Sommaire
- Chapitre 1 : Notions fondamentales
- Chapitre 2 : Architecture d'un ordinateur
- Chapitre 3 : Microprocesseur
- Chapitre 4 : Mémoires
- Chapitre 5 : L'architecture Core
- Chapitre 6 : Optimisation : au coeur du core
- Bibliographie
1. Notions fondamentales
Thomas WATSON, président d'IBM, 1943.
1.1. Préambule
1.1.1. La révolution informatique
En 2010, l'ordinateur n'a que 65 années d'existence derrière lui. L'âge de la retraite me direz vous ? Eh bien, non. L'ordinateur a encore de beaux jours devant lui et de nombreux progrès et améliorations à venir qui le rendront plus performant et peut être, un jour, pourrons nous le qualifier d'"intelligent", ce qui n'est actuellement pas le cas.
Les ordinateurs ont bouleversé nos modes de vie les rendant plus stressants (vitesse de calcul, réponse rapide) mais ont également permis de simplifier nombre de traitements réalisés manuellement par le passé (statistiques).
Il semble difficile de comparer les premiers calculateurs à nos ordinateurs actuels, cependant nous ne pouvons que nous étonner des progrès réalisés en un temps record.
| Caractéristiques | ENIAC | Ordinateur de bureau | facteur |
| Année | 1945 | 2010 | +65 ans |
| poids | 50 tonnes | 20 kg | / 2500 |
| consommation électrique | 25 kW | 500 à 1000 W | / 25-50 |
| capacité mémoire | < 1 ko | Go | x 1.000.000 |
| performances (instructions / s) | quelques centaines | 100 millions | x 1.000.000 |
Aujourd'hui (Juin 2016) le super ordinateur le plus puissant (voir le site top500.org) Sunway TaihuLight (Chine) est capable d'atteindre 93 Petaflops ($10^{15}$) avec 10,649,600 coeurs. La prochaine barrière à atteindre étant celle de l'Exaflops ($10^{18}$).
On notera néanmoins qu'il s'agit de la puissance cumulée de tous les processeurs utilisés (voir le lien Présence PC: 17 ans d'évolution des supercalculateurs)
Intel travaille actuellement sur le Teraflop Chip : ASCI Red fut le premier système à atteindre le TeraFlop en 1996. Il était composé de 10.000 Intel Pentium Pro tournant à 200 Mhz et consommait 500.000 W (ainsi que 500.000 W de plus pour le système de climatisation refroidissant l'ensemble des machines). Avec le TeraFlop chip, Intel serait capable de créer un microprocesseur de même puissance (1,01 TeraFlop) dissipant seulement 62 W (cf Knighs Corner, Knights Landing).
Exemple : 2010 le TERA 100 du CEA construit par BULL pour la simulation d'armes nucléaires
- occupe 600 m2
- 4370 serveurs Bullx soit 17480 Octo-core Intel Xeon 7500, soit une puissance de 1 PFlops
- 300 To de mémoire RAM
- 20 Po de stockage disque
- RedHat, Lustre (système de fichiers)
Actuellement (2016) ATOS/BULL est l'un des trois ou quatre acteurs mondiaux à savoir concevoir et fabriquer aujourd'hui des supercalculateurs, et le seul européen selon Thierry Breton (PDG d'ATOS/BULL, ancien ministre de l'économie). BULL a conçu le SEQUANA une brique de super-calculateur qui consomme 10 fois moins d'énergie que les machines actuelles, occupe 5$m^2$ au sol et pèse 9 tonnes. Cette brique comprend par exemple dans sa version X1210 24 lames x 3 noeuds soit 72 noeuds capables d'accueillir chacun un Intel Xeon Knights Landing (72 coeurs Atom avec 4 threads + AVX 512), soit un total de 72 x 72 = 5184 coeurs, 6 TeraFlops en simple précision et 3 en double précision.
1.1.2. Besoins en puissance de calcul
Top500 : les calculateurs les plus puissants, dont le K computer avec 10,5 PFlops en 2012.
Les super-calculateurs sont utilisés par les très grandes entreprises et instituts de recherches, pour effectuer rapidement des simulations informatiques qui peuvent éventuellement générer des volumes de données gigantesques.
Les agences de prévisions météorologiques, les centres d'études aérospatiales, les organismes de recherches géologiques et sismologiques figurent parmi les principaux utilisateurs de ces imposantes machines.
Les super-calculateurs remplissent des salles immenses et exigent des batteries de climatiseurs tant ils dégagent de chaleur. Il est a noté que leur consommation électrique est également très importante.
Mars 2007 - Des scientifiques de l'université de CHICAGO en Astrophysique thermonucléaire ont réussi très récemment à modéliser une supernova ... chose qu'il était pourtant pensé impossible à réaliser vu la complexité des calculs. Ainsi, pour pouvoir observer 3 secondes de l'explosion, il a fallu des heures de programmation, et surtout 700 processeurs travaillant sans relâche pendant 58 000 heures pour obtenir ces 3 secondes.
Octobre 2007 - Le groupe d'électronique, d'équipements de télécommunications et d'informatique japonais NEC a annoncé le lancement d'un super-calculateur dont les performances sont à ce jour inégalées, selon son concepteur. Cet ordinateur baptisé SX-9 est présenté comme le super-ordinateur vectoriel le plus puissant du moment, avec une puissance crête de calcul de 839 Teraflops, grâce à des unités centrales de calcul (CPU) chacune capable d'atteindre un niveau de 102 Gigaflops, ce qui est une première, selon NEC.
NEC dit avoir mis en oeuvre dans ce nouveau modèle divers procédés qui permettent de diminuer la surchauffe et d'améliorer la ventilation de sorte que leur encombrement et leur consommation d'électricité s'en trouve réduite.
Le groupe nippon revendique actuellement plus de 1000 supercalculateurs portant sa marque "SX" en service dans le monde.
Cracker un mot de passe
Les progrès réalisés au niveau des CPU ont eu des incidences sur les GPU. Cracker un mot de passe codé en MD5 devient un jeu d'enfant en utilisant une carte graphique.
1.1.3. Pourquoi un cours d'architecture des ordinateurs ?
Dans le cursus d'un étudiant en informatique, un cours d'architecture est fondamental car il permet d'apporter les connaissances liées au matériel. Si on considère que l'essentiel de notre travail d'informaticien touche au logiciel (software), c'est à dire la production d'algorithmes, on oublie souvent que le matériel (hardware) joue un rôle important vis à vis des performances, de la compatibilité et de la portabilité des logiciels.
Dans ce cours, on abordera certains aspects matériels, mais on se focalisera plus particulièrement sur l'apprentissage de l'assembleur, c'est à dire, pour faire court, le langage exécuté par le processeur.
Un autre aspect important est que le domaine de l'architecture des ordinateurs est intimement liée à celui de l'industrie des semi-conducteurs qui est un marché de plusieurs milliards de dollars et qui concerne des sociétés comme Intel, AMD, IBM, Samsung, Texas Instruments, ...
| Rang 2010 | Rang 2009 | Sociétés | Chiffre d'affaire 2010 |
Part de marché 2010 |
Croissance 2010-2009 |
| 1 | 1 | Intel | 41,988 | 14% | 25,6% |
| 2 | 2 | Samsung Electronics | 28,097 | 9,4% | 58,3% |
| 3 | 3 | Toshiba | 12,360 | 4,1% | 28,7% |
| 4 | 4 | Texas Instruments | 11,878 | 4% | 29,9% |
| 5 | 5 | STMicroelectronics | 10,346 | 3,5% | 22,3% |
| 6 | 11 | Renesas Electronics | 10,204 | 3,4% | 124,7% |
| 7 | 7 | Hynix Semiconductor | 9,884 | 3,3% | 63,8% |
| 8 | 13 | Micron Technology | 8,224 | 2,7% | 97,2% |
| 9 | 6 | Qualcomm | 7,204 | 2,4% | 12,4% |
| 10 | 12 | Broadcom | 6,604 | 2,2% | 53% |
| Autres | 152,574 | 51% | 22,2% | ||
| Total | 299,363 | 100% | 30,9% |
On note que les principales entreprises sont américaines, japonaises et sud coréennes. En Europe, les deux grands noms de l'industrie des semi-conducteurs sont STMicroelectronics et Infineon.
1.1.4. A quoi cela me sert-il de savoir programmer en assembleur ?
Dans la grande majorité des cas, savoir programmer en assembleur ne sert strictement à rien :
- d'une part, les langages destinés au web (PHP, Javascript, Python) sont des langages interprétés, ou l'assembleur n'est pas utilisé, si ce n'est par l'interpréteur
- d'autre part, les langages compilés (C, C++, Pascal, Modula, Fortran, ...) le compilateur est généralement capable de produire un code assembleur bien plus optimisé que celui écrit à la main :
- options de compilation -O2 ou -O3 pour g++/icpc,
- PGO (Profile-Guided Optimization),
- auto vectorization
- auto parallélisation
Quels sont les inconvénients de la programmation en assembleur ?
- la principale difficulté réside dans l'absence de structure de langage de haut niveau (if, for, while, ...), on est donc contraint d'écrire dans un langage bas niveau, ce qui rend la relecture et la compréhension du code difficile
- en outre, comme nous le verrons plus tard, le fait de disposer finalement de 6 registres généraux (EAX, EBX, ECX, EDX, ESI, EDI) pour réaliser les traitements (ESP et EBP étant utilisés pour gérer la pile), il faut constamment jongler entre les registres : tel registre va contenir telle donnée au début d'un sous-programme, puis telle autre donnée en fin du même sous-programme
Donc finalement, programmer en assembleur cela ne sert à rien ?
Non car :
- connaissance de l'outil de travail : connaître l'assembleur permet de savoir comment fonctionne le processeur, ce qu'il est capable de réaliser : comment il traite les données, comment il interagit avec la mémoire (cf alignement).
On pensera également au fait que le processeur est un système complexe qui combine plusieurs technologies est c'est la synergie de ces technologies que provient l'efficacité de l'exécution du code (cf document Intel) :
- pipelining : décomposition de l'exécution d'une instruction en plusieurs étapes
- branch prediction : déterminer si un test produira un branchement à telle adresse mémoire
- exécution dans le désordre (Out-Of-Order)
- unité vectorielles : MMX, SIMD
- mémoires caches
- optimisation du code :
- vous apprendrez des notions liées à l'optimisation du code (dépliage de boucle, vectorisation) car tout informaticien se doit de produire du code conforme (c'est à dire qui réalise le traitement demandé) et efficace (qui le fait de la manière la plus rapide possible) : cela peut avoir une influence non négligeable sur votre carrière
- de plus, certains traitements sont difficilement traduisibles de manière optimale par le compilateur. Cela arrive rarement, mais dans certains cas, cela se révèle un atout primordial et permet de faire la différence
- certaines instructions assembleur n'ont pas d'équivalent en langage de haut niveau (on verra BSR, BSF, POPCNT) or les coder par une fonction dans un langage de haut niveau aboutit à des traitements qui prendront plus de temps à s'exécuter
- être rigoureux : programmer en assembleur apprend à être rigoureux car il est nécessaire avant toute chose de spécifier ce que stockeront les registres, comment on va manipuler les données, comment on va les traiter. On retrouve la même necessité de rigueur lorsque l'on programme avec des langages de haut niveau lorsque l'on manipule plusieurs concepts simultanément
- obligatoire lorsque lié au matériel : la programmation des drivers de périphériques passe généralement par une partie assembleur qui réalise l'interface avec le système d'exploitation
Pour résumer
Un système informatique se compose :
- d'une partie matérielle (hardware) qui représente l'ensemble des composants de la machine,
- d'une parite logicielle (software) constituée des logiciels s'exécutant sur le matériel
Un informaticien se doit de comprendre le fonctionnement du système dans sa globalité car les caractéristiques du matériel influent sur les performances des programmes. Toute personne prétendant être un informaticien sans savoir coder n'est pas un informaticien, c'est un théoricien.
Une bonne connaissance du fonctionnement interne de l'ordinateur permet de comprendre pourquoi certains algorithmes se révèlent efficaces et pourquoi d'autres sont mal adaptés, par rapport à une architecture donnée, et comment en améliorer le fonctionnement.
En effet les traitements informatiques possèdent, au regard de ceux qui les utilisent, une exigence de qualité (robustesse et performance) et l'informatique s'attache à résoudre des problèmes complexes par leur structure ou par le volume de données à gérer. L'informaticien doit donc être capable de trouver le traitement (algorithme) le plus adapté aux données à analyser et savoir coder correctement cet algorithme dans un langage donné (exemple : liste, ajout en fin de liste récursif).
1.2. Le métier d'informaticien
1.2.1. Qu'est ce qu'un ordinateur ?
Définition : Ordinateur
Un ordinateur est une machine électronique conçue pour effectuer des calculs et traiter des informations de manière automatique.
Le terme ordinateur a été inventé par Jacques Perret, professeur de philologie latine à la Sorbonne, à la demande d'IBM France en 1955. IBM cherchait en effet à cette époque un nom pour son nouveau calculateur, qui fut alors baptisé : ordinateur IBM 650.
Un ordinateur est composé de plusieurs parties appelées :
- composants (carte mère, microprocesseur, barrette de mémoire, carte graphique)
- et périphériques (disque dur, lecteur de DVD, clavier, souris, moniteur, ...).
La distinction entre composant et périphérique repose sur le fait qu'un périphérique se trouve éloigné de la carte mère alors qu'un composant est en contact direct avec celle-ci. Cependant le terme composant peut être utilisé pour englober les périphériques.
Pour certains, le terme périphériques fait plutôt référence à tout ce qui est externe au boitier : clavier, souris, moniteur, imprimante... ce qui se trouve à la périphérie.
1.2.2. Qu'est ce que l'informatique ?
Définition : Informatique*
Science de la recherche et du traitement de l'information effectué par un ordinateur. Elle comprend l'ensemble des activités consistant à collecter, organiser et traiter de manière automatique les données par un ordinateur.
Le terme informatique a été créé en mars 1962 par Philippe Dreyfus (Directeur du centre national de calcul électronique de la société Bull dans les années 1950, un des pionniers de l'informatique en France) à partir des mots information et automatique.
En anglais on trouve parfois le terme informatics, mais plus généralement on emploie le terme Computer Science, voire Computer Engineering.
On notera la différence établie entre computer, c'est à dire la tâche première pour laquelle les ordinateurs furent utilisés, et le mot informatique, c'est à dire, leur utilisation au quotidien : le traitement automatique de l'information.
1.2.3. Qu'est ce qu'un informaticien ?
Définition : Informaticien
Un informaticien est un scientifique qui met en place des procédures de traitement automatique de l'information grâce à un ordinateur tout en exploitant au mieux les capacités de la machine.
1.2.3.a En quoi consiste son travail ?
Le travail de l'informaticien consiste, partant d'énoncés en langage naturel (la langue de la vie courante), à traduire ces énoncés en une série d'opérations clairement définies que l'on appelle algorithme. Ces algorithmes sont ensuite traduits en instructions directement compréhensibles par le microprocesseur de la machine.
Définition : Algorithme
Un algorithme est une succession finie d'actions clairement identifiées exécutées dans un ordre précis.
Le mot algorithme est dérivé du nom du mathématicien persan Al Khwarizmi (vers l'an 820), qui introduisit en Occident la numération décimale (rapportée d'Inde) et enseigna les règles élémentaires des calculs qui en découlaient.
Les exemples qui suivent sont liés à l'aspect algorithmique du métier d'informaticien.
1.2.3.b Exemple 1
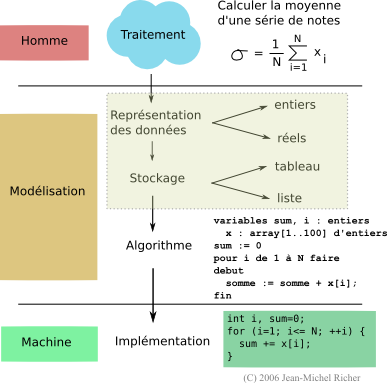
Le processus de programmation passe par différentes phases :
- analyse du problème : que dois-je réaliser et comment ?
- modélisation : comment représenter les données et comment les traiter (algorithme) pour obtenir le résultat escompté
- codage (implémentation) : traduire l'algorithme dans un langage donné (dans le cas du C on pourra optimiser le code par vectorisation)
1.2.3.c Exemple 2 : crible d'Ératosthène
Le crible d'Ératosthène est un procédé qui permet de trouver tous les nombres premiers inférieurs à un certain entier naturel donné $N$. On compare deux méthodes :
- méthode 1 : utilisation d'une fonction is_prime qui vérifie si chaque nombre est premier ou non
- méthode 2 : amélioration de la fonction is_prime
- méthode 3 : crible
- CODE
- crible.cpp
- // ==================================================================
- // Author: Jean-Michel RICHER
- // email: jean-michel.richer@univ-angers.fr
- // find prime numbers in interval [1..100,000,000]
- // using:
- // - method 1 : function is_prime for each number
- // - method 2 : improved version of method_1
- // * i = i + 2
- // - method 3 : sieve of Eratosthenes (Crible d'Ératosthène)
- //
- // compile with
- // g++ -o crible.exe crible.cpp -std=c++11 -lm -O2
- //
- // ==================================================================
- // Intel(R) Core(TM) i5-4570 CPU @ 3.20GHz
- // n = 5761455
- // method 1: 2m0.530s => 120 s | -98% x67.37
- // method 2: 1m0.589s => 60s | -97% x33.68
- // method 3: 1.781s
- // ==================================================================
- #include <iostream>
- #include <vector>
- #include <cmath>
- #include <cstdlib>
- #include <algorithm>
- using namespace std;
- const int SIZE = 100000000;
- bool *tab;
- bool is_prime_1(int n) {
- if (n <= 1) return false;
- if (n == 2) return true;
- int limit = static_cast<int>(floor(sqrt(n)));
- for (int k = 2; k <= limit; ++k) {
- if ((n % k) == 0) return false;
- }
- return true;
- }
- /**
- * check if each number is prime using function
- * is_prime_1()
- */
- void method_1() {
- tab[0] = false;
- tab[1] = false;
- int i = 2;
- while (i < SIZE) {
- tab[i] = is_prime_1(i);
- ++i;
- }
- }
- /**
- * is_prime_2() is an improvement of is_prime_1
- */
- bool is_prime_2(int n) {
- if (n <= 1) return false;
- if (n <= 3) return true;
- // check if even number
- if ((n % 2) == 0) return false;
- int limit = static_cast<int>(floor(sqrt(n)));
- // don't test even numbers because already done
- // with ((n % 2)==0)
- for (int k = 3; k <= limit; k += 2) {
- if ((n % k) == 0) return false;
- }
- return true;
- }
- /**
- * check if each number is prime using function
- * is_prime_2()
- */
- void method_2() {
- tab[2] = true;
- int i = 3;
- while (i < SIZE) {
- if (is_prime_2(i)) {
- tab[i] = true;
- // !!! work only if 2 is already in v
- // and start with i=3
- ++i;
- }
- ++i;
- }
- }
- /**
- * cribble
- */
- void method_3() {
- tab[0] = false;
- tab[1] = false;
- int i = 2;
- while (i < SIZE) {
- if (tab[i]) {
- for (int j = 2*i; j < SIZE; j+=i) {
- tab[j] = false;
- }
- }
- ++i;
- }
- }
- /**
- * main function
- */
- int main(int argc, char *argv[]) {
- tab = new bool[ SIZE ];
- // default method
- int method = 1;
- if (argc > 1) {
- method = atoi(argv[1]);
- if ((method < 1) || (method > 3)) {
- method = 1;
- }
- }
- switch(method) {
- case 1:
- method_1();
- break;
- case 2:
- fill(&tab[0], &tab[SIZE], false);
- method_2();
- break;
- case 3:
- fill(&tab[0], &tab[SIZE], true);
- method_3();
- break;
- }
- int n = 0;
- for (int i=0; i<SIZE; ++i) {
- if (tab[i]) {
- //cout << i << " ";
- ++n;
- }
- }
- cout << endl << "n=" << n << endl;
- return EXIT_SUCCESS;
- }
Voici quelques résultats :
| méthode | résultat | amélioration | facteur |
| méthode 1 | 2m0.530s | - | - |
| méthode 2 | 1m0.589s | 50% | x2 |
| méthode 3 | 1.781s | 98% | x67.37 |
1.2.3.d Exemple 3 : impôts
| if you are single and if the taxable income is over |
but not over | the tax is | of the amount over |
| 0 | 21,450 | 15% | 0 |
| 21,450 | 51,900 | 3,217 + 28% | 21,450 |
| 51,900 | 11,743 + 31% | 51,900 |
| if you are married and if the taxable income is over |
but not over | the tax is | of the amount over |
| 0 | 35,800 | 15% | 0 |
| 35,800 | 86,500 | 5,370 + 28% | 35,800 |
| 86,500 | 19,566 + 31% | 86,500 |
Voici une première solution :
- CODE
- implantation 1
- #include <iostream>
- #include <cstdlib>
- #include <cmath>
- using namespace std;
- const double SINGLE_LEVEL1 = 21450.0;
- const double SINGLE_LEVEL2 = 51900.0;
- const double SINGLE_TAX1 = 3217.0;
- const double SINGLE_TAX2 = 11743.0;
- const double MARRIED_LEVEL1 = 35800.0;
- const double MARRIED_LEVEL2 = 86500.0;
- const double MARRIED_TAX1 = 5370.0;
- const double MARRIED_TAX2 = 19566.0;
- const double RATE1 = 0.15;
- const double RATE2 = 0.28;
- const double RATE3 = 0.31;
- double tax_amount(double income, bool married) {
- double tax;
- if (!married) {
- // single
- if (income <= SINGLE_LEVEL1) {
- tax = income * RATE1;
- } else if (income <= SINGLE_LEVEL2) {
- tax = SINGLE_TAX1 + RATE2 * (income - SINGLE_LEVEL1);
- } else {
- tax = SINGLE_TAX2 + RATE3 * (income - SINGLE_LEVEL2);
- }
- } else {
- // married
- if (income <= MARRIED_LEVEL1) {
- tax = income * RATE1;
- } else if (income <= MARRIED_LEVEL2) {
- tax = MARRIED_TAX1 + RATE2 * (income - MARRIED_LEVEL1);
- } else {
- tax = MARRIED_TAX2 + RATE3 * (income - MARRIED_LEVEL2);
- }
- }
- return tax;
- }
- void report(double income, bool married) {
- double tax = tax_amount(income, married);
- double percent = round((tax / income) * 10000.0) / 100.0;
- cout << "Tax for ";
- if (!married) {
- cout << "single";
- } else {
- cout << "married";
- }
- cout << " with income of " << income;
- cout << " = " << tax << " (" << percent << "%" << ")" << endl;
- }
- int main() {
- report(12000.0, false);
- report(38000.0, false);
- report(77000.0, false);
- report(12000.0, true);
- report(38000.0, true);
- report(77000.0, true);
- return EXIT_SUCCESS;
- }
problème : que faire si on ajoute plus de tranches d'imposition ? par exemple une tranche à 21% entre RATE1 et RATE2 ?
- CODE
- implantation 2
- #include <iostream>
- #include <cstdlib>
- #include <cmath>
- #include <vector>
- #include <map>
- using namespace std;
- class TaxProperties {
- public:
- vector<double> ceiling;
- vector<double> mintax;
- vector<double> rates;
- };
- map<string, TaxProperties> taxator;
- double tax_amount(double income, bool married) {
- double tax = 0.0;
- TaxProperties *prop;
- if (!married) {
- prop = &taxator["single"];
- } else {
- prop = &taxator["married"];
- }
- size_t slice = 0;
- while (slice < (*prop).ceiling.size()) {
- if (income > (*prop).ceiling[slice+1]) ++slice;
- else break;
- }
- tax = (*prop).mintax[slice] + (income - (*prop).ceiling[slice]) * (*prop).rates[slice];
- return tax;
- }
- void report(double income, bool married) {
- double tax = tax_amount(income, married);
- double percent = round((tax / income) * 10000.0) / 100.0;
- cout << "Tax for ";
- if (!married) {
- cout << "single";
- } else {
- cout << "married";
- }
- cout << " with income of " << income;
- cout << " = " << tax << " (" << percent << "%" << ")" << endl;
- }
- int main() {
- taxator["single"].ceiling = { 0, 21450.0, 51900.0, 10e20};
- taxator["single"].mintax = { 0, 3217.0, 11743.0 };
- taxator["single"].rates = { 0.15, 0.28, 0.31 };
- taxator["married"].ceiling = { 0, 35800.0, 86500.0, 10e20};
- taxator["married"].mintax = { 0, 5370.0, 19566.0 };
- taxator["married"].rates = { 0.15, 0.28, 0.31 };
- report(12000.0, false);
- report(38000.0, false);
- report(77000.0, false);
- report(12000.0, true);
- report(38000.0, true);
- report(77000.0, true);
- return EXIT_SUCCESS;
- }
1.2.3.e Exemple 4 : informatique vs mathématiques
On désire répondre à la question suivante : calculer la somme des nombres entiers multiple de 3 dans l'intervalle [1..1000].
- réponse mathématique : elle s'apparente à une définition
$$X = \{ x ∊ [1..1000] \text" tels que " x = 3*k \text" avec " k ≧ 1 \}$$ $$r = ∑↙{x ∊ X}x$$ - réponse informatique : on doit définir comment calculer le résultat (algorithme)
r = 0 pour tout entier x multiple de 3 dans [1..1000] faire r = r + x fin pourr = 0 pour tout entier x dans [1..1000] faire si x est multiple de 3 alors r = r + x fin si fin pourqui se traduit par :r = 0; for (int i=1; i<=1000; ++i) { if ((x % 3) == 0) r = r + x; }ou par le code suivant qui évite le if pénalisant dans une boucle :r = 0; for (int i=3; i<=1000; i += 3) { r = r + x; } - réponse informatique et mathématique:
si on réfléchit on s'aperçoit que r = 3 + 6 + ... + 999 = 3 * (1 + 2 + ... + 1000/3) ce
qui permet d'éviter de faire une boucle :
int n = 1000/3 (=333); r = 3 * n * (n+1) / 2; // = $ 3 × ∑↙{i=1}↖n i$ = 166833
1.2.4. Quelles doivent être ses qualités ?
Il doit :
- posséder une grande culture générale et être ouvert aux autres disciplines : car il sera amené à travailler dans d'autres domaines que le sien,
- disposer d'une grande faculté d'analyse
- opérer avec méthode
- être capable de s'adapter au changement
ces qualités concourent à le rendre apte à programmer, c'est à dire traduire des traitements humains en opérations compréhensibles par une machine. Un informaticien doit donc être (au minimum) capable :
- de concevoir des algorithmes (architecte)
- de les coder dans un langage donné (bâtisseur)
Remarque : on emploie également comme synonyme du verbe coder, les verbes implanter ou implémenter (tiré de l'anglais).
1.3. Exemples liés au matériel
La suite d'exemples de cette section a pour but de montrer que la programmation assembleur et la connaissance du matériel peuvent influencer le temps d'exécution de nombreux algorithmes.
1.3.1. Produit de matrices
Une matrice est un tableau à deux dimensions de nombres ou de fonctions :

Soient deux matrices A(n × p) et B(q × m) . Le produit de A par B n'est possible que si p = q. Le résultat est une matrice C(n x m) dont les coefficients ci,j sont définis par la formule suivante :
On peut traduire les formules de calcul mathématiques du produit de deux matrices carrées (800 x 800) en langage C, par :
#define N 800
double A[N][N], B[N][N], C[N][N];
for (i = 0; i < N; ++i) {
for (j = 0; j < N; ++j) {
double s=0;
for (k = 0; k < N; ++k) s += A[i][k] * B[k][j];
C[i][j] = s;
}
}Si on exécute cet algorithme pour différentes valeurs de N, on s'aperçoit que celui-ci possède un comportement anormal pour des valeurs de N bien précises. Sur un Pentium 4 Prescott 2800 Mhz, on recense les temps d'exécution suivants sous Linux Ubuntu 6.06. Le programme est compilé en utilisant gcc 4.0.
| N | temps |
| 800 | 5 |
| 1000 | 11 |
| 1200 | 23 |
| 1240 | 24 |
| 1280 | 127 |
| 1320 | 26 |
Cette "anomalie" peut être expliquée, comme nous le verrons plus avant dans ce cours, mais nécessite de posséder des connaissances en architecture des ordinateurs afin de comprendre ce genre de phénomène et de pouvoir y remédier.
1.3.2. POPCNT 8s vs 23s
Une même fonction (popcount) s'exécute en 8s ou en 23s en fonction des options de compilation utilisées !! (cf chapitre 3).
- 23s : sur Pentium-M
-O2 -march=pentium-m - 8s : sur Pentium-M
-O2
Ce phénomène apparaît sur Pentium-M 760, Core 2 Duo E6420, mais pas sur Pentium 4, Core 2 Duo E6750, Athlon 64, Sempron. Qu'elle en est la cause et comment y rémédier ?
1.3.3. GASAT
GASAT (Genetic Algorithm for SAT) est un logiciel écrit par F. Lardeux qui permet de résoudre le problème de SATisfiabilité d'un ensemble de clauses du calcul propositionnel.
Améliorations :
- version de base : 11m48s + 22s sys
gcc -O3 - compilateur Intel + vectorisation : 9m24s + 23s sys (-18%)
icc -O3 - compilateur Intel + multi-allocation : 8m55s + 2s sys (-26%)
1.3.4. Maximum de Parcimonie (Bioinformatique)
La fonction la plus utilisée est la fonction de calcul d'une séquence hypothétique et du nombre de changements de la séquence hypothétique par rapport aux séquences initiales. Le code de la fonction est le suivant :
int fitch(char *x, char *y, char *z, int size) {
int changes=0;
for (int i = 0; i < size; ++i) {
// compute intersection
z[i] = x[i] & y[i];
// if empty, take union and increase number of changes
if (z[i] == 0) {
z[i] = x[i] | y[i];
++changes;
}
}
return changes;
}Cette fonction peut être améliorée grâce aux instructions SSE (vectorisation du code) pas par le compilateur, mais par le programmeur et permet suivant les architectures d'atteindre un gain de 70 à 95 %.
| méthode | temps (s) | gain | commentaire |
| C basique | 43.090 | - | |
| C optimisé 1 | 39.770 | 7% | suppression du if (z[i] == 0) |
| C optimisé 2 | 29.310 | 32% | autre suppression plus efficace |
| assembleur 1 | 25.360 | 41% | traduction de C optimisé 1 version 1 |
| assembleur 2 | 21.750 | 51% | traduction de C optimisé 1 version 2 |
| assembleur 3 | 21.420 | 51% | traduction de C optimisé 1 version 3 |
| SSE | 2.230 | 95% | version SSE |
Remarque : la vectorisation utilise les 16 octets des registres SSE, on obtient un gain supérieur au calcul théorique puisque 43,09/2.23 = 19,32 > 16
Autre données sur Core i5 4570 Haswell doté des instructions AVX2 (Advanced Vector Extensions):
- exécution en 32 bits :
size C sse %sse avx2 %avx2 127 10.940 0.870 92.05% 1.760 83.91% 255 25.220 1.040 95.88% 1.840 92.70% 511 53.620 1.490 97.22% 2.090 96.10% 1023 109.940 2.260 97.94% 2.460 97.76% 2047 221.790 3.800 98.29% 3.350 98.49% 4095 442.820 6.780 98.47% 5.280 98.81% temps d'exécution et amélioration sur Core i5 4570 (haswell) @ 3.2 Ghz - exécution en 64 bits :
size C sse %sse avx2 %avx2 127 1.640 0.620 62.20% 1.520 7.317% 255 6.000 0.790 86.83% 1.620 73% 511 18.380 1.160 93.69% 1.810 90.15% 1023 42.970 1.880 95.62% 2.280 94.69% 2047 90.750 3.450 96.20% 3.260 96.41% 4095 184.640 6.370 96.55% 5.680 96.92% temps d'exécution et amélioration sur Core i5 4570 (haswell) @ 3.2 Ghz
On notera que:
- l'AVX2 surpasse le SSE a partir du moment où on dépasse une certaine longueur de chaîne.
- l'exécution en 64 bits du code non vectorisé est plus rapide qu'en 32 bits
1.3.5. Elimination des doublons
Considérons un ensemble d'enregistrements stockés sous forme d'un tableau de $N$ enregistrements de $P$ champs. Le premier champ contient un identifiant d'enregistrement qui varie de 1 à $N$.
On désire supprimer les doublons, c'est à dire les enregistrements qui ont un identifiant différent mais dont les autres champs sont identiques. Quelle méthode utiliseriez vous ?
La méthode la plus simple (méthode 1) est la suivante :
- typedef unsigned int u32;
- u32 N = 7000000; // 7 millions
- u32 P = 10;
- /**
- * Compare two records given their address
- */
- bool is_equal(u32 *a, u32 *b) {
- for (u32 k = 1; k < P; ++k) {
- if (a[k] != b[k]) return false;
- }
- return true;
- }
- // create data
- u32 *data = new u32 [ N * P ];
- // create array that tells which record is a duplicate
- bool *remove = new bool [ N ];
- fill(&remove[0], &remove[N], false);
- // fill data ...
- // find duplicates
- for (u32 i = 0; i < N-1; ++i) {
- for (u32 j = i+1; j < N; ++j) {
- if (is_equal(&data[i * P], &data[j * P])) {
- remove[j] = true;
- }
- }
- }
mais elle possède une complexité en $O(N^2/2)$.
Un autre méthode (méthode 2) consiste :
- à ajouter un champ qui contient une checksum (en fait une fonction de hashage)
- à trier les enregistrements suivant la checksum
- et à comparer uniquement ceux qui ont la même checksum
Voici une liste de résultats pour différentes architectures :
| Ryzen 1700x | Ryzen 1700x | i7 4790 | i7 4790 | i5 7400 | i5 7400 | |
| N | méthode 1 | méthode 2 | méthode 1 | méthode 2 | méthode 1 | méthode 2 |
| 10.000 | 0.08 | 0.00 | 0.08 | 0.00 | 0.10 | 0.00 |
| 20.000 | 0.35 | 0.01 | 0.34 | 0.00 | 0.36 | 0.00 |
| 50.000 | 2.15 | 0.02 | 2.09 | 0.01 | 2.26 | 0.01 |
| 100.000 | 8.59 | 0.03 | 8.47 | 0.02 | 9.06 | 0.02 |
| 200.000 | 36.93 | 0.07 | 36.81 | 0.06 | 39.39 | 0.06 |
| 300.000 | 93.73 | 0.10 | 96.09 | 0.09 | 98.68 | 0.09 |
| 500.000 | 313.14 | 0.26 | 281.87 | 0.17 | 277.46 | 0.18 |
| 1.000.000 | 1285.11 | 0.42 | 1152.68 | 0.40 | 1134.19 | 0.40 |
1.3.6. Compression vidéo x264
cf. l'article de hardware.fr : Impact des compilateurs sur les architectures CPU x86/x64
| méthode | indice de performance |
| Core i7 AVX | 38 |
| Core i7 AVX assembleur | 139 |
1.3.7. Pile et variables locales
On considère le programme suivant :
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int variables[200];
} Contrainte;
#define MAX_CONTRAINTES 10400
int main() {
Contrainte tabc[MAX_CONTRAINTES];
fprintf(stderr, "coucou");
return 0;
}Lorsque l'on fixe MAX_CONTRAINTES à 10400, le programme s'exécute et affiche le message "coucou". Par contre si on passe MAX_CONTRAINTES à 10500, le programme produit un "Segmentation Fault" et le message n'est pas affiché. Pourquoi ?
En fait le problème est lié à la pile : on réserve en effet ici le tableau tabc au noveau de la pile d'appel des sous-programmes.
Under Unix-like systems, programs may throw a Segmentation Fault error. This can be due to stack overflow, especially from recursive function calls or huge data sets.
Pour connaître la taille de la pile, il faut utiliser la commande ulimit
ulimit -a
stack size (kbytes, -s) 8192
(voir man bash, puis /ulimit)
Soit une taille de 8192 ko donc 8 Mo.
Or dans le cas présent :
- 8192*1024 = 8_388_608 octets
- 10400 * 200 * 4 = 8_320_000 < 8_388_608
- 10500 * 200 * 4 = 8_400_000 > 8_388_608
1.3.8. Bug du Boeing 787
Voir le site developpez.com dont sont extraites les paragraphes suivants pour plus de détails.
En 2015, il a été découvert qu’un bogue informatique pouvait empêcher les pilotes de garder le contrôle du Boeing 787, possiblement en plein vol, a informé la Federal Aviation Administration (FAA) dans une directive destinée à toutes les compagnies aériennes utilisant cet avion.
Le bogue qui n’est rien d’autre qu’un problème classique de débordement d’entier, est situé au niveau du contrôle des générateurs de l’avion. Le bogue rapporté par Boeing à la FAA est déclenché lorsque ces derniers sont laissés allumés durant 248 jours (8 mois). Le 787 a quatre de ces unités de contrôle des générateurs, qui allumées simultanément, peuvent s’arrêter en même temps et causer une interruption totale du système électrique.
La note de la FAA n’avait pas donné plus de détails sur ce bogue, mais il s’agirait d’un problème de débordement d’entier 32-bits déclenché après 231 centisecondes (248,55 jours)problème de traduction, c'est 2^31 de fonctionnement continu. 2^31 étant le nombre de secondes dans 248 jours multipliés par 100 (un compteur en centièmes de seconde).
Note: 248.55 jours = 248.55*24*360000 = 2_147_472_000 et 2^31 = 2_147_483_648 !? En fait c'est 248.5513 (= 2^31 / 24 / 3600)
Pour implémenter un tel compteur, deux options peuvent être suivies, soit augmenter le nombre de bits utilisés, ce qui empêche le débordement, ou bien travailler avec l’arithmétique multiprécision. Certains commentateurs ont suggéré qu’il y a ici un besoin de passer à une architecture 64 bits puisqu’elle permet d’utiliser plus de registres (généraux et XMM), un meilleur support pour PIC (position-independent code), et en général une meilleure performance des instructions syscall/sysret du système. Et dans ce cas, la période nécessaire pour le redémarrage de l'avion passerait de 248 jours à 3 milliards d'années !
1.4. Représentation de l'information
Le fonctionnement des ordinateurs se fonde sur un modèle logique ou binaire, c'est à dire, un modèle à 2 états distincts qui sont le 1 ou le 0, le vrai ou le faux, l'ouvert ou le fermé.
| 1 | ≡ | vrai | ≡ | fermé |
| 0 | ≡ | faux | ≡ | ouvert |
Ce modèle binaire (ou base 2) est utilisé pour représenter l'information de différentes façons en fonction des données à représenter.
1.4.1. Représentation des entiers naturels
Pour représenter un nombre entier naturel dans une base b, il faut disposer de b chiffres disctincts allant de 0 à b-1. Tout nombre N s'exprime alors sous la forme :
où chaque ai est un chiffre.
Ainsi en base 10, on a :
- 197510 = 1 × 1000 + 9 × 100 + 7 × 10 + 5
- 197510 = 1 × 103 + 9 × 102 + 7 × 101 + 5 × 100
De la même manière, en base 2 :
- 110012 = 1 × 24 + 1 × 23 + 1 × 20
- 110012 = 16 + 8 + 1 = 2510
Dans la notation binaire :
- le bit (ou chiffre) le plus à gauche est appelé bit de poids fort
- le bit (ou chiffre) le plus à droite est appelé bit de poids faible
| 20 = | 1 | 28 = | 256 |
| 21 = | 2 | 29 = | 512 |
| 22 = | 4 | 210 = | 1024 |
| 23 = | 8 | 211 = | 2048 |
| 24 = | 16 | 212 = | 4096 |
| 25 = | 32 | 213 = | 8192 |
| 26 = | 64 | 214 = | 16384 |
| 27 = | 128 | 215 = | 32768 |
| 216 = | 65536 | 231 = | 2.147.483.648 |
| 224 = | 16.777.216 | 232 = | 4.294.967.296 |
1.4.1.a Unités
- l'unité de base est le bit (pour BInary digiT) qui peut prendre soit la valeur 0, soit la valeur 1
- un ensemble de 4 bits consécutifs est appelé un quartet
- un ensemble de 8 bits consécutifs est appelé un octet (byte en anlgais)
- deux octets consécutifs (16 bits) forment un mot (word)
- quatre octets consécutifs (32 bits) forment un double mot (double word)
- huits octets consécutifs (64 bits) forment un quatre mot (quad word)
Remarque : c'est l'octet qui est utilisé comme unité de référence pour mesurer la capacité des mémoires.
| Puissance de 2 | Unité | Symbole |
| 210 | kilo octet | ko |
| 220 | mega octet | Mo |
| 230 | giga octet | Go |
| 240 | tera octet | To |
| 250 | peta octet | Po |
| 260 | exa octet | Eo |
| 270 | zetta octet | Zo |
Pour représenter les données on utilisera 1, 2, 4 ou 8 octets consécutifs pour les nombres entiers et réels.
1.4.1.b Comment convertir un nombre de la base 10 vers la base $b$ ?
α) Méthode 1 : divisions successives
Il suffit tout simplement de réaliser des divisions successives du nombre par b. Par exemple, pour convertir 13 (base 10) en base 2, il suffit de réaliser les divisions successives de 13 par 2. On part ensuite du dernier résultat obtenu et on remonte le long des restes des divisions. Ainsi :

β) Méthode 2 : intervalles de puissances de 2
On cherche dans quel intervalle de puissances de 2 le nombre à convertir se trouve. Par exemple pour convertir 1970 :
$2^{10}$ < 1970 < $2^{11}$, donc 1970 contient au moins $2^{10} = 1024$, donc on retranche 1024: $1970-1024= 946$
$2^{9}$ < 946 < $2^{10}$, donc 946 contient au moins $2^{9} = 512$, donc on retranche 512: $946-512= 434$
On réitère le processus jusqu'à obtenir : $111\_1011\_0010\_b$
1.4.1.c Addition de nombres binaires
Pour additionner deux nombres binaires on procède comme en base 10.
| X + Y | = | reste | retenue |
| 0 + 0 | = | 0 | 0 |
| 0 + 1 | = | 1 | 0 |
| 1 + 0 | = | 1 | 0 |
| 1 + 1 | = | 0 | 1 |
| 1 + (1 + 1) | = | 1 | 1 |
par exemple :
| 1 | 1 | 1 | 1 | (retenues) | ||
| 1 | 1 | 0 | 1 | (= 1310) | ||
| + | 1 | 1 | 1 | 1 | (= 1510) | |
| 1 | 1 | 1 | 0 | 0 | (= 2810) | |
1.4.1.d Octal et hexadécimal
En informatique les bases 8 (octal) et 16 (hexadécimal) sont souvent utilisées. La base 16 est très pratique car elle permet de représenter les nombres binaires par quartet et permet de représenter un octet grâce à deux chiffres.
En base 16, on utilise 16 chiffres
- 0, 1, ...., 9
- A (=10), B (=11), ..., E (=14), F(=15)
On passe aisément de la lase 2 à la base 16 en regroupant les bits par quartet :
| base 2 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| base 16 | 3 | E | 5 | |||||||||
Enfin, on utilise parfois pour distinguer les nombres écrits dans une base donnée, une notation héritée du passé (notamment des premiers assembleurs) :
- %110101 pour le binaire
- $3FE pour l'hexadécimal, ou 03FEh
- en langage C : 0xFF pour représenter un nombre en base 16
- en langage C : 0123 pour représenter un nombre en octal
1.4.2. Représentation des entiers relatifs
Plusieurs représentations existent mais on utilisera la notation binaire en complément à 2 qui permet de réaliser des opérations arithmétiques sans problème.
Dans cette notation, les nombres positifs utilisent le même procédé de réprésentation que la notation binaire de la section précédente.
Pour obtenir le codage binaire d'un nombre négatif on procède en commençant par fixer la taille de l'espace de codage en nombre de bits : par exemple 8, 16 ou 32 bits. Prenons 8 bits das le cas présent. Ensuite :
- on prend la valeur absolue du nombre que l'on code sur 8 bits
- on complémente chacun des bits (i.e. on remplace les 0 par des 1 et inversement)
- on ajoute 1 au résultat final
Par exemple, pour représenter -8 :
| | -8 | = 8 = | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| Complément | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | |
| (+1) | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
Autres représentations sur 8 bits :
| -1 = | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| -2 = | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | |
| -127 = | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| -128 = | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
On remarque que tous les nombres négatifs ont leur bit de poids fort à 1, alors que les nombres positifs ont leur bit de poids fort à 0.
Dans la notation binaire en complément à 2 sur n bits, on peut coder les nombres entre :
| avec n bits : | valeur min | valeur max |
| avec 8 bits : | -128 | +127 |
| avec 16 bits : | -32768 | +32767 |
| avec 32 bits : | -2.147.483.648 | +2.147.483.647 |
1.4.3. Représentation des nombres réels (norme IEEE 754)
La norme IEEE 754 (Standard for Binary Floating-Point Arithmetic) définit 4 représentations de nombres réels (appelés flottants en informatique) :
- simple précision (32 bits)
- double précision (64 bits)
- simple précision étendue (43 bits et plus)
- double précision étendue (79 bits en plus, on utilise 80 bits)
Les nombres sont décomposés en :
- signe
- mantisse (tronquée)
- exposant (décalé)

N = (-1)signe × 2(exposant décalé - 127) × (1,mantisse tronquée2)
| Représentation | Simple précision |
Double précision |
| taille (bits) | 32 | 64 |
| signe | 1 | 1 |
| Exposant | 8 | 11 |
| Mantisse | 23 | 52 |
| Echelle | 10+/- 38 | 10+/- 308 |
Exemples de représentations :
| Valeur | Signe | Exposant | Mantisse | Hexadécimal |
| 12,5 | 0 | 100.0001.0 | 100.1000.0000.0000.0000.0000 | 41.48.00.00 |
| -0,5 | 1 | 011.1111.0 | 000.0000.0000.0000.0000.0000 | BF.00.00.00 |
| 0.0 | 0 | 000.0000.0 | 000.0000.0000.0000.0000.0000 | 00.00.00.00 |
1.4.3.a Exemple de conversion
On désire convertir 12,510 en notation IEEE 754 :
- pour la partie entière : 1210 = C16 × 160
- pour la partie décimale : 0,510 = 8 / 16 = 8 × 16-1
- 12,510 = C,8 E160
- soit en base 2 : 1100,1000 × 20
- ou encore 1,1001 × 23
- l'exposant est alors calculé suivant la formule : 127 + 3 = 130 (exposant décalé)
- la mantisse devient 1001, le premier 1 étant supprimé car les nombres différents de 0 commencent tous par un 1.
Finalement, on obtient :
| S | exposant déc. | mantisse tronquée | ||||||||||||||||||||||||||||||
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| hexadécimal | 4 | 1 | 4 | 8 | 0 | 0 | 0 | 0 | ||||||||||||||||||||||||
Liens :
1.4.3.b Problèmes liés à la représentation IEEE 754
La représentation IEEE 754 peut poser des problèmes de représentation pour certains nombres après réalisation de calculs. Soit le programme suivant :
#include <stdio.h>
float v1 = 1.2;
float v2 = 1.3;
float v3 = 1.3001;
int main() {
float w1 = v1-v2;
float w2 = v2-v3;
printf("w1 = %g\n", w1);
printf("w2 = %g\n", w2);
return 0;
}
Le résultat en sortie est :
w1 = -0.0999999 (au lieu de 0.1)
w2 = -0.000100017 (au lieu de 0.0001)
En outre, pour comparer deux nombres flottants on utilisera pas l'opérateur d'égalité (=) mais on vérifiera que la valeur absolue de leur différence est inférieure ou égale à un ε donné:
float v1, v2;
if (fabs(v1-v2) < 1E-6) printf("v1 = v2");
1.4.4. Caractères (ASCII, Unicode)
Le codage des caractères a été normalisé dès 1968 avec la norme ASCII (American Standard Code for Information Interchange)
- 1968 ASCII (Ansi X3.4, 128 caractères)
- 1972 ASCII localisé
- 1985 ASCII étendu (ISO-8859-1) : 256 caractères, prise en compte des langues européennes
- 1993 Unicode 1.1 (ISO 10646-1:1993)
- 2000 Unicode 3.0 (ISO 10646-1:2000)
suivant les langages, les chaînes de caractères sont codées différemment :
- en langage C, une chaîne est une suite consécutive d'octets (au format ASCII) terminée par le caractère
'\0', - en Pascal, une chaîne a une longueur maximum de 255 caractères, car le premier octet de la chaîne code pour la longueur.
1.4.4.a Codage ASCII
Le code ASCII est décomposé en deux tables de 128 caractères :
- caractères 0 à 127 (ASCII américain)
- caractères 128 à 255 (ASCII étendu ou européen) avec caractères accentués
(Remarque : les tables ci-dessus sont issues du site lookuptables).
Les caractères 0 à 31 sont des caractères non imprimables et correspondent à des codes de contrôle :
- 8 = BS = backspace
- 13 = CR = Carriage Return
- 10 = LF = Line Feed
- 27 = ESC = escape
Remarque : sous Windows, la fin de ligne est représentée par CR suivi de LF, alors que sous Linux seul LF est utilisé. C'est pourquoi lorsque l'on ouvre sous Linux un fichier texte édité sous Windows on voit apparaître des caractères '^M' qui correspondent à CR.
Voici un petit script qui permet de supprimer les CR sous unix :
#!/bin/sh
# script qui elimine les CR dans les fichiers texte
# on passe en parametre de ce fichier une liste de fichiers qui seront
# traites separement
for i in \$*
do
echo \$i
tr -d '\015' <\$i >tmp.txt
mv tmp.txt \$i
done
- Remarque 1 : la valeur 015 est interprétée en octal car elle commence par le chiffre 0 et vaut donc 13 en décimal.
- Remarque 2 : la commande tr -d supprime toute occurrence de CR dans le fichier passé en entrée et stocke le fichier résultat dans tmp.txt. Taper man tr sous Unix pour connaître les autres fonctionnalités de tr
- Remarque 3 : on peut également installer les utilitaires dos2unix et unix2dos du package tofrodos sous Ubuntu par exemple.
1.4.4.b Codage Unicode
Le standard Unicode est un mécanisme universel de codage de caractères. Les 256 caractères du code ASCII ne sont malheureusement pas suffisants pour coder des langues comme l'arabe, l'hindi, le chinois, le japonais, ... La version 4.1.0 d'Unicode de 2005 permet de coder 245.000 caractères. Les caractères Unicode utilisent 16 ou 32 bits pour stockage.
voir le site suivant pour plus d'informations : unicode.org et le tuteur Unicode.
Remarque : En Java les chaînes de caractères sont codées en utilisant le format UNICODE.
1.4.5. Espace mémoire occupé par les types de base en langage C
| type / octets | 32 bits | 64 bits |
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| long int | 4 | 8 |
| long long int | 8 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
| void * | 4 | 8 |
Compétences à acquérir
il faut être capable de :
- coder et décoder des nombres entiers naturels écrits en base 2, 8, 10 ou 16.
- coder et décoder des nombres entiers relatifs en base 2
- réaliser des additions avec des chiffres en base 2
- convertir un nombre réel en sa représentation IEEE 754
Exercices d'entraînement
Exercice 1 : donner la valeur décimale des nombres suivants :
- 1100012
- 4218
- 7F16
- FF16
- FACE16
- CAFE16
Exercice 2 : convertir les nombres entiers positifs suivants en base 2, 8 et 16 :
- 11
- 23
- 127
- 160
- 511
- 1024
Exercice 3 : convertir les nombres entiers négatifs suivants en notation binaire en complément à 2 en utilisant une représentation sur 8 bits :
- -11
- -23
- -160
- -123
Exercice 4 : réaliser les additions en binaire en codant les nombres suivants en binaire :
- 23 + 35
- -23 + 35
- -35 + 23
- -128 + (-2)
Exercice 5 : convertir les nombres réels suivants en notation IEEE 754 sur 32 bits :
- 121,125
- 98,625
- 1,046875
- 0,1
Exercices de programmation
Exercice 6 : écrire un programme en langage C qui prend en paramètre un nombre réel et donne sa représentation binaire au format IEEE 754.
Exercice 7 : écrire un programme en langage C qui permet de convertir un nombre entier naturel exprimé en décimal en sa représentation en base 2, 8 et 16.
Exercice 8 : écrire un programme en langage C qui permet de convertir un nombre entier naturel exprimé en base 2, 8 ou 16 en sa représentation décimale.