall : la fonction appelée supprime les paramètres de la pile (option __attribute__((stdcall)) de gcc)
- fastcall : utilisation des registres EAX, EDX, ECX au lieu de passer les paramètres dans la pile (option __attribute__((fastcall)) de gcc)
En outre, en mode 32 bits, on s'attend à ce que les registres EBP, EBX, EDI et ESI ne soient pas modifiés lors de l'appel d'un sous-programme. Cela implique que le sous-programme devra sauvegarder les valeurs de ces registres temporairement dans la pile, puis les restaurer avant de quitter le sous-programme.
- En mode 64 bits
- Microsoft x64 : les paramètres sont passés dans les registres RCX, RDX, R8, R9. S'il y a plus de 4 paramètres, les paramètres restants seront passés dans la pile. Les registres suivants ne doivent pas être modifiés lors de l'appel d'un sous-programme : RBP, RBX, RDI, RSI, R12 à R15, xmm6 à xmm15
- System V AMD64 ABI convention : rdi, rsi, rdx, rcx, r8, r9, xmm0 à xmm7, de même RBP, RBX, RDI, RSI, R12 à R15, xmm6 à xmm15 ne doivent pas être modifiés par la procédure appelée. Un résultat réel (float, double) est retourné dans xmm0.
- de plus, sous Linux, il existe une red zone de [rsp-128] à [rsp-8] qui sert de zone temporaire de stockage. Une fonction peut se reposer sur le fait que cet espace ne sera pas modifié par une interruption ou un gestionnaire d'exception, sauf à l'intérieur du noyau ou il n'y a pas de red zone. On peut donc utiliser cet espace temporaire de stockage tant que l'on n'utilise pas push ou call. Note : cette fonctionnalité n'existe pas sous Windows.
Exemples d'appels pour la fonction int get(int *t, size_t i) { return t[i]; } :
- 32 bits :
- gcc : 10 instructions
push ebp mov ebp, esp mov eax, DWORD PTR [ebp+12] ; eax = i lea edx, [0+eax*4] ; edx = eax * 4 mov eax, DWORD PTR [ebp+8] ; eax = t add eax, edx ; eax = &t[i] mov eax, DWORD PTR [eax] ; eax = t[i] mov esp, ebp pop ebp ret - gcc -O2 : 4 instructions
mov edx, DWORD PTR [esp+8] ; edx = i mov eax, DWORD PTR [esp+4] ; eax = t mov eax, DWORD PTR [eax+edx*4] ; eax = t[i] ret - gcc -O2 : 2 instructions + __attribute__((fastcall))
mov eax, DWORD PTR [ecx+edx*4] ret
- gcc : 10 instructions
- 64 bits :
- gcc : 11 instructions
push rbp mov rbp, rsp mov QWORD PTR [rbp-8], rdi ; sauve rdi mov QWORD PTR [rbp-16], rsi ; sauve rsi mov rax, QWORD PTR [rbp-16] ; eax = i lea rdx, [0+rax*4] ; rdx = 4*rax = 4*i mov rax, QWORD PTR [rbp-8] ; rax = t add rax, rdx ; rax = &t[i] mov eax, DWORD PTR [rax] ; eax = t[i] pop rbp ret - gcc -O2 : 2 instructions
mov eax, DWORD PTR [rdi+rsi*4] ret
- gcc : 11 instructions
voir ce document pour plus de précisions.
3.4 Améliorations des microprocesseurs
3.4.1 Généralités
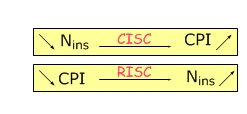
Le temps d'exécution d'un programme est donné par la formule suivante :
$$T_{exec} = N_{ins} × CPI × T_{cycle}$$
- $T_{exec}$ : temps d'exécution,
- $N_{ins}$ : nombre d'instructions,
- $CPI$ : nombre de cycles (moyen) par instructions,
- $T_{cycle}$ : temps de cycle (ns)
Les différentes évolutions des ordinateurs ont pour but de diminuer le temps d'exécution des programmes.
- la première amélioration consiste à diminuer le temps de cycle pour cela il suffit d'augmenter la fréquence des processeurs. Grossièrement, un processeur à 3 Ghz fonctionne 3 fois plus vite qu'un processeur à 1 Ghz.
-
on peut ensuite diminuer le nombre d'instructions ou le nombre de cycles par instructions. Or dans ce cas, il semble que le produit $N_{ins} × CPI$ reste constant :
- en effet si on diminue le nombre d'instructions on crée des instructions plus complexes (CISC) qui nécessitent plus de cycles pour être exécutées.
- si par contre on diminue le nombre de cycles par instructions on crée des instructions simples (RISC) et il faut utiliser plusieurs instructions pour réaliser le même traitement qu'une instruction CISC.
Il a donc fallu élaborer des solutions capables de diminuer le temps nécessaire au traitement des instructions qu'elles soient CISC ou RISC.
Les architectures des processeurs modernes jouent sur plusieurs plans, en tentant de maximiser :
- l'ILP (Instruction Level Parallelism) d'un flux d'instructions : pour un coeur, on tente d'exécuter le plus possible d'instructions en parallèle : pipeline, super-scalaire
- le DLP (Data Level Parallelism) qui consiste à exécuter la même instructions sur plusieurs données différentes : unités vectorielles MMX, SSE, AVX
- le TLP (Thread Level Parallelism) notamment dans le cas de processeurs multi-coeurs
3.4.2 Traitement des instructions
Pour schématiser, on peut dire que le traitement d'une instruction passe par 5 étapes fondamentales :
| FRONT END |
FETCH | Il s'agit de l'étape de chargement depuis la mémoire de la prochaine instruction à exécuter |
| DECODE | L'instruction est ensuite décodée et traduite pour être interprétée | |
| LOAD OPERAND | si l'instruction nécessite des données en provenance de la mémoire ou de registres, on envoie une requête afin de les récupérer | |
| BACK END |
EXECUTE | L'instruction est ensuite exécutée par l'UAL s'il s'agit d'une opération arithmétique ou logique |
| WRITE RESULT | Le résultat est mis à jour dans un registre ou en mémoire |
De manière schématique :
- le front-end (partie frontale) est constitué des étapes FETCH, DECODE, LOAD OPERAND et consiste à préparer les instructions
- le back-end composé des étapes EXECUTE et WRITE RESULT, se charge de leur exécution.
Lors de l'exécution d'une instruction, on attend d'avoir effectué les 5 étapes de traitement avant de passer au traitement de l'instruction suivante.
3.4.3 Pipelining (amélioration sur la longueur)
a) principe
Le but du pipeline consiste à diminuer le temps d'attente entre le traitement de chaque instruction. Plutôt que de disposer d'une unité de traitement qui réalise les 5 étapes précédentes, on décompose l'unité de traitement en 5 sous-unités. Les 80486 sont les premiers microprocesseurs de la gamme Intel à utiliser le pipeline.
Dès que la première instruction a terminé l'étape FETCH, elle passe dans la sous-unité DECODE. Dans le même temps, l'instruction suivante passe dans l'étape FETCH.
Il est préférable que chaque étpape de traitement associée à un étage du pipeline s'exécute en un cycle d'horloge. Si ce n'est pas le cas, on décompose une étape en plusieurs sous-étapes et on allonge ainsi la longueur du pipeline.
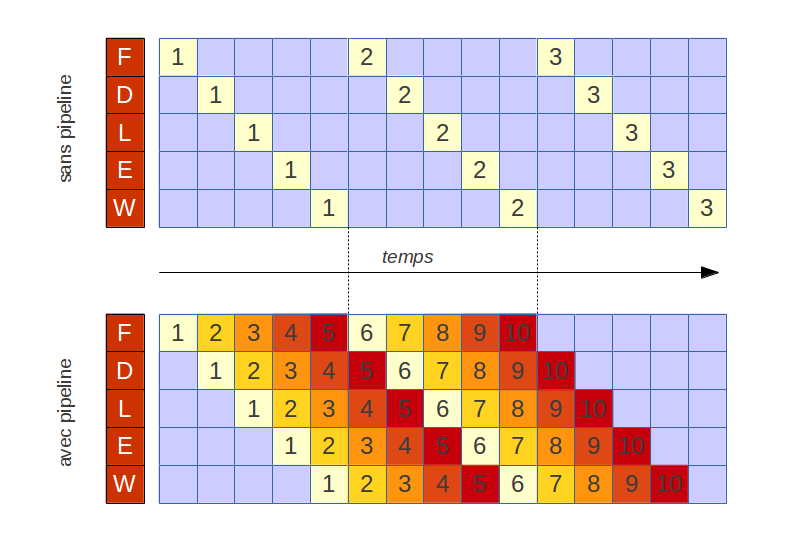
Vue suivant l'utilisation des étages du pipeline :
- sans pipeline, les circuits sont utilisés à 20% de leur capacité (1/5)
- avec pipeline, 100%
Question : quel est le gain théorique d'un pipeline de $k$ étages ?
Comme on peut le voir sur le schéma précédent, le gain est intéressant puisque l'instruction 5 se termine au bout de 9 cycles d'horloge alors que dans un modèle d'exécution sans pipeline elle serait exécutée au bout de 25 cycles.
Le gain apporté par un pipeline de $k$ étages est donné par le calcul suivant :
- temps d'exécution sans pipeline pour $n$ instructions : $n × k$
- temps d'exécution avec pipeline : $k + (n-1)$
Le gain est donné par le rapport $lim_{n → ∾} (n × k) / (k + n - 1)$ soit $k$.

Exemples de pipelines pour architectures P6 et Netburst
L'autre intéret du pipeline est qu'il permet l'amélioration des performances avec la montée en fréquence. On pourra lire à ce sujet l'excellent article de Franck Delattre et Marc Prieur sur Hardware.fr intitulé : Intel Core Duo 2
- 20 étages avec Pentium 4 Willamette et Northwood
- 31 étages avec Pentium 4 Prescott et Cedar Mill
- 45 étages prévus avec Pentium 4 Téjas (finalement abandonné)
- 14 étages avec Pentium M
- 12 étages avec Core 2 Duo
b) problèmes liés au pipeline : dépendances
|
L'exécution de l'instruction I2 nécessite que l'instruction I1 ait été réalisée. Cela implique au niveau du pipeline des états d'attente (stall). |
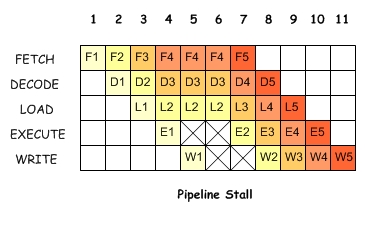
Certains mécanismes permettent cependant de remédier à ce genre de problème (réordonnancement des instructions ou forward after execute).
c) problèmes liés au pipeline : branchements conditionnels
| Exemple 1 | Exemple 2 |
|
|
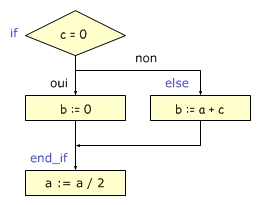
|
|
Les instructions de branchement obligent, quant à elles, à vider le pipeline.
|
Si le résultat de la comparaison de ECX avec la valeur 100 est vrai alors on doit déplacer le pointeur d'instruction (IP) vers end_while et vider le pipeline qui contient les instructions ADD EAX, ECX et INC ECX. |
Vider le pipeline prend beaucoup de temps d'autant plus que le pipeline possède un nombre important d'étages. Pour remédier à ce genre de problème on utilise un mécanisme appelé prédiction de banchement qui a pour but de recenser lors de branchements le comportement le plus probable.
Les mécanismes de prédiction de branchement permettent d'atteindre une fiabilité de prédiction de l'ordre de 90 à 95 %.
3.4.5 microprocesseurs superscalaires (amélioration sur la largeur)
Une autre amélioration possible consiste à disposer de plusieurs unités d'exécutions. Si on dispose de n unités d'exécution, on divise théoriquement le temps d'exécution par n.
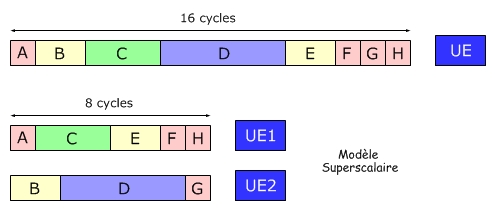
Cependant, disposer d'une batterie d'unités de traitement (ou d'exécution) n'est pas rentable si on ne peut occuper à plein régime chacunes de ces unités.
3.4.6 Combiner superscalaire et pipeline
Il s'agit ici de trouver un compromis entre amélioration en longueur et amélioration en largeur. Deux modèles semblent se détacher :
- utiliser de nombreux pipeline avec peu d'étages
- utiliser peu de pipelines avec de nombreux étages
3.4.7a Coprocesseur
Le coprocesseur est un circuit dédié au calcul des nombres flottants (réels). Du 8086 au 80486SX, les microprocesseurs Intel pouvaient utiliser un coprocesseur externe. A partir du 80486DX, le coprocesseur a été intégré au niveau du die.
- les coprocesseurs Intel sont composés de 8 registres (ST0 à ST7) de 80 bits que l'on utilise comme une pile (voire une file)
- le coprocesseur comporte un registre de status qui indique les erreurs éventuelles.
- les nombres sont chargés au niveau des registres grâce à des instructions spécifiques :
- les instructions liées au coprocesseur commencent par la lettre F
Chargement :
- FLD [mem] : charge un nombre en virgule flottante depuis la mémoire et le stocke au sommet de la pile
- FILD [mem] : de même, avec un nombre entier qui est convertit en virgule flottante
- FLDZ : charge la valeur 0
- FLD1 : charge la valeur 1
- FLDPI : charge la valeur de $π$
Stockage :
- FST [mem] : stocke le sommet de pile ST0 en mémoire ou dans un autre registre du coprocesseur
- FSTP [mem] : agit comme FST mais la valeur en sommet de pile est dépilée
- FIST [mem] : comme FST mais convertit le nombre en virgule flottante en un entier
- FISTP [mem] : comme FSTP pour les entiers
Manipulation de la pile :
- FXCH STn : échange les valeurs de ST0 et STn
- FFREE STn : libère un registre de la pile en le marquant comme inutilisé
Addition :
- FADD [mem]/STi : ST0 += src, ou src est un nombre en mémoire ou un autre registre STn
- FADD STn, ST0 : STn += ST0,
- FADDP STn : dst += ST0, puis ST0 est dépilé
- FADDP STn, ST0 : idem à l'instruction précédente
- FIADD [mem]/STi : ST0 += (float) src, ou src est un entier
Soustraction, multiplication, division :
on retrouve le même schéma pour les opérations de base :
- soustraction : FSUB
- multiplication : FMUL
- division : FDIV
Comparaison :
- FCOM src : compare ST0 à src
- FCOMP src : compare ST0 à src, puis dépile ST0
- FCOMPP : compare ST0 à ST1 puis dépile ST0 et ST1 :
- FICOM src : compare ST0 à l'entier stocké par src :
- FICOMP src : idem à la précédente instruction et dépile ST0
- FTST : compare ST0 à 0
Les instructions de comparaison changent les bits de statut du coprocesseur mais ceux-ci ne sont pas accessibles directement. Il faut transférer ces bits vers les bits du registre EFLAGS comme suit :
; if (x > y) ...
;
fld qword [x]
fcomp qword [y]
fstsw ax ; place les bits Z,C,F dans AX
sahf ; stocke AH dans EFLAGS
jna else ; pour comparaison de nombres non signés
then:
; code du then
jmp end_if
else:
; code du else
end_if:
A partir du Pentium Pro, de nouvelles instructions qui modifient directement le registre EFLAGS ont été ajoutées :
- FCOMI STn : compare ST0 à STn
- FCOMIP src : idem, puis dépile ST0
Autres fonctions :
- changement de signe : FCHS : ST0 = - ST0
- sinus, cosinus, tangente : FCOS, FSIN, FPTAN
- addition, division, ... : FADD, FSUB, FDIV, FMUL
- valeurs absolue, racine carrée : FABS, FSQRT
Exemples :
section .data
deux: dd 2.0
trois: dd 3.0
section .text
(1) FLD dword [deux]
(2) FLD dword [trois]
(3) FDIV st1
| opération | st0 | st1 | st2 | ... | st7 |
| (1) | 2 | 0 | 0 | ... | 0 |
| (2) | 3 | 2 | 0 | ... | 0 |
| (3) | 1.5 | 2 | 0 | ... | 0 |
section .text
(1) FLD dword [deux]
(2) FLD dword [trois]
(3) FDIV st1,st0
| opération | st0 | st1 | st2 | ... | st7 |
| (1) | 2 | 0 | 0 | ... | 0 |
| (2) | 3 | 2 | 0 | ... | 0 |
| (3) | 3 | 0.666 | 0 | ... | 0 |
section .text
(1) FLD dword [deux]
(2) FLD dword [trois]
(3) FDIVP st1,st0 ; fdivP
| opération | st0 | st1 | st2 | ... | st7 |
| (1) | 2 | 0 | 0 | ... | 0 |
| (2) | 3 | 2 | 0 | ... | 3 |
| (3) | 0.66 | 0 | 0 | ... | 3 |
section .text
(1) FLD dword [deux]
(2) FLD dword [trois]
(3) FDIV st0,st1
| opération | st0 | st1 | st2 | ... | st7 |
| (1) | 2 | 0 | 0 | ... | 0 |
| (2) | 3 | 2 | 0 | ... | 3 |
| (3) | 1.5 | 2 | 0 | ... | 0 |
Comment traduire une expression arithmétique en assembleur pour le coprocesseur ?
Il existe un moyen automatique assez simple :
- on traduit l'expression infixe en expression postfixe (cf. convertisseur infixe/postfixe), c'est à dire qu'on réalise un parcours Gauche, Droit, Racine de l'arbre de l'expression
- à partir de l'expression postfixe, on applique les règles suivantes :
- pour une variable ou une constante : on l'empile FLD
- pour un opérateur unaire : on l'applique sur ST0
- pour un opérateur binaire : on applique la formule F<Oper>P ST1,ST0, où Oper = ADD, SUB, MUL, DIV
Note : dans le cas d'une constante on doit la stocker en mémoire et la charger avec FLD : FLD [mem] ou FLD STi
Par exemple, à partir de $$(x + y) / (√x × z - y)$$
on obtient l'expression postfixe :
x y + x sqrt z * y - /
que l'on traduit en :
FLD dword [x]
FLD dword [y]
FADDP ST1, ST0
FLD dword [x]
FSQRT
FLD dword [z]
FMULP ST1, ST0
FLD dword [y]
FSUBP ST1, ST0
FDIVP ST1, ST0
Autre exemple : Produit de deux float en assembleur sans coprocesseur : html (code source)
3.4.7b Processeurs avec unités vectorielles
Sous Linux pour connaître les différentes technologies dont dispose un microprocesseur, il faut utiliser la commande suivante et regarder le champ flags :
\$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 158
model name : Intel(R) Core(TM) i5-7400 CPU @ 3.00GHz
stepping : 9
microcode : 0x42
cpu MHz : 1167.304
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36
clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc
art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni
pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1
sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm
3dnowprefetch intel_pt tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1
avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 dtherm
ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
....

Principe des processeurs vectoriels (Intel)
au lieu de faire:
float x[4], y[4], z[4];
for (int i=0; i<4; ++i) {
z[i] = x[i] + y[i]
}
on réalise une seule opération en parallèle sur un registre capable de contenir 4 floats
z[0:3] = x[0:3] + y[0:3]
Les processeurs vectoriels utilisent une architecture qualifiée de SIMD (Single Instruction Multiple Data) dans la classification de Flynn. Il sont capables d'effectuer la même opération sur plusieurs données différentes en même temps.
Les processeurs actuels intègrent des unités de calcul vectoriel dédiées au multimédia :
- MMX (Multi-Media eXtension) intégrée au Pentium MMX (registres 64 bits, entiers)
- 3D Now ! version MMX/SSE des processeurs AMD apparue sur les K6-II (64 bits)
- SSE (Streaming Simd Extension) apparu sur les Pentium III (128 bits, entiers ou flottants 32 bits)
- SSE2 évolution du SSE sur le Pentium 4 (flottants 64 bits)
cas des unités MMX
Les unités MMX comprennent, 8 registres de 64 bits (mm0 à mm7), ces registres permettent de manipuler les données sous forme :
- de 1 valeur de 64 bits
- ou de 2 valeurs de 32 bits
- ou de 4 valeurs de 16 bits
- ou de 8 valeurs de 8 bits
cas des unités SSE / AVX
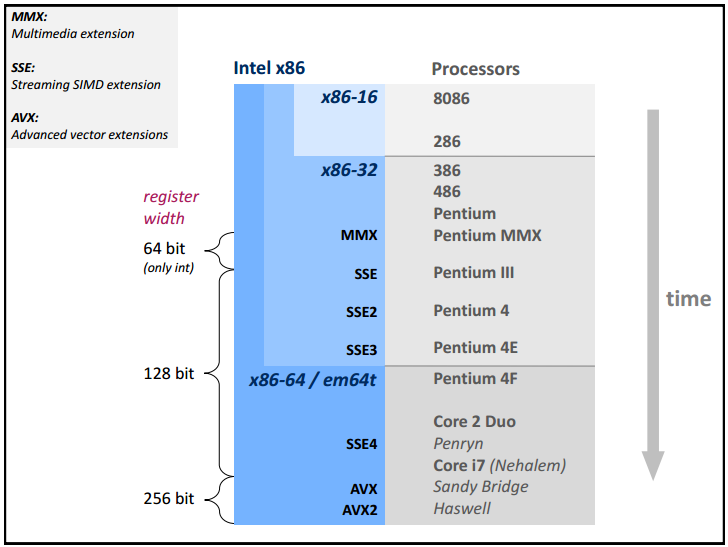
Historique SSE Intel (Intel), tiré du site de Markus Püschel

Principe des processeurs vectoriels (Intel)
- 2011 : AVX (Intel Sandy Bridge)
- 2013 : AVX2 (Intel Haswell)
Les unités SSE comprennent, en mode 32 bits, 8 registres de 128 bits (xmm0 à xmm7), ces registres permettent de manipuler les données sous la forme :
- de 2 valeurs de 64 bits
- ou de 4 valeurs de 32 bits
- ou de 8 valeurs de 16 bits
- ou de 16 valeurs de 8 bits
Les instructions peuvent être classées en 3 catégories :
- traitement des valeurs entières : MOVDQU, MOVDQA, PADD(B/W/D/Q), PAND, PCMPEQB, ...
- traitement des valeurs réelles : MOVUPS, MOVAPS, ADDPS, ADDPD, SQRTPS, SQRTPD, ...
- conversion et manipulation : CVTSI2SS, CVTPS2PD, PSHUFD, SHUFPS, UNPCKLPS, ...
Exemples de quelques instructions :
- MOVDQA xmmDst, xmmSrc/m128 move aligned data (charge dans le registre SSE depuis un autre registre SSE ou depuis la mémoire)
- MOVDQA xmmDst/m128, xmmSrc move aligned data (stocke en mémoire ou dans un autre registre SSE)
- PAND xmmDst, xmmSrc/m128 packed binary and
- PADDB/PADDW/PADDD/PADDQ xmmDst,xmmSrc/m128 packed integer addition
La plupart des compilateurs C possèdent une bibliothèque <xmmintrin.h> qui permet d'utiliser des instructions liées aux unités SSE.
- SSE : xmmintrin.h
- SSE2 : emmintrin.h
- SSE3 : pmmintrin.h
- SSSE3 : tmmintrin.h
- SSE4 : smmintrin.h et nmmintrin.h
- AVX : axvintrin.h
- AVX2 : axv2intrin.h
- popcount (popcnt) popcntintrin.h
Par exemple sous Ubuntu en 32 bits, les fichiers .h se trouvent dans le répertoire /usr/lib/gcc/i686-linux-gnu/4.8/include/
- __m128 définition d'un registre 128 bits
typedef float __m128 __attribute__ ((__vector_size__ (16), __may_alias__)); typedef long long __m128i __attribute__ ((__vector_size__ (16), __may_alias__)); typedef double __m128d __attribute__ ((__vector_size__ (16), __may_alias__)); - __m256 définition d'un registre 256 bits
typedef float __m256 __attribute__ ((__vector_size__ (32), __may_alias__)); typedef long long __m256i __attribute__ ((__vector_size__ (32), __may_alias__)); typedef double __m256d __attribute__ ((__vector_size__ (32), __may_alias__)); - _mm_malloc(size,align) permet d'allouer de la mémoire en l'alignant par rapport à une valeur
- _mm_free(adr) libère la mémoire allouée par _mm_malloc
- _mm_and_ps(xmm1,xmm2) utilisant du packed and
Exemple : SSE
Liens concernant le SSE :
cas des unités AVX et AVX2
Advanced Vector Extensions (AVX) est une extension du SSE proposé par Intel en Mars 2008 et implantée à partir de 2011 (Q1) sur les processeurs Intel Sandy Bridge puis sur les AMD Bulldozer (Q3 2011).
AVX permet notamment
- de travailler avec des registres de 256 bits YMM0,..., YMM7 (32 octets, 8 entiers 32 bits, ...)
- de préciser 3 opérandes pour une instruction : dest, src1, src2
Advanced Vector Extensions 2 (AVX2) apparaît en Juin 2013 avec les Intel Haswell et étend le jeu d'instruction AVX.
Exemple : AVX2 des processeur Intel Haswell
Exemple :
vmovdqa ymm1, [edi + ecx] ; charge 8 entiers x[i:i+7]
vmovdqa ymm3, [esi + ecx] ; charge 8 entiers y[i:i+7]
vpxor ymm0, ymm0, ymm0 ; mise à 0 de ymm0
vpor ymm2, ymm1, ymm3 ; ymm2 = x[i:i+7] | y[i:i+7]
vpand ymm1, ymm1, ymm3
vpcmpeqd ymm0, ymm0, ymm1
vpmovmskb ebx, ymm0
and ebx, 0x11111111
vpblendvb ymm1, ymm1, ymm2, ymm0
vmovdqa [edx + ecx], ymm1
popcnt ebx, ebx
add eax, ebx
3.4.8 Exécution dans le désordre (Out-Of-Order, OOO)
Les microprocesseurs actuels exécutent les instructions dans un mode dit "dans le désordre" (out of order).
Les instructions x86 (appelées macro-opérations) sont lues depuis le compteur ordinal (CS:EIP) dans un ordre précis. Elles sont ensuite décodées et traduites en une à plusieurs micro-opérations qui peuvent être exécutées dans un ordre différent de celui des instructions x86 auxquelles elles correspondent. Il faut ensuite faire en sorte de retirer (retirement ou result write back) les instructions dans l'ordre initial afin de garder la cohérence.
Ce genre de technique permet d'accélérer le traitement des instructions en tentant de minimiser les états d'attentes, mais pose également de nombreux problèmes à résoudre.
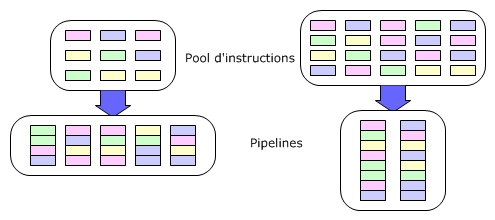
Les instructions sont chargées (FETCH) dans l'ordre puis décodées. Elles sont alors :
- stockées dans un pool d'instructions (ROB ou ReOrder Buffer) qui a pour but de garantir qu'au final, le résultat des instructions correspond à l'ordre de leur entrée,
- un autre mécanisme (RS Reservation Station) a pour but de traiter les instructions dès que les ressources sur lesquelles elles agissent sont disponibles.
Le cheminement d'une instruction est donc le suivant :
- entrée dans le ROB (40 instructions)
- traitement par la RS dès que possible
- retour dans le ROB
- mise à jour du résultat (retirement)
Un autre point important concerne une technique appelée Register Renaming utilisée pour que le mécanisme précédent fonctionne. Les microprocesseurs x86 jusqu'au Pentium 4 disposent uniquement de 8 registres généraux. Pour que l'exécution des instructions du ROB soit possible, le Pentium dispose en interne de plusieurs registres qui sont des "copies" des registres généraux.
3.4.9 La technologie VLIW / EPIC
L'approche VLIW (pour Very Long Instruction Word, EPIC chez Intel) est une approche prometteuse mais qui n'a pas connu pour le moment le succès attendu. Elle a été mise en oeuvre au sein du processeur Itanium d'Intel.
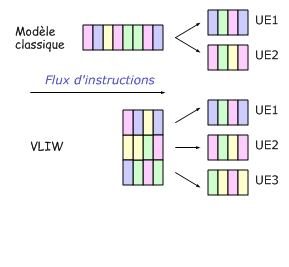
Cette technique consiste a coder plusieurs instructions dans une seule grande instruction de manière à utiliser au mieux les unités d'exécution.
Par exemple pour l'Itanium, les instructions sont codées sur 128 bits :
| Instruction 2 41 bits |
Instruction 1 41 bits |
Instruction 0 41 bits |
Gabarit 5 bits |
Intel a présenté, le 1er Novembre 2007, 7 nouveaux processeurs Itanium. Les modèles de la série 9100 se caractérisent par une architecture double coeur cadencés à 1,60 GHz (modèles N) et 1,66 GHz (série M). La taille du cache L3 varie de 8 Mo (9130M) à 24 Mo (9150N et M). La fréquence du FSB passe à 667 MHz pour la gamme M (9150, 9140 et 9130) contre 400/533 pour le reste de la série.
En mai 2017, Intel annonce que l'Itanium 9700 Kittson sera le dernier processeur utilisant le jeu d’instruction IA–64 (cf news tomshardware).
3.4.10 Les processeurs multi-coeurs
Depuis plusieurs années, les fabricants d'ordinateurs proposent des machines qui possèdent plusieurs processeurs : on qualifie ces machines de bi/quadri ou octo-processeurs suivant qu'elles connectent sur la même carte mère 2, 4 ou 8 processeurs. Il existera donc 2, 4 ou 8 sockets sur la même carte mère.
- carte mère bi-processeur
- carte mère Tyan K8QS, quadri-processeur
- carte mère iWill H8502, octo-processeur
- carte mère Supermicro quad-processeur
Le multi-coeur (multicore) consiste à ne disposer que d'un seul socket pour connecter un processeur composé de plusieurs coeurs de processeur. L'intérêt par rapport à la solution précédente réside dans le gain de performance. Les données n'ont pas en effet à transiter entre 2 processeurs en passant sur la carte mère.
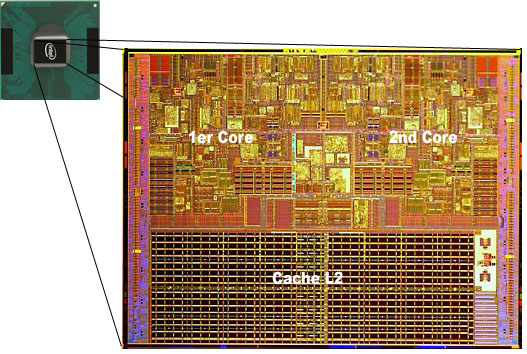
Définition : Coeur de processeur
Le coeur comprend les éléments suivants :
- les caches L1
- les circuits de décodage des instructions
- les circuits de prédiction de branchement
- les unités d'exécution
- les registres
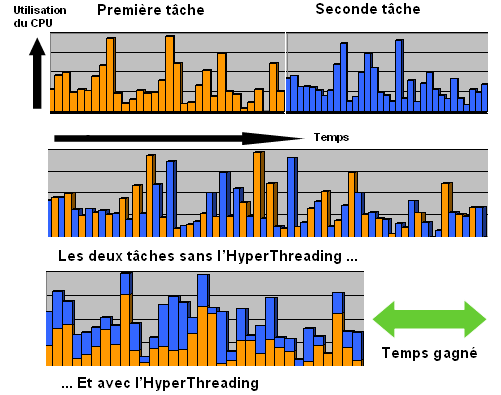
a) l'hyperthreading
L'hyperthreading (où Simultaneous Multithreading = SMT) représente la première tentative chez Intel de simulation d'un processeur double coeur. Cette technologie a été mise en place sur le Pentium 4 fonctionnant à 3.06 Ghz HT sorti en Novembre 2002.
L'hyperthreading permet d'utiliser au mieux les ressources du processeur lorsqu'il est amené à gérer plusieurs threads simultanément. L'HT apporte un gain de performance minime mais une souplesse d'utilisation indéniable. Notamment lorsqu'un programme nécessite énormément de ressources, l'hyperthreading permet de garder la main sur le système.
b) les processeurs dual-core
Les premiers processeurs double coeur pour PC sont apparus en Avril 2005. Il s'agissait des Pentium D d'Intel et des Athlon 64 X2 d'AMD.
| Processeur | Fréquence | Cache L2 | Prix |
| Athlon 64 X2 4200 + | 2200 Mhz | 2 x 512 ko | $537 |
| Athlon 64 X2 4800 + | 2400 Mhz | 2 x 1024 ko | $1001 |
| Pentium D 820 | 2800 Mhz | 2 x 1024 ko | $241 |
| Pentium EE 840 | 3200 Mhz | 2 x 1024 ko | $999 |
Intel et le dual-core
Les premiers Pentium 4 D (coeur Smithfield) n'ont pas été un succés. En fait Intel a voulu faire un effet d'annonce, en mettant le premier sur le marché, un processeur dual-core de manière à reléguer AMD au second plan. Cependant, le Pentium 4 D Smithfield est un processeur fait "à la va-vite". Il est composé de deux coeurs Prescott et chaque coeur dispose de sa propre interface de bus. Lorsque les coeurs communiquent ils doivent passer par le FSB. Ce système est donc équivalent en quelque sorte à un système bi-processeur.
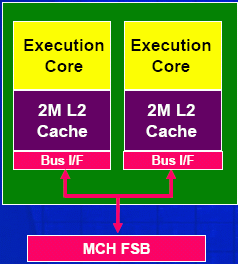
Pentium 4 à coeur Smithfield
L'évolution du Smithfield est le Presler.
| Coeur | Gravure | Surface | Transistors | Cache L2 | FSB |
| Smithfield | 90 nm | 206 mm2 | 230 Millions | 2 x 1 Mo | 200 Mhz (x4) |
| Presler | 65 nm | 376 mm2 | 376 Millions | 2 x 2 Mo | 266 Mhz (x4) |
AMD et le dual-core
Les processeurs AMD dual-core (X2) ont été pensés depuis plusieurs années. Leur conception est donc bien plus aboutie que celle des Pentium D d'Intel. Les premiers Athlon X2 ont été mis en service le 31 Mai 2005. Cependant, ils ne sont pas plus performants que les Intel Pentium D avec coeur Presler.
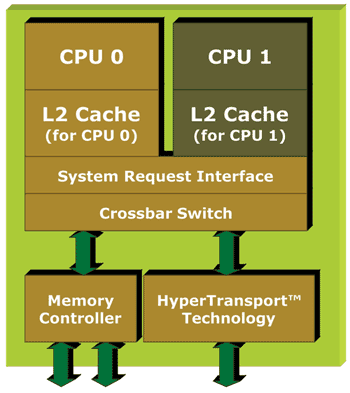
Schéma des Athlon 64 X2 d'AMD
| Coeur | Gravure | Surface | Transistors | Cache L2 | FSB |
| Manchester, Brisbane (AM2) | 90 nm | 199 mm2 | 233 Millions | 2 x 512 ko | 200 Mhz (x2) |
| Toledo, Windsor (AM2) | 90 nm | ? mm2 | ? Millions | 2 x 512 ko | 200 Mhz (x2) |
c) Intel et le quad-core
Intel annonce lors de l'IDF de Septembre 2006 la venue prochaine du Quadro un processeur quad-core, muni de 4 coeurs donc.
Ce processeur le QX6700 (core Kentsfield) correspond à la mise en place de deux Core 2 Duo mis côte à côte. En gros, il ne s'agit pas d'un véritable quad core, mais Intel nous refait le coup du Pentium D (2 coeurs E6700 à 2,66 Ghz).
Le Kentsfield n'apporte aucun gain par rapport au E6700 sauf pour les applications multithreadées, capables de répartir la tâche totale sur les différents coeurs.
Source TT-Hardware (12 février 2007)
Intel a pour la première fois atteint le cap mytique du Teraflops en 1996 avec presque 10 000 processeurs Pentium Pro 200 MHz interconnectés. L'ASCI Red consommait ainsi plus de 500 kW et autant pour la climatisation des locaux soit 1000 kW... Une dizaine d'années plus tard, Intel atteint à nouveau 1 Teraflops mais avec un seul processeur à 3,16 GHz et avec une consommation de ridicule de 62 Watts !
Présenté lors de l'ISSCC (International Solid State Circuits Conference), le TeraScale se compose de 80 cores comprenant notamment 2 unités de calcul en virgule flottante et des ports de communication. Il ne s'agit pas ici de cores comparables à ceux des processeurs classiques que nous connaissons. Ils utilisent en outre une architecture spécifique VLIW (Very Long Instruction Word). La puce compte un total de 100 millions de transistors gravés en 65 nm et occupe 275 mm. A titre indicatif, un Core 2 Duo compte 290 millions de transistors répartis sur 143 mm². A 3,16 GHz, le TeraScale ne demande qu'une tension de 0,95 v et consomme 62 watts pour dégager une puissance de calcul de 1,01 Teraflops...
Selon Intel, ce type de puce composée de cores interconnectés par un réseau maillé en 2D permet des développements beaucoup plus rapides. La conception d'un processeur traditionnel comparable aurait demandé deux fois plus de temps. Justin Rattner, directeur technique d'Intel, estime que ce type de processeur pourrait arriver dans le commerce d'ici moins de cinq ans.
On peut penser que la nouvelle ligne directrice chez Intel est à la multiplication des cores simples. Un tendance qui se retrouve dans le projet de processeur graphique Intel prévu pour 2009.
d) AMD et le quad-core
AMD a annoncé le 29 Septembre 2006, qu'il allait produire un CPU quad core K8L en 65 nm : le Barcelona (ou Altair). Il disposera de 4 x 64 Ko de cache L1, de 4 x 512 Ko de cache L2 et de 2 Mo de cache L3 partagés.
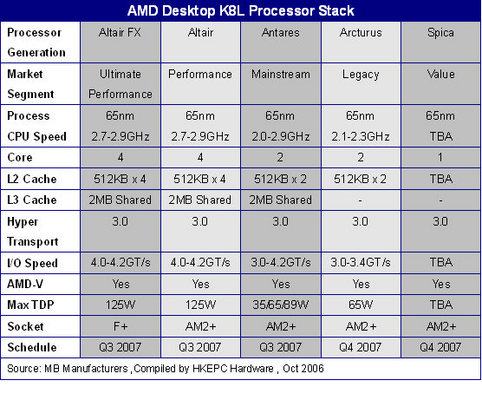
10 septembre 2007: annonce de la sortie du K10 Barcelona (serveur) qui est une architecture 4 cores :


- chaque core dispose de 128 Ko (64+64) de cache L1 et 512 Ko de cache L2
- d'unités SSE de 128 bits
- il existe un cache L3 unifié de 2 Mo
- 3 liens HyperTransport 1.0
- 463 millions de transistors gravés en technologie 65 nm SOI

Novembre 2007 : les premiers tests effectués sur les AMD Phenom 9600 (2,3 Ghz) montrent que ceux-ci sont bien moins performants que les Quad Core Intel Q6600 sortis depuis plus d'un an (TomsHardware.com a noté qu'un Phenom 9600 était en moyenne 13,5% moins performant qu'un Intel Q6600). Etant donné que ces 2 processeurs coûtent dans les 220 €, il n'y a aucun intérêt à acheter un Phenom : coup dur pour AMD !
Décembre 2007 : on apprend que le Phenom souffrirait d'un bug lié au cache L3 qui a pour conséquence de geler le système. Un patch peut être appliqué au BIOS et permet d'éviter le bug, mais on note alors une baisse de 10% en moyenne des performances !!Il faudra attendre la révision B3 prévue pour le début 2008.
Décembre 2007 : on notera qu'Intel a également détecté un bug sur ses Quad Core (Yorkfield, 45nm). Il faudra attendre mars 2008 pour disposer de processeurs exempts de bugs.
c) AMD et le Tri-core
Les deux premiers modèles du genre ont pour nom de code Toliman (T7600 et T7700), ils seront gravés en 65 nm, compatibles HyperTransport 3.0 et équipés d'un contrôleur de mémoire vive DDR2-800 intégré. Le tout viendra s'enficher sur un socket AM2+.
e) Intel et l'hexa-core
Au mois de Septembre 2008, Intel a inauguré la série des processeurs Xeon Dunnington X7400 à 6 coeurs. Ces processeurs sont composés de 3 die à double-coeurs. Le prix du processeur est de $2700 environ.
| Processeur | Coeurs | Fréquence | Cache L3 | Consommation | Prix* |
| X7460 | 6 | 2,66 GHz | 16 Mo | 130W | 2 729 |
| L7455 | 6 | 2,13 GHz | 12 Mo | 65W | 2 729 |
| E7450 | 6 | 2,40 GHz | 12 Mo | 90W | 2 301 |
| L7445 | 4 | 2,13 GHz | 12 Mo | 50W | 1 980 |
| E7440 | 4 | 2,40 GHz | 16 Mo | 90W | 1 980 |
| E7430 | 4 | 2,13 GHz | 12 Mo | 90W | 1 391 |
| E7420 | 4 | 2,13 GHz | 8 Mo | 90W | 1 177 |
En mars 2010, Intel introduit le Gulftown (Core i7 980X), version Desktop du Dunnington :
- gravée en 32nm
- doté de l'HyperTreading (6 Cores / 12 Threads)
- tournant à une fréquence de 3,33 Ghz (3,60 en Turbo Boost)
- TDP de 130 W
- 12 Mo de cache L3
- 999 dollars
- 1,17 millions de transistors
- die de 240 mm2
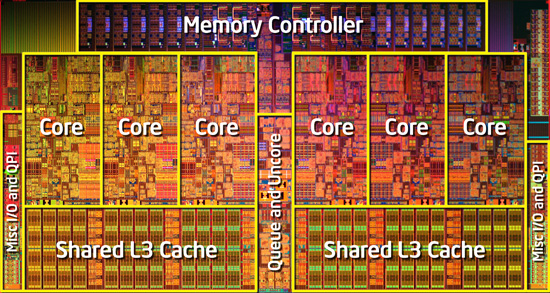
voir à ce sujet le site AnandTechcom.
e') AMD et l'hexa-core
Les premiers processeurs hexa-core d'AMD (Istanbul) font leur apparition au Japon fin Juin 2009 : gravés en 45 nm, avec une fréquence de 2.4 GHz, 512 Ko de mémoire cache L2 par core (3072 Ko totaux donc) et 6 Mo de cache L3 partagés (AMD Opteron 2427 à 2.2 GHz, et 2431 à 2.4 GHz).
f) SUN et l'octo-core
Sun a annoncé en 2006 la sortie de son nouveau processeur l'UltraSparc T1 (Niagara) qui dispose de 8 cores.
Chaque core dispose de 4 threads d'exécution, ce qui permet sur un processeur unique d'exécuter 32 tâches simultanées exécutées en parallèle.


Le 7 août 2007, Sun annonce l'arrivée prochaine du T2 :
- dissipation thermique : 95 à 103 W
- Coeurs : 8 (8 threads par coeur)
- Threads : 64
g) SUN Sparc T3
Connu aussi sous le nom Niagara 3, lancé officiellement durant l'Oracle Openworld à San Francisco en September 2010.
- 16 coeurs à 1,65 Ghz (8 threads par coeur), soit 128 threads
- supporte jusqu'à 128 Go de RAM, 4 canaux (DDR3)
Autres solutions :
h) Intel Xeon Phi
Juin 2012 : Intel vient d’officialiser ses Xeon Phi, une carte PCI-Express intégrant 50 cores x86, au moins 8 Go de GDDR5 et une version de Linux tournant indépendamment du système d’exploitation hôte. C’est l’aboutissement de son projet Knights Corner. Les processeurs seront gravés en 22 nm et utiliseront des transistors en 3D, à l’instar des Ivy Bridge. Intel parle d’une production en masse pour la fin de l’année et une mise en service des supercalculateurs utilisant son système en 2013 -- Extrait du site Tom's hardware

Prix (2013):
- Intel Xeon Phi Coprocessor 3120P (6GB, 1.100 GHz, 57 core), 300 W, $1695
- Intel Xeon Phi Coprocessor 5120D (8GB, 1.053 GHz, 60 core), 245 W, $2759
- Intel Xeon Phi Coprocessor 7120X (16GB, 1.238 GHz, 61 core), 300W, $4129
i) single vs dual vs quad
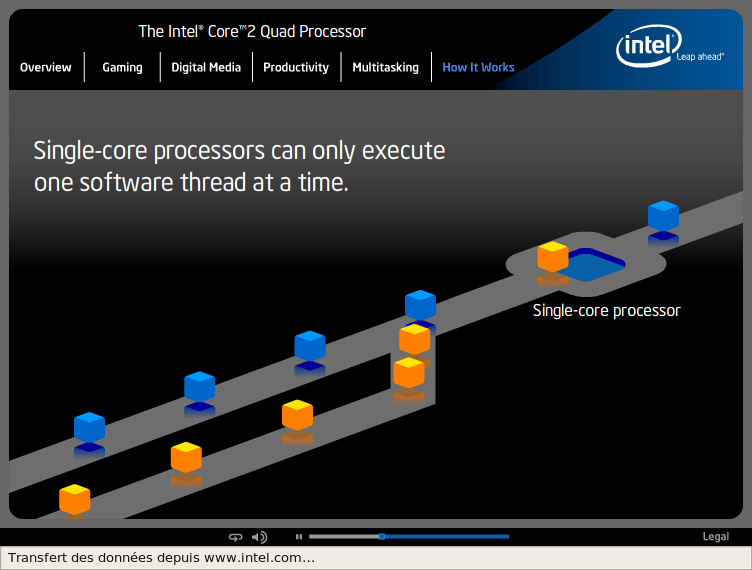
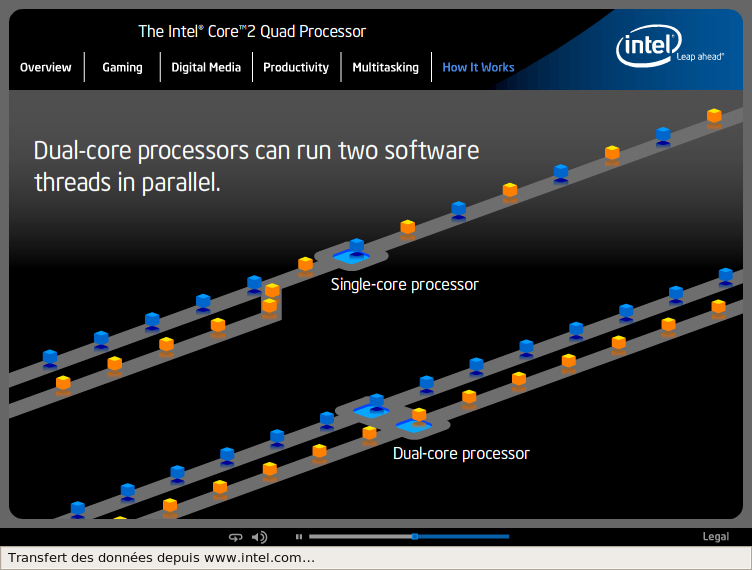
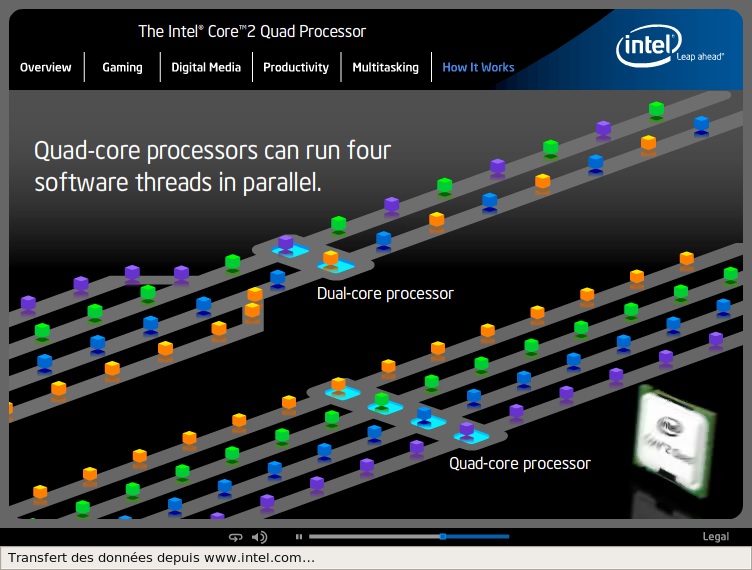
De combien de coeurs a t-on besoin ?
- le passage de 1 à 2 coeurs est intéressant pour la plupart des applications car il permet de gagner (tout dépend des applications) de l'ordre de 35% en performance (source Anandtech)
- le passage de 2 à 3 ou 4 coeurs est nettement moins profitable, par exemple le passage de 2 à 4 coeurs apporte un gain de 10%, mais peut être intéressant pour certains jeux 3D (bien que ce soit la carte graphique qui prédomine), l'encodage vidéo, la CAO, la compression de fichiers
- on peut tirer les mêmes conclusions pour le passage aux hexa-coeurs
3.4.11 Les processeurs 64 bits
AMD fut le premier à introduire la technologie 64 bits en 2003 avec ses processeurs Athlon 64 (architecture K8). Les Athlon 64 ont pour caractéristique de pouvoir exécuter des programmes aussi bien en 32 bits qu'en 64 bits. On parle également d'architecture x86-64 (EMT64 chez Intel, AMD64 chez AMD): elle assure la compatibilité avec les applications 32 bits existantes mais laisse la possibilité de passer au 64 bits.
Un processeur est dit 32 bits ou 64 bits si ses registres généraux ont une taille de 32 ou 64 bits. Un saut technologique avait déjà été franchi lors de l'apparition du Intel 80386 qui permettait le passage du 16 bits au 32 bits.
Quel est l'intérêt de passer au 64 bits ? Les applications qui bénéficieront du passage au 64 bits sont les applications de calcul scientifique principalement.
En mode 64 bits, les 8 registres généraux passent en 64 bits (EAX devient RAX) et 8 nouveaux registres supplémentaires apparaissent (R8 à R15).
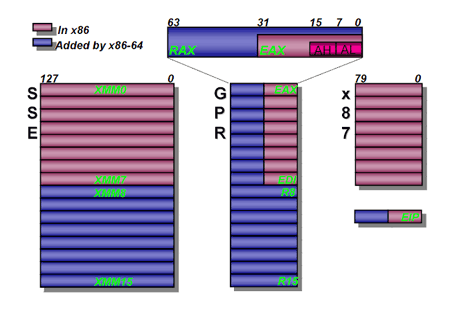
Qu'en est-il des performances de l'architecture 64 bits ?
- si on exécute un programme 32 bits dans une architecture 64 bits, on obtient normalement les mêmes performances qu'en 32 bits, ce qui semble normal.
- par contre, si on recompile un programme en 64 bits, il s'exécute plus rapidement en mode 64 bits que sa version 32 bits. En effet :
- d'une part le code est moins long (i.e. comprend moins d'instructions, même si généralement la taille du programme est plus longue)
- et d'autre part, il est naturellement optimisé par le fait que l'on peut utiliser plus de registres et donc faire moins souvent appel à la mémoire en étant contraint de sauvegarder temporairement des données ou de les recharger (cf. produit de matrices en assembleur).
On pourra lire à ce sujet l'article AMD K8 - Partie 3 : Architecture sur www.x86-secret.com (section Article, Rubrique CPU).
Remarque : des tests anciens (Août 2007) montrent que pour certains programmes, le passage en 64 bits permet de diminuer de 2/3 le temps d'exécution par rapport au 32 bits avec les Core 2 Duo (cf PCSTATS).
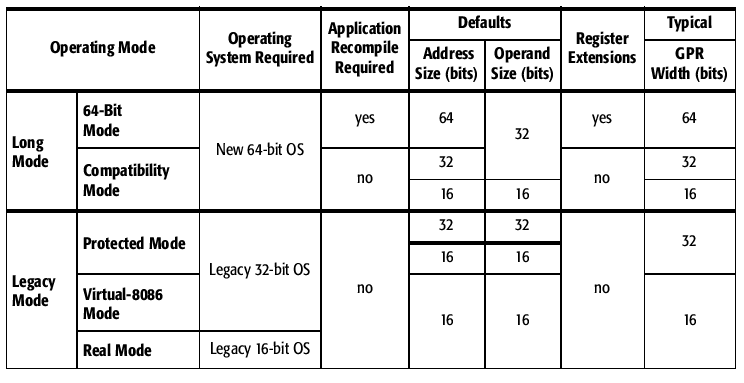
3.4.12 Fréquence de fonctionnement
Actuellement un processeur utilise plusieurs fréquences de fonctionnement:
- une fréquence au repos (IDLE)
- une fréquence lorsqu'un programme (thread/processus) le sollicite (fréquence maximale - Turbo Boost)
- une fréquence (ou une modulation des fréquences) lorsque plusieurs threads le sollicitent (fréquence en dessous de la fréquence maximale)
On peut voir le changement de fréquences en utilisant la commande suivante:
watch -n3 "cat /proc/cpuinfo | grep \"^[c]pu MHz\""
Voici quelques exemples:
Il est à noté que certains processeurs AMD Ryzen possèdent la technologie XFR (ceux estampillés X) qui permet de pousser la fréquence encore plus loin que le Turbo Boost, si la marge thermique le permet (voir XFR2)
Ceci rend les comparaisons de tests en série et en parallèle difficile puisque
- avec un thread on fonctionne avec une fréquence maximale
- et qu'avec plusieurs thread on fonctionne avec une fréquence inférieure à la fréquence maximale
Il faudra alors quand cela est possible désactiver les technologies Turbo Boost / XFR si on désire comparer ce qui est comparable.
Modèle 1 - AMD Ryzen 1700X
Le 1700X possède une plage de fréquences de 3.4 à 3.8 GHz. Le premier coeur (coeur + HT) passe à la fréquence maximale mais pas les autres coeurs.
| Repos | 1 Thread | 8 Threads |
| 1884.828 | 3643.397 | 3493.510 |
| 1890.453 | 3748.311 | 3493.509 |
| 1886.725 | 1746.701 | 3493.508 |
| 1882.866 | 1730.571 | 3493.508 |
| 1876.741 | 1744.741 | 3493.508 |
| 1878.985 | 1744.599 | 3493.509 |
| ... | ... | ... |
Modèle 2 - Intel i7 4790, i5 7400
Le i7 4790 possède une plage de fréquences de 3.6 à 4.0 GHz. Dans le cas où on sollicite un seul coeur, tous les coeurs passent à la fréquence maximale !
| Repos | 1 Thread | 4 Threads |
| 800.063 | 3997.950 | 3800.169 |
| 800.132 | 3875.932 | 3800.169 |
| 800.071 | 3916.942 | 3800.168 |
| 799.301 | 3846.592 | 3800.170 |
| 800.985 | 3807.581 | 3800.169 |
| 801.456 | 3909.223 | 3800.169 |
| 800.166 | 3815.121 | 3800.168 |
| 800.158 | 3826.660 | 3800.169 |
L'i5 7400, quant à lui, possède une plage de fréquences de 3.0 à 3.5 GHz. Cependant la fréquence maximale affichée est de 3359 Mhz !
| Repos | 1 Thread | 4 Threads |
| 1262.578 | 3359.648 | 3299.882 |
| 1299.960 | 3359.609 | 3300.000 |
| 1234.921 | 3393.281 | 3300.000 |
| 1278.164 | 3380.625 | 3300.000 |
Modèle 3
Les derniers processeurs (2018) utilisent une modulation plus fine de la fréquence :
L$'$AMD Ryzen 2700X possède une fréquence de 3,70 Ghz (allant jusqu'à 4,35 GHz en mode turbo).
3.5 Gamme de processeurs
Il semble aujourd'hui bien difficile de présenter brièvement la gamme des processeurs disponibles. Les critères de différenciation sont nombreux et peuvent être combinés :
- architecture
- fréquence de fonctionnement du processeur
- fréquence du FSB
- présence ou non de l'HyperThreading
- technologie 64 bits
- dual-core ou non
voir le Intel Ark.
| entrée de gamme | machine dotée d'un petit cache L2 et d'un FSB pas très véloce |
| milieu de gamme | machine dotée d'un cache L2 de taille moyenne et d'un FSB rapide |
| haut de gamme | machine dotée d'un cache L2 de grande taille (voire d'un cache L3) et d'un FSB rapide |
| gamme mobile | machine dotée de fonctionnalités en rapport avec la gestion de l'énergie |
| gamme ultra mobile | machine dotée de fonctionnalités en rapport avec la gestion très fine de l'énergie |
Chez Intel la déclinaison est la suivante :
- Extreme
- Performance
- MainStream
- Essential
- Value
- Atom
3.6 Mesure des performances des machines
Mesurer les performances des machines consiste à mesurer les performance du trio chipset + processeur + mémoire. D'autres tests permettent également de tester les performances de la carte graphique (élément essentiel pour les jeux 3D) ainsi que celles du disque dur.
En terme de calculs purs, SPEC (Standard Performance Evaluation Corporation) a défini un certain nombre de tests qui permettent de classer les différents processeurs.
Voici une liste de logiciels qui permettent d'évaluer les performances des machines (sous Windows XP) :
- Sandra (processeur, caches, mémoire)
- RMMA (processeur, caches, mémoire)
- HDTune (disque dur)
- Everest
- CPUZ (caractéristiques : processeur, cache, mémoire) ou son alternative Linux baptisée I-Nex
- Cachemem (mesure des performances des caches)
- SuperPI (calcul du nombre PI)
- PovRay 3.6 (Ray tracing)
Voici quelques exemples de résultats de ces différents programmes :
- Core 2 Quad Q6600
- Core 2 Duo E8400
- Core 2 Duo E6400
- Pentium M 760
- Sempron 3000 Mhz
- Athlon 64 X2 3800 Mhz
- Athlon 64 X2 4200 Mhz
- Pentium 4 Northwood 2800 Mhz
- Pentium D 830 3000 Mhz
Test utilisé en 2017
Web Tests on Chrome 56
- Sunspider 1.0.2
- Mozilla Kraken 1.1
- Google Octane 2.0
- WebXPRT15
System Tests
- PDF Opening
- FCAT
- 3DPM v2.1
- Dolphin v5.0
- DigiCortex v1.20
- Agisoft PhotoScan v1.0
Rendering Tests
- Corona 1.3
- Blender 2.78
- LuxMark v3.1 CPU C++
- LuxMark v3.1 CPU OpenCL
- POV-Ray 3.7.1b4
- Cinebench R15 ST
- Cinebench R15 MT
Encoding Tests
- 7-Zip 9.2
- WinRAR 5.40
- AES Encoding (TrueCrypt 7.2)
- HandBrake v1.0.2 x264 LQ
- HandBrake v1.0.2 x264-HQ
- HandBrake v1.0.2 HEVC-4K
Office / Professional
- PCMark8
- Chromium Compile (v56)
- SYSmark 2014 SE
Legacy Tests
- 3DPM v1 ST / MT
- x264 HD 3 Pass 1, Pass 2
- Cinebench R11.5 ST / MT
- Cinebench R10 ST / MT
Pour Linux
I-Nex un clone de CPUZ Linux
Pour installer I-Nex, exécutez les commandes suivantes dans un terminal:
sudo add-apt-repository ppa:i-nex-development-team/stable
sudo apt-get update
sudo apt-get install i-nex
Sysbench
sudo apt-get install sysbench| Test | i5-7400 CPU @ 3.00GHz Temps (s) |
sysbench --test=cpu --cpu-max-prime=20000 run |
21.61 |
sysbench --test=cpu --cpu-max-prime=20000 --num-threads=4 run |
5.90 |
sysbench --test=memory run |
26.64 |
sysbench --test=threads run |
3.22 |
sysbench --test=threads --num-threads=4 run |
1.07 |