Sommaire
- Chapitre 1 : Notions fondamentales
- Chapitre 2 : Architecture d'un ordinateur
- Chapitre 3 : Microprocesseur
- Chapitre 4 : Mémoires
- Chapitre 5 : L'architecture Core 2 et K10
- Chapitre 6 : Optimisation : au coeur du core
- Chapitre 7 : Acheter un ordinateur
- Bibliographie
5. L'Architecture Core 2, K10 et Core i7
Paul Otellini, CEO d'Intel, Juillet 2006.
5.1 Introduction, les racines du Core
Dans ce chapitre, nous allons examiner les particularités de l'architecture Core 2 qui représente entre fin 2006 et fin 2007, l'architecture la plus performante pour les PC. Nous parlerons également de l'architecture K10 chez AMD, successeur du K8.
Le successeur du Pentium III
L'architecture Netburst (Pentium 4) a été conçue dans l'optique d'améliorer les performances de l'architecture du Pentium III. Une rapide étude montre que plus le pipeline est profond, plus on peut monter en fréquence.
L'augmentation de la fréquence (et donc la profondeur du pipeline) couplée à la diminution de la finesse de gravure était sensée amener Intel à produire un processeur capable d'atteindre les 7 Ghz : le Tejas avec 45 étages de pipeline.
Willamette et Northwood
Si le premier Pentium 4 (architecture Willamette) ne fut pas un franc succès, en revanche son successeur le Northwood permit grace à des fréquences importantes (> à 2,8 Ghz) et un cache L2 de plus grande taille (512 ko au lieu de 256) de trouver le bon compromis pour un processeur performant.
Le Prescott
Le successeur du Northwood, le Prescott, bien que doté d'un cache L2 de 1 Mo (double du Northwood) et d'un pipeline de 31 étages se montra parfois moins performant que le Northwood à fréquence égale. En outre, la dissipation thermique du Prescott était très importante et elle aurait augmenté avec l'allongement du pipeline et la montée en fréquence. Netburst aboutissait donc à une impasse.
L'architecture Mobile
En parallèle de l'architecture Netburst, Intel a développé l'architecture Mobile (Pentium M, Banias, 2003), dérivée de P6, et qui montra de sérieux atouts en termes de performances et d'économie d'énergie. L'architecture Mobile a donc conduit Intel à suivre deux voies différentes : l'une pour les portables et l'autre pour les ordinateurs de bureau et serveurs.
L'architecture Core
A l'automne 2006, lors de l'IDF (Intel Developper Forum), Intel a annoncé l'abandon de l'architecture Netburst au profit de l'architecture Core.
L'architecture Core est une nouvelle architecture performante qui fait la synthèse des architectures P6 et Netburst, mais est plus proche de P6 que de Netburst. Elle a été conçue pour s'adpater aux différents segments du marché : ordinateurs portables, de bureau et serveurs.
L'architecture Core (anciennement Merom) est aussi appelée NGMA pour Next Generation MicroArchitecture.
Fort de son succès avec l'architecture Mobile, Intel a enfourché un nouveau cheval de bataille qui consiste à vanter les mérites des processeurs performants et économes (en énergie = Watt per Instruction).
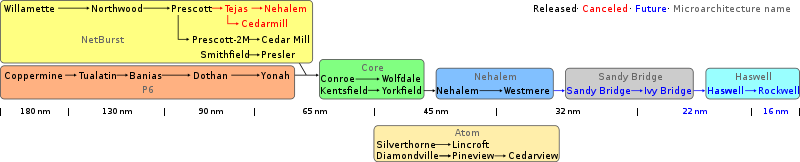
Roadmap Intel (Wikipedia)
5.2 Les architectures P6, Netburst et Core
Les images suivantes sont issues de l'article de David Kanter sur le site RealWordTech.
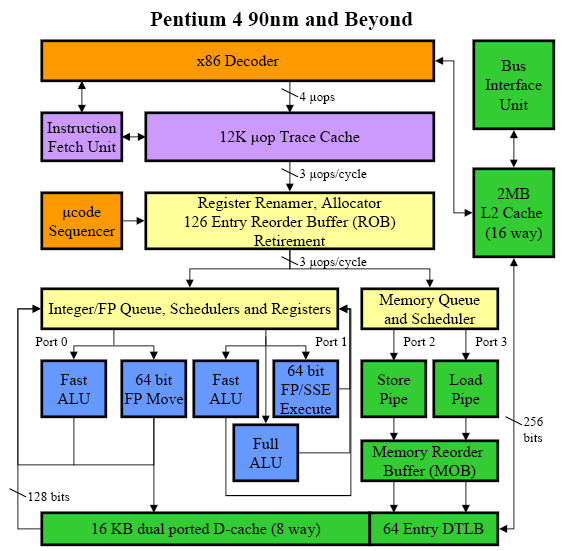
Architecture Netburst (Pentium 4)
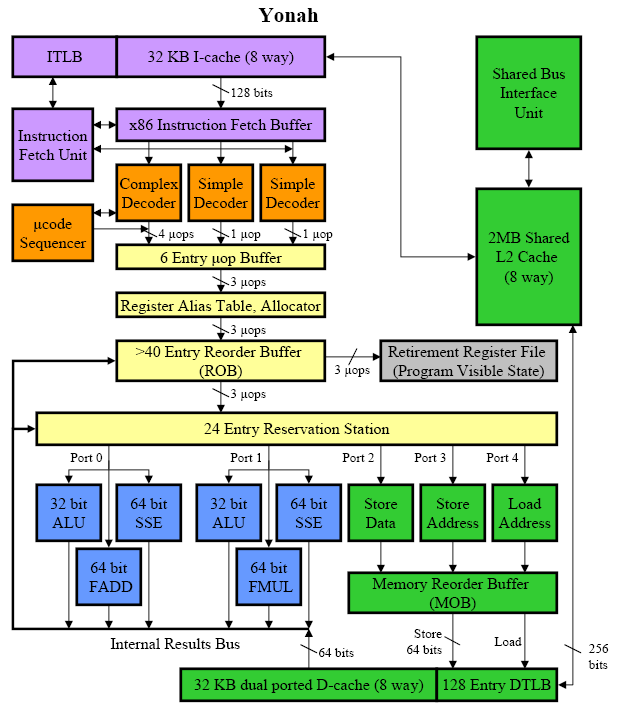
Architecture P6 (Pentium M)
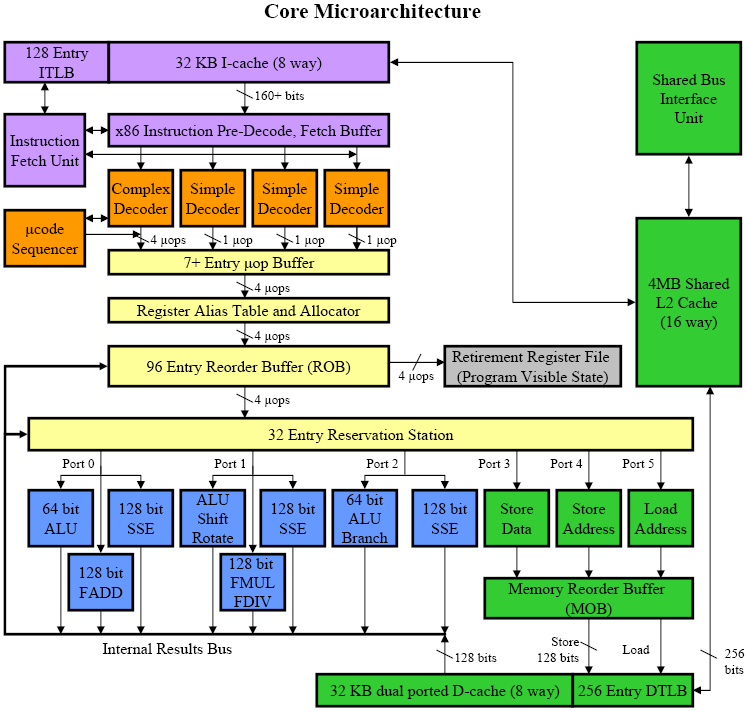
Architecture Core
5.2.1 Etape de décodage
On rappelle que les instructions assembleur x86 sont qualifées de macro-opérations et qu'elles sont traduites en interne en 1 ou plusieurs micro-opérations. Par exemple une instruction de la forme ADD [mem],EAX sera traduite en 3 micro-ops :
- charger le contenu de [mem] dans un registre temporaire :
load R1,[mem] - réaliser la somme :
addregs R1,eax - mettre le résultat dans [mem] :
store [mem],R1
Depuis l'architecture Banias, on réalise de la micro-fusion en ne faisant qu'une seule opération des deux premières.
Comme on le voit sur le schéma précédent, Core dispose :
- de 3 décodeurs simples qui traduisent les instructions qui ne prennent qu'une micro-op
- d'un décodeur complexe qui traduit les instructions complexes composées de 1 à 4 micro-op
A ces décodeurs s'ajoute un mécanisme dit de macro fusion qui consiste à fusionner deux instructions x86 en une seule qui sera ensuite traduite par 1 micro-op. Il s'agit notamment des instructions de comparaison suivies d'un saut (caractéristiques des instructions if-then-else).
MOV EAX,[MEM1]
CMP EAX,[MEM2]
JNE else --> CMPJNE EAX, [MEM2], else
Au final, Core est capable de décoder au maximum 5 instructions par cycle d'horloge (4 + 1 instruction macro fusionnée quand cela est possible). On estime que la macro fusion autorise une diminution d'environ 10% des micro-op.
5.2.2 Prédiction de branchement
La prédiction a été améliorée de manière à booster les performances de l'architecture Core.
Utilisation du Loop Detector
lors d'une boucle seule la dernière itération conduit à exécuter une partie de code différente de celle des n-1 autres itérations. La table BHT (Branch History Table) ne mémorise pas assez d'informations pour prédire correctement la fin de la boucle au dela d'un certain nombre d'itérations et en général lors de la dernière itération on réalise une mauvaise prédiction de branchement. Le Loop Detector a pour but de remédier à ce problème en déterminant qu'elles instructions correspondent à des terminaison de boucles
5.2.3 Exécution Out-Of-Order
Core reprend les caractéristiques du Yonah mais en étant plus performant (amélioration en largeur).
| Yonah | Netburst | Core | |
| Traitement d'éviction | 3 micro-op/cycle | 3 micro-op/cycle | 4 micro-op/cycle |
| Taille du ReOrder Buffer | 126 | > 40 | 96 |
| Taille de la Reservation Station | 24 | 46 | 32 |
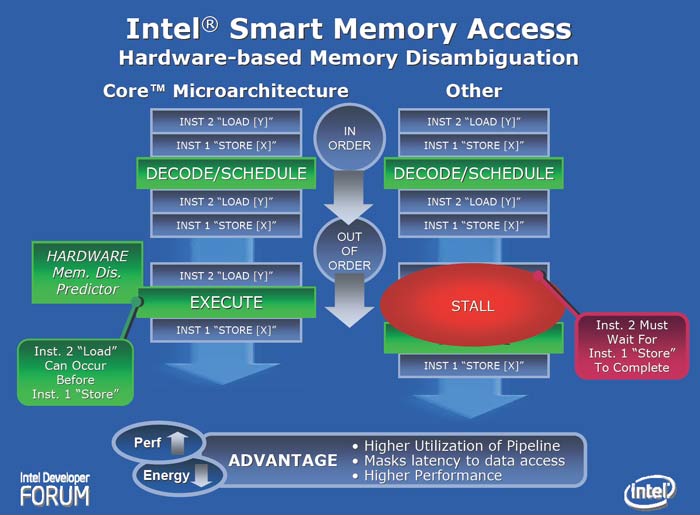
Un problème communément rencontré lors de l'exécution dans le désordre, consiste à déterminer quelles données peuvent être chargées au préalable et non pas au moment ou on en a besoin. C'est ce que l'on qualifie de levée des ambiguités de la mémoire (Memory Disambiguation) qui consiste à déterminer si un load et un store possèdent la même adresse. Cette technique peut amener à une amélioration de 40% sur certains tests.
Sur l'exemple suivant, LOAD Y (instruction 2) ne peut intervenir avant STORE Y (instruction 1) car sinon, la valeur de Y ne sera pas à jour. Par contre, LOAD X (instruction 4) peut être effectuée à n'importe quel moment :
1 STORE Y
2 LOAD Y
3 STORE W
4 LOAD X
5.2.4 Unités d'exécution
L'architecture Core possède 3 ports de répartition qui alimentent :
- 3 unités SSE 128 bits
- 2 unités en virgule flottante de 128 bits
- 3 unités entières de 64 bits
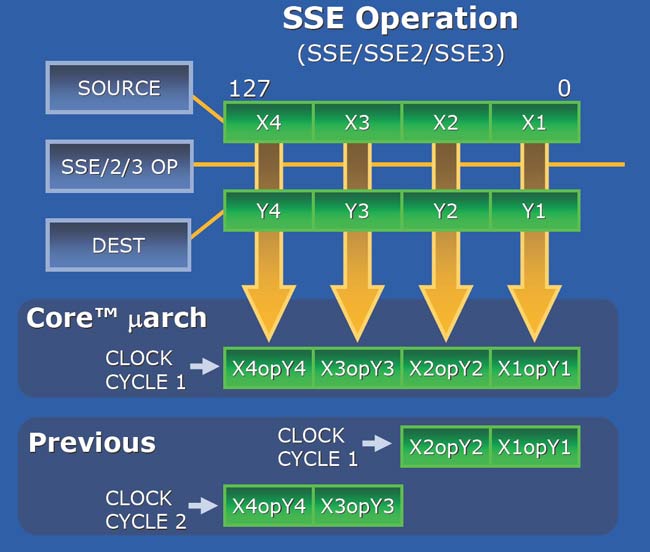
On note donc une augmentation d'UE qui sont en outre mieux organisées. De plus, Core est capable de traiter les opérations SSE 128 bits en 1 seul cycle, alors que Netburst doit s'y prendre à deux fois.
| Instructions par cycle | Netburst | Mobile | Core | K8 |
| x86 (entiers) | 3 | 2 | 3 | 3 |
| SSE (entiers) | 1 8 int × 16 bits |
1 8 int × 16 bits |
3 24 int × 16 bits |
1 8 int × 16 bits |
| x87 (virgule flottante) | 1 | 2 | 2 | 2 |
| SSE (virgule flottante) | 1 2 flt × 64 bits |
1 2 flt × 64 bits |
2 4 flt × 64 bits |
1 2 flt × 64 bits |
Digital Media Boost
En terme de performances, les ALU sont associées à 3 unités SSE de 128 bits capables donc de traiter 3 opérations SSE par cycle, ou 12 instructions sur des entiers 32 bits).
Concernant les deux unités SSE pour les flottants, l'une est consacrée à l'addition et l'autre à la multiplication. On atteint donc un débit d'une addition flottante par cycle.
| CPU | Pentium D 800 | Pentium D 900 | Core 2 Duo | Athlon 64 X2 |
| Finesse de gravure | ? | 65 nm | 65 nm | 90 nm |
| Nombre de transistors | ? | 376 | 291 | 154 |
| Taille du die | ? | 162 mm2 | 143 mm2 | 183 mm2 |
| Taille du cache L2 | 2 × 1 Mo | 2 × 2 Mo | 2 / 4 Mo | 2 × 512 ko |
| Prix | $ 110 | $ 160 | $ 224 à 900 | $ 170 à 400 |
5.2.5 Cache L1 et cache L2 unifié
Le cache L1 est de 64 ko, soit 32 ko pour les instructions (I-Cache) et 32 ko pour les données (D-Cache).
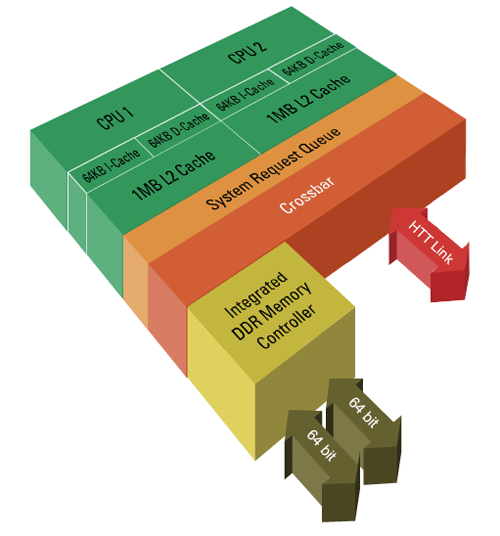
Organisation des caches L2 chez AMD
Comparativement à d'autres architectures (Pentium D, Athlon 64 X2) pour lesquelles chaque coeur possède son propre cache L2, l'architecture Core possède un seul cache L2. Chaque coeur peut donc utiliser une partie ou la presque totalité du cache L2 selon ses besoins.
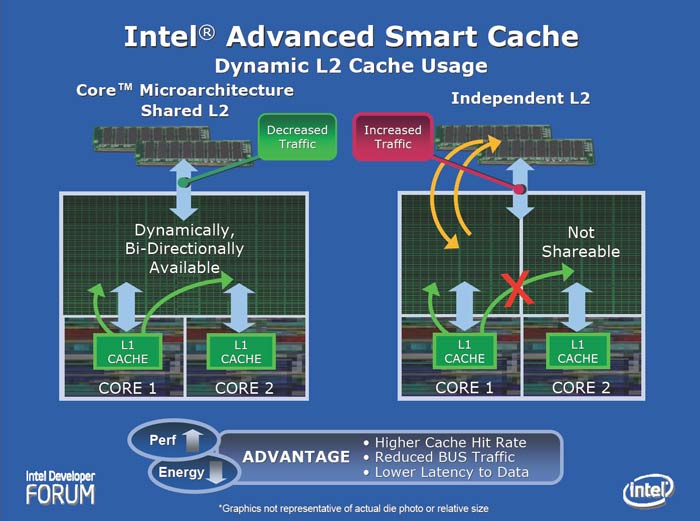
Cette organisation du cache doit permettre une amélioration des performances en évitant à chaque coeur de disposer deux fois de la même donnée et donc d'avoir à la charger deux fois depuis la mémoire.
5.2.6 La gamme
| Modèle | Fréquence | FSB | Cache L2 | Prix | |
| Serveur | 5160 | 3 Ghz | 1333 Mhz | 4 Mo | $851 |
| 5110 | 1,6 Ghz | 1333 Mhz | 4 Mo | $209 | |
| Bureau | X6800 | 2,93 Ghz | 1066 Mhz | 4 Mo | $999 |
| E6700 | 2,66 Ghz | 1066 Mhz | 4 Mo L2 | $530 | |
| E6400 | 2,13 Ghz | 1066 Mhz | 2 Mo L2 | $224 | |
| Portable | T7600 | 2,33 Ghz | 667 Mhz | 4 Mo L2 | $637 |
| T5500 | 1,66 Ghz | 667 Mhz | 2 Mo L2 | $209 | |
5.2.7 Performances
En termes de performances, le Core 2 Duo 6400 se place parfois à la hauteur d'un Athlon 64 FX-62 avec DDR2 800. Voir les dossiers suivants :
- Intel Core 2 Duo (sur Harware.fr)
- Core 2 Extreme vs Athlon 64 FX-62 (sur TomsHardware.com)
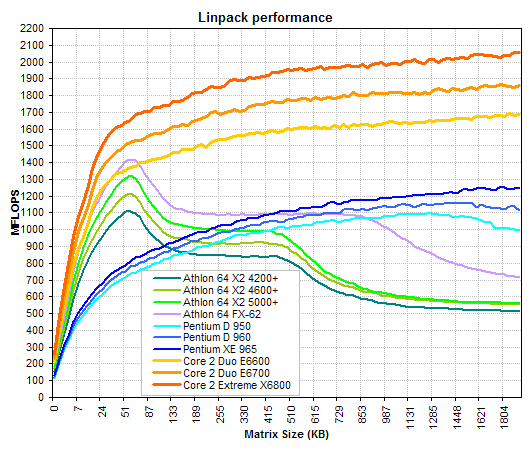
Résultats Linpack (issu de techreport.com)
5.2.8 News
Core 2 Duo : un succès commmercial
Intel annonce 5 millions de puces Core 2 Duo commercialisées dans les soixante jours qui sont suivi leur mise en vente le 27 juillet 2006.
5.3 Penryn, Core 2 en 45nm
5.3.1 Caractéristiques
Penryn est le nom de l'architecture Core 2 en 45nm qui succède à celle en 65nm. Au delà de la diminution de la finesse de gravure, quelques améliorations technologiques font leur apparition :
- augmentation de la fréquence du FSB : 1600 Mhz
- mémoire cache de 6 (X2) à 12 Mo (X4)
- ajout de 47 nouvelles instructions SSE4
- amélioration de la gestion de l'énergie des coeurs
- dynamic acceleration technology pour plateforme mobile
- amélioration de la division (FPU)
- super shuffle engine
- enhanced virtualization technology (25% à 75% d'amélioration)
5.3.2 Technologie 45nm
Depuis les années 60, la grande majorité des transistors des microprocesseurs utilisent la technologie MOSFET (metal–oxide–semiconductor field-effect transistor) utilisant le Silicium et le dioxyde de Silicium comme isolant. Avec l'arrivée de la technologie 45nm, Intel a modifié les couches en bleu et jaune sur la figure suivante :
- en jaune : remplacement du SiO2 par un matériau dit High-k diélectrique basé sur de l'Hafnium, cette couche est responsable de la vitesse de basculement entre source et drain,
- en bleu : la porte du transistor, est remplacée par une couche de métal
![]()
Technologie 45 nm et nouveau diélectrique
Au final, les améliorations apportées concernent :
- amélioration de 20% de la vitesse de basculement des transistors
- le courant de fuite est réduit par un facteur 10, ce courant est responsable de la dissipation thermique
- amélioration de l'overclocking permettant d'atteindre les 4 Ghz
5.3.3 Deep power down technology
Cette technologie concerne la gamme mobile. Les processeurs mobiles sont capables lorsqu'ils sont en veille de diminuer leur tension de fonctionnement, leur fréquence ainsi que de déconnecter une partie de la mémoire cache, ce qui permet de prolonger l'autonomie des batteries.
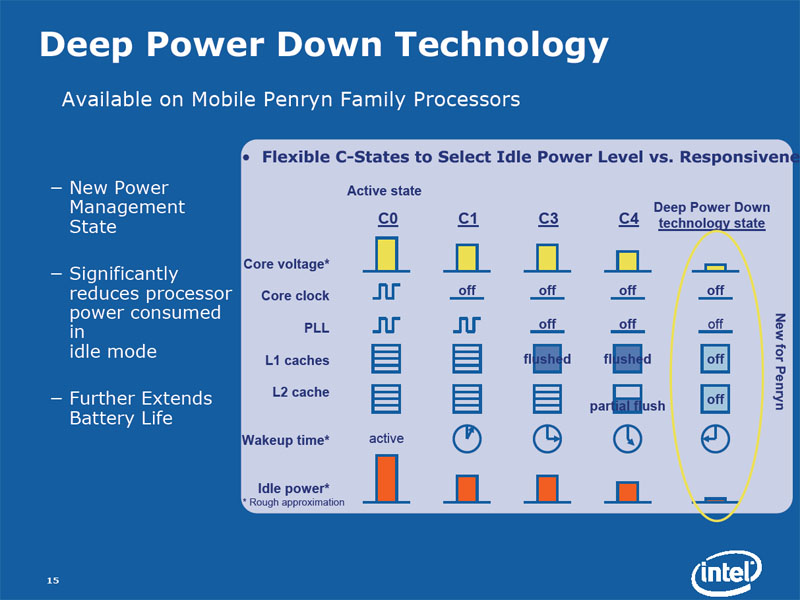
Penryn : Deep Power Down Technology
5.3.4 Enhanced dynamic acceleration technology
Lorsqu'un des coeurs entre dans le mode deep power down, l'autre coeur peut augmenter sa fréquence tout en gardant le dégagement de chaleur dans les limites du TDP (Thermal Dissipation Power).
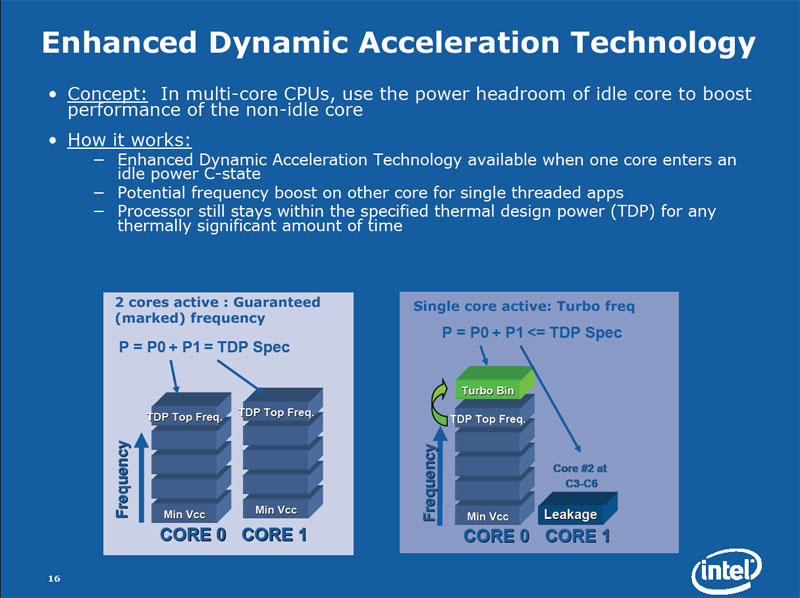
Penryn : Enhanced Dynamic Acceleration Technology
5.3.5 Fast radix-16 divider
Cette amélioration concerne la FPU et la manière dont la division est gérée. Sur l'architecture Core 2, la division traite 2 bits par cycle d'horloge. Avec le Penryn elle est capable d'en traiter 4. La division est donc deux fois plus rapide.
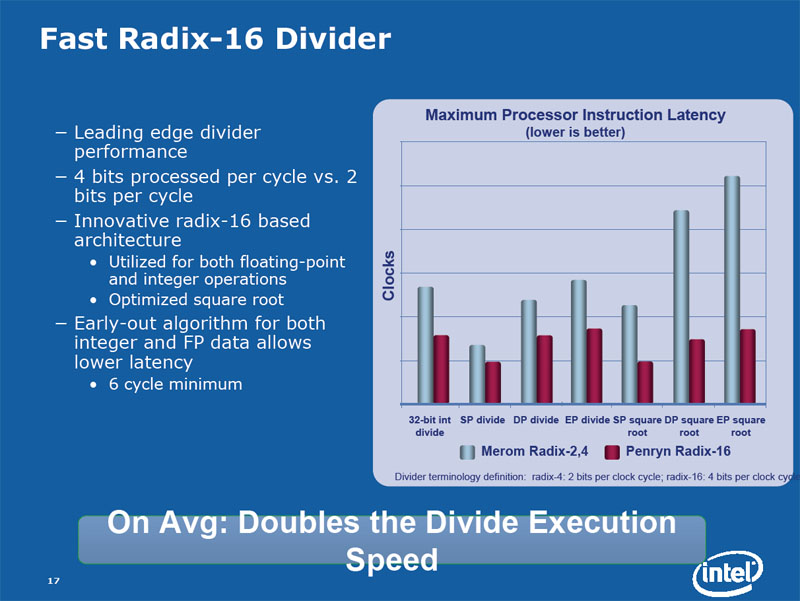
Penryn : Fast Radix-16 Divider
5.3.6 super shuffle engine
Cette amélioration concerne la gestion des instructions SSE, notamment de conversion de format.

Penryn : Super Shuffle Engine
Intel introduit un nouveau jeu d'instruction SSE, dit SSE4.1. Certaines instructions comme MPSADBW permettent de remplacer plusieurs autres instructions. Le site www.tomshardware.com en octobre 2007, a montré que sur un encodage vidéo, l'utilisation du SSE4.1 permet de passer de 4m10s (SSE3) à 2m59.
| Modèle | Architecture | Core | Fréquence | Cache | FSB | Techno |
| Core 2 Extreme QX9650 | Yorkfield | 4 | 2,9 Ghz | 2 × 6 Mo | 333 Mhz | 45 nm |
| Core 2 Extreme QX6850 | Kentsfield | 4 | 3 Ghz | 2 × 4 Mo | 333 Mhz | 65 nm |
| Core 2 Extreme X6800 | Conroe XE | 2 | 2,9 Ghz | 1 × 4 Mo | 266 Mhz | 65 nm |
| Core 2 Extreme E6850 | Conroe | 2 | 3 Ghz | 1 × 4 Mo | 333 Mhz | 65 nm |
| Core 2 E6400 | Conroe-2048 | 2 | 2,1 Ghz | 1 × 2 Mo | 266 Mhz | 65 nm |
| Core 2 E6300 | Allendale | 2 | 1,8 Ghz | 1 × 2 Mo | 266 Mhz | 65 nm |
Liste de prix (novembre 2006) :
- Xeon X5482 (4 core) - 3,2 GHz - 12 Mo - 1,6 GHz - 1279$
- Xeon E5472 (4 core) - 3 GHz - 12 Mo - 1,6 GHz - 1022$
- Xeon X5472 (4 core) - 3 GHz - 12 Mo - 1,6 GHz - 958$
- Xeon E5462 (4 core) - 2,8 GHz - 12 Mo - 1,6 GHz - 797$
- Xeon X5460 (4 core) - 3,16 GHz - 12 Mo - 1,33 GHz - 1172$
- Xeon E5450 (4 core) - 3 GHz - 12 Mo - 1,33 GHz - 915$
- Xeon X5450 (4 core) - 3 GHz - 12 Mo - 1,33 GHz - 851$
- Xeon E5440 (4 core) - 2,83 GHz - 12 Mo - 1,33 GHz - 690$
- Xeon E5430 (4 core) - 2,66 GHz - 12 Mo - 1,33 GHz - 455$
- Xeon E5420 (4 core) - 2,5 GHz - 12 Mo - 1,33 GHz - 316$
- Xeon E5410 (4 core) - 2,33 GHz - 12 Mo - 1,33 GHz - 256$
- Xeon E5405 (4 core) - 2 GHz - 12 Mo - 1,33 GHz - 209$
- Xeon X5272 (2 core) - 3,4 GHz - 6 Mo - 1,6 GHz - 1172$
- Xeon X5260 (2 core) - 3,33 GHz -6 Mo - 1,33 GHz - 851$
- Xeon E5205 (2 core) - 1,86 GHz - 6 Mo - 1,066 GHz - 177$
5.4 Nehalem successeur du Penryn en 2008
5.4.1) prévisions 2007
Intel a déjà révélé quelques détails concernant Nehalem :
- jusqu'à 8 coeurs
- introduction de l'hyperthreading, ce qui doublerait théoriquement le nombre de coeurs
- intégration d'un controlleur vidéo
- intégration du north bridge au niveau du die du cpu comme chez AMD
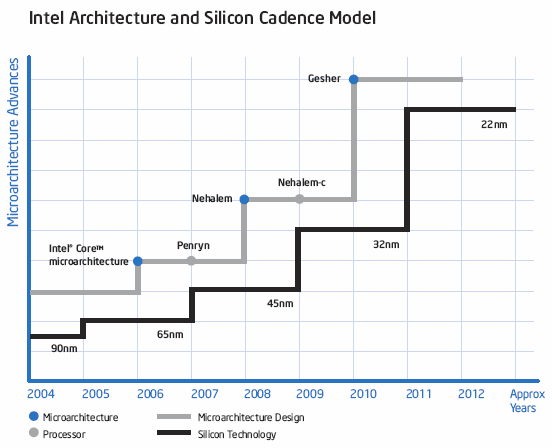
Prévisions Intel 2007
5.4.2) Novembre 2008, sortie du Nehalem

Plusieurs dossiers concernant le Nehalem, rebaptisé Core i7 par Intel, sont apparus lors de la sortie de ce nouveau processeur :
Parmi les changements notables par rapport à l'architecture Core 2, on note :
- 4 coeurs dotés de l'hyper-threading (ou SMT)
- un bus d'interconnexion rapide QPI (Quick Path Interconnect)
- un cache L3 (8 Mo)
- contrôleur mémoire intégré capable de gérer 3 canaux de DDR3
| Nom | Coeurs | Fréquence | Cache L3 | QPI | Prix |
| Intel Core i7 920 | 4 | 2.66 Ghz | 8 Mo | 4.8 GT/s | 260 € |
| Intel Core i7 940 | 4 | 2.93 Ghz | 8 Mo | 4.8 GT/s | 510 € |
| Intel Core i7 965 | 4 | 3.20 Ghz | 8 Mo | 6.4 GT/s | 1000 € |
5.4.3) Core et Uncore
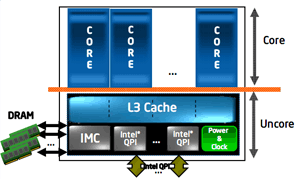
5.5 L'architecture AMD K10
K10 est le nom de l'architecture des nouveaux processeurs AMD apparus en septembre 2007. Phenom et Opteron sont basés sur le coeur Barcelona. K10 est basée sur K8 l'architecture des Athlon 64.
- la version serveur du K10 est l'Opteron Quad Core (Barcelona), gravure 65 nm, SOI, Socket F (LGA 1207), 3 liens HT 1.0, die de 283mm2, 563 millions de transistors, 11 couches d'interconnexions en cuivre
- la version desktop Quad Core est baptisée Phenom X4 (Agena), gravure 65 nm, SOI, Socket AM2+ (PGA 940), 1 lien HT 3.0, support DDR2-1066 (arrivée prévue décembre 2007)
- la version desktop Dual Core est le Phenom X2 (Kuma) et possède un cache L3 de 2 Mo
- on trouve également :
- le Phenom X2 (Rana) sans cache L3
- le Sempron (Spica) : un seul coeur, pas de cache L3

L'ensemble des améliorations introduites par le K10 est résumé sur le schéma suivant :

Améliorations du K10 / K8
5.5.1 Amélioration de l'IPC (Instruction Level Parallelism)
Le K10 offre la même puissance théorique que l'architecture Core 2, soit :
| Type de données | Core2/AMD K10 |
| int x86 | 3 |
| x87 | 2 |
| SSE int (16 bits) | 24 (3 × 8) |
| SSE simple précision (32 bits) | 8 |
| SSE double précision (64 bits) | 4 |
Afin de soutenir le débit de l'IPC :
- on obtient 32 octets (256 bits) d'instructions depuis le cache L1 (comme pour le Core 2 Duo), alors qu'on en obtenait 16 sur le K8
- utilisation d'un canal interne de 128 bits alors qu'il était de 64 bits sur le K8 : les instructions SSE ne sont donc plus scindées en 2.
5.5.2 Sidebank stack optimizer
Lors de l'appel d'un sous-programme on utilise les instructions PUSH, POP, CALL, RET. Toutes ces instructions font appel à la pile et vont créer des dépendances :
| instructions | comportement |
push Z push Y push X call func |
sub esp,4 ; mov [esp],Z sub esp,4 ; mov [esp],Y sub esp,4 ; mov [esp],X sub esp,4 ; mov [esp],eip ; jmp func |
push ebp mov ebp,esp push esi mov eax,[ebp+8] ... pop esi mov esp,ebp pop ebp ret |
sub esp,4 ; mov [esp],ebp mov esp,ebp sub esp,4 ; mov [esp],esi mov eax,[ebp+8] = [esp+12] ... mov esi,[esp-4] ; add esp,4 mov esp,ebp mov ebp,[esp-4] ; add esp,4 jmp [esp]; add esp,4 |
Afin d'optimiser l'accès à la pile, on ne décrémente pas toujours le sommet de pile, et parfois on utilise un mécanisme de synchronisation pour mettre à jour le sommet de la pile :
| instructions | comportement |
push Z push Y push X call func |
mov [esp-4],Z mov [esp-8],Y mov [esp-12],X mov [esp-16],eip ; jmp func |
push ebp mov ebp,esp push esi mov eax,[ebp+8] ... pop esi mov esp,ebp pop ebp ret |
sub esp,4 ; mov [esp],ebp mov esp,ebp sub esp,4 ; mov [esp],esi mov eax,[ebp+8] = [esp+12] ... mov esi,[esp-4] ; add esp,4 mov esp,ebp mov ebp,[esp-4] ; add esp,4 jmp [esp]; add esp,4 |
5.5.3 L3 memory cache
Le cache L3 a pour but d'assurer la performance des 4 coeurs lorsqu'ils travaillent ensemble.
| Cache | AMD K10 | Intel Core 2 Quad |
| L1 |
|
|
| L2 |
|
|
| L3 |
|
aucun |
Core 1 |
Core 2 |
Core 3 |
Core 4 |
|||
| L1 | L1 | L1 | L1 | |||
L2 |
L2 | L2 | L2 | |||
L3 |
||||||
| System Request Interface Crossbar Switch |
||||||
| Memory Controllers (2 × 64bits @ 667 Mhz) |
Hyper Transport 3.0 (8 × 16bits @ 2Ghz) |
|||||
Les latences des caches sont les suivantes :
- L1 : 3 cycles
- L2 : 15 cycles
- L3 : 30 à 45 cycles
5.5.4 Independent memory controller
La technologie Dual-Channel, bien qu'elle permette de traiter 128 bits, fonctionne en chargeant des données contigües. La technologie un-ganged du K10 permet d'accèder aux données situées à des données situées à des adresses indépendantes.
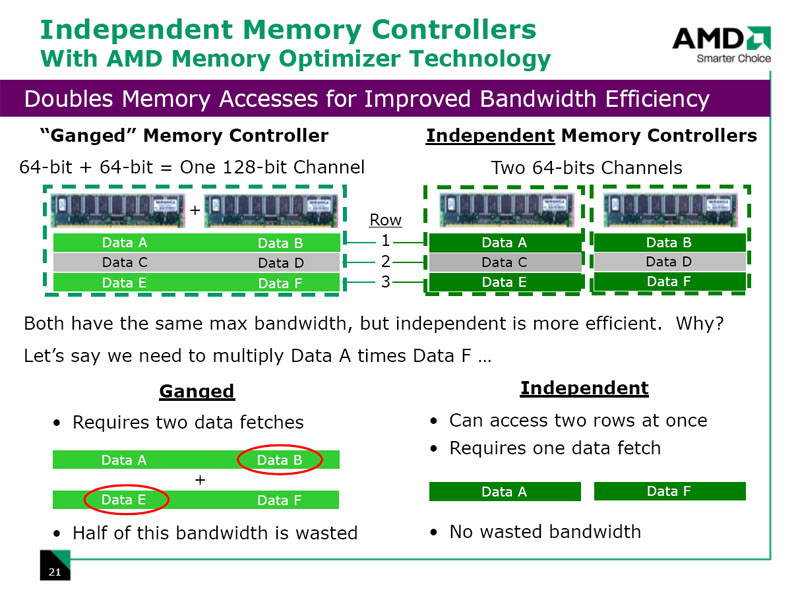
K10 : contrôleur mémoire indépendant
5.5.5 Gestion de l'énergie
La technologie CoolCore permet d'éteindre un core qui n'est pas utilisé indépendamment de l'autre.
la technologie dual dynamic power management permet de séparer la tension d'alimentation du coeur de celle du contrôleur mémoire.
5.5.7 Hypertransport 3.0
On rappelle que chez AMD, le contrôleur mémoire est intégré au niveau du CPU. Le bus hypertransport fait le lien entre la carte graphique et le south bridge.
Le bus hypertransport passera en version 3.0 et permettra de transférer 10400 Mo/s au lieu des 4000 Mo/s du K8. Le bus hypertransport peut également faire varier sa fréquence ainsi que sa largeur.
5.5.8 Architectures
gamme serveurs :
- Barcelona : X2 ou X4 et Opteron 2000 to 8000 avec 512 Ko de L2 et 2 Mo de L3, 65 nm, Socket 1207 (F), HyperTransport 1.x
- Shanghai : X2 ou X4 et Opteron 2000 to 8000 avec 512 Ko de L2 et 6 Mo de L3, 45 nm, Socket 1207 (F), HyperTransport 1.x
- Montréal : X4 ou X8 Opteron 2000 to 8000 avec 1 Mo de L2 et 12 Mo de L3, 45 nm, Socket 1207 (F), HyperTransport 1.x
- Suzuka : X4 ou X8 Opteron 2000 to 8000 avec 1 Mo de L2 et 12 Mo de L3, 45 nm, Socket 1207 (F), HyperTransport 1.x
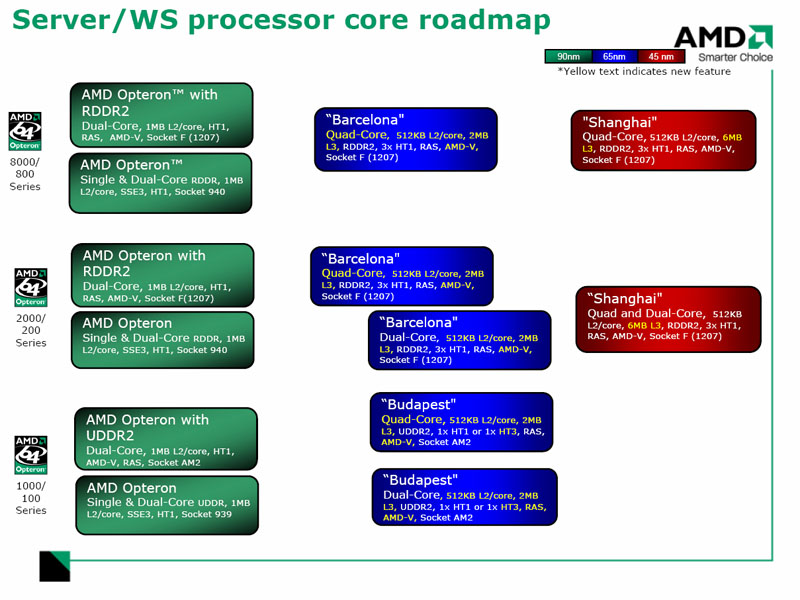
K10 : feuille de route (roadmap) des serveurs
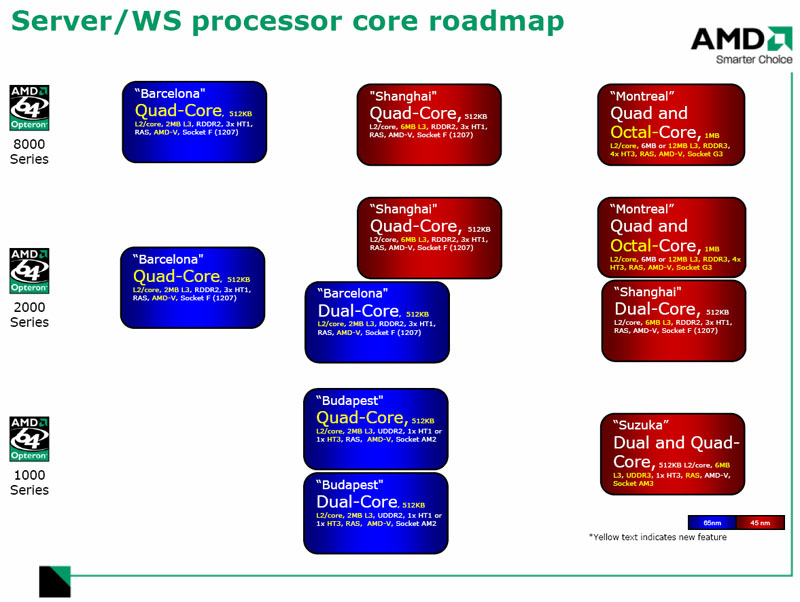
K10 : feuille de route (roadmap) des serveurs (page 2)
Note : lors de leur sortie en novembre 2007, un malentendu a laissé croire à la presse européenne que les tarifs de lancement des Phenom seraient plutôt attractifs :
- Phenom 9600 : 190 euros
- Phenom 9500 : 169 euros
mais il s'agissait de prix hors taxe pour l'achat de 1000 processeurs. Le prix public était au final de l'ordre de :
- Phenom 9600 : 260 euros
- Phenom 9500 : 230 euros
L'achat d'un Phenom devenait donc très peu rentable car les différents tests réalisés par les sites spécialisés montrèrent que le Phenom 9600 (@ 2,3 Ghz) était moins performant qu'un Core 2 Quad 6600 qui coûtait dans les 230 euros. Ce manque de performance peut être expliqué en partie par la faible taille du cache L2 (512 ko) ainsi que celle du cache L3 (2 Mo) ainsi que par une fréquence trop faible (2,3 Ghz).
pour approfondir
- AMD K10 @ Real World Technologies
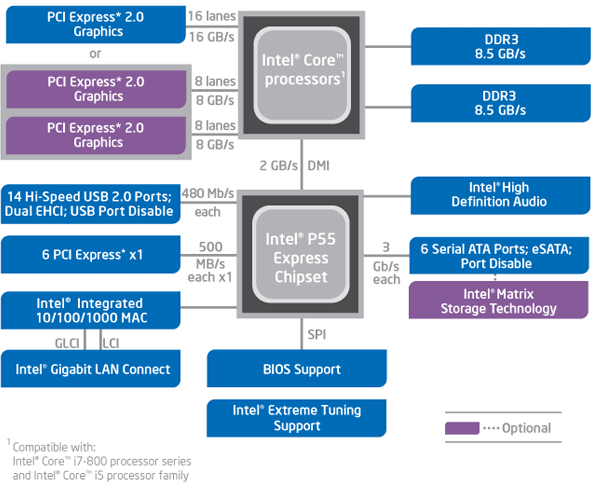
5.6 Intel Lynnfield (Core i5,i7) - 2009
Apparue en septembre 2009, cette architecture a pour but de remplacer les Core 2 Duo/Quad et autres Pentium qui utilisent le socket 775. Les Lynnfield qui sont des Quad Core natifs utilisent le socket 1156 et le chipset P55 et sont dérivés de l'architecture Nehalem apparue avec le Core i7 900 Bloomfield. Les trois premiers processeurs de la gamme sont :
- Core i5 750 - 4 Cores - 2.66 Ghz - 4x256 ko L2 - 8 Mo L3 - $199 / 1000
- Core i7 860 - 4 Cores + HT - 2.80 Ghz - 4x256 ko L2 - 8 Mo L3 - $285 / 1000
- Core i7 870 - 4 Cores + HT - 2.93 Ghz - 4x256 ko L2 - 8 Mo L3 - $555 / 1000
Parmi les caractèristiques notables des Lynnfield on peut noter :
- gestion DD3-1333 en double canal
- mode Turbo Boost amélioré
- Hyperthreading pour les Core i7 (8 threads)
5.6.1 le mode turbo
5.6.2 core et uncore
Les processeurs Lynnfield/Bloomfield sont désormais conçus sous la forme core/uncore :
- core : coeur du processeur + cache L1 + cache L2
- uncore : contrôleur PCIe + contrôleur mémoire + DMI/QPI + cache L3
La partie uncore composée de millions de transistors (400 millions pour le Lynnfield) n'est pas assujetie aux performances. Intel utilise pour cette partie des transistors moins rapides qui possèdent moins de fuites de courant
Fatal error: Uncaught Error: Call to undefined function document_txt_navigate() in /home/jeanmichel.richer/public_html/ensl3i_crs5.php:1131 Stack trace: #0 {main} thrown in /home/jeanmichel.richer/public_html/ensl3i_crs5.php on line 1131