Parallélisme : travaux dirigés et pratiques
- cours 1 : Introduction Générale
- cours 2 : Algorithmes et Métriques
- cours 3 : P-Threads et C++11 Threads
- cours 4 : OpenMP
- cours 5 : MPI
1. Introduction Générale
Science sans conscience n'est que ruine de l'âme, Rabelais
François Rabelais, 1483 ou 1494 à 1553.
On ne peut rien enseigner à autrui. On ne peut que l'aider à le découvrir lui-même.
Galilée (Galileo Galilei), 1564 à 1642.
1.1. Introduction
Depuis mai 2005 avec l'arrivée des Intel Pentium D (Smithfield = 2 Pentium 4 Prescott) et des AMD Athlon 64 X2 les processeurs d'architecture x86 disposent dans leur grande majorité de plusieurs coeurs de calcul. Cela permet de rendre l'expérience utilisateur beaucoup plus agréable. Par exemple un coeur peut s'occuper de l'interface graphique, un autre de la base de données, le troisième du serveur web, etc.
Un autre intérêt est l'exécution d'un même code sur plusieurs coeurs pour des données différentes. On diminue ainsi le temps de calcul en répartissant la charge de travail sur plusieurs dispositifs matériels.
On parle alors de programmation parallèle ou concurrentielle.
Le terme concurrentiel est plutôt utilisé :
- avec des programmes parallèles qui doivent avoir accès aux mêmes ressources et sont donc en concurrence pour avoir accès à ces ressources
- ou pour des programmes qui sont en concurrence pour résoudre un même problème
La programmation parallèle et les architectures parallèles ne sont pourtant pas récentes car on peut les faire remonter aux années 50, mais programmer en parallèle est souvent vu comme une tâche difficile :
- du fait de l'utilisation de solutions bas niveau (cas des pThreads)
- ou dûe au fait qu'il faut repenser le code ou le modifier substantiellement
Tout ceci tend à décourager le néophyte, pourtant, de nos jours des solutions simples à mettre en oeuvre existent, comme OpenMP qui permet dorénavant d'introduire du parallélisme dans un programme séquentiel en ajoutant une directive #pragma avant une boucle for par exemple.
1.2. CPU, GPU et parallélisme
1.2.1. Cas des GPU
Si les microprocesseurs CPU sont des dispositifs généraux de calcul, cela est quelque peu différent pour les cartes graphiques (GPU = Graphics Processing Unit), qui sont très fortement axés sur le traitement parallèle.
Pour les calculs en virgule flottante les cartes graphiques apparaissent comme des monstres de puissance de calcul comparativement aux processeurs. L'introduction de la technologie CUDA de NVidia permet, tout en gardant une syntaxe C++, de déporter une partie des calculs vers le GPU vu alors comme une sorte de coprocesseur.
Notons qu'en 2016 la GTX 1080 de NVidia possède une puissance de calcul en simple précision de 8873 GFlops pour un prix de 600 dollars, alors que le Cray T932 (32 processeurs) développé à la fin des années 90 avait une puissance de 60 GFlops pour un cout de 35 millions de dollars, un poids de 4545 kg et des dimensions de 2.3 m x 1.5 m x 1.5 m.
| Caractéristique | Cray T932 | GTX 1080 | Evolution |
| année | 1997 | 2016 | +20 ans |
| puissance GFlops | 60 | 8873 | x 147.88 |
| prix (dollars) | 35.000.000 | 600 | / 58_333 |
| rapport performance/coût | 0.0000017 | 14.79 | x 8_700_000 |
Le rapport performance/coût indique qu'avec une carte graphique, 1 dollar donne une puissance de 14,8 GFlops.
1.2.2. Cas des CPU
Ces dernières années, on a assisté, grâce au fait que AMD soit revenu au premier plan par rapport à Intel pour la conception et la fabrication de microprocesseurs, à une augmentation du nombre de coeurs par processeur.
Par exemple, 2017 voit l'arrivée des microprocesseurs :
- AMD Ryzen séries 1700 et 1800 avec 8 coeurs et 16 Threads pour un prix inférieur à \$500.
- Ryzen Threadripper* 1950X : 16C/32T \$999 (août 2017)
- De même chez Intel avec les Skylake-X 980XE 18C/36T à \$2000.
(*) ripper signifie défonceuse (pour les Bulldozers).
En 2020, l'AMD Threadripper 3990X comporte 64 coeurs et 128 threads.
En 2021, Intel lance les premiers processeurs hybrides de la gamme Alder Lake comme le Core i9 12900K doté de 8 coeurs Performance (soit 16 threads) et 8 coeurs Efficiency (8 threads), soit un total de 24 threads.
En 2025, on dispose (prix ):
- chez Intel des Core Ultra 9 285K dotés de 24 coeurs et tournant à 5,7 Ghz à 700 € (125 à 250 W)
- chez Intel des Intel® Xeon® Platinum 8593Q dotés de 128 threads (64 coeurs) tournant à 3,9 Ghz à \$ 12400 (385 W)
- chez AMD des Ryzen™ 9 9950X3D dotés de 32 threads (16 coeurs) tournant à 5,7 Ghz pour 680 € (170 W)
- chez AMD des AMD EPYC™ 9965 dotés de 384 threads (192 coeurs) tournant à 3,35 Ghz pour \$ 14800 (500 W)
1.3. Qu'est ce que le parallélisme et à quoi sert-il ?
Définition: Parallélisme
capacité à exécuter du code de manière simultanée sur différents dispositifs matériels (CPU, GPU APU,...).
On distingue généralement :
- le parallélisme de données : le même programme s'exécute sur des données différentes
- le parallélisme de tâches : des programmes différents appliquent des traitements sur les mêmes données, ou des données différentes
Le parallélisme vise à diminuer le temps de calcul d'un programme en répartissant la charge de travail sur $N$ dispositifs matériels plutôt qu'un seul.
On peut également fonctionner par décomposition du problème initial en sous-problèmes qui peuvent être résolus en parallèle.
D'autres aspects sont également à prendre en considération :
- la coopération pour la résolution : exécution de plusieurs algorithmes de résolution pour résoudre une instance d'un problème et qui échangent de l'information afin d'améliorer l'efficacité de la recherche
- la résolution de benchmarks sur cluster : on lance $N$ exécutions indépendantes en parallèles
1.4. Classification/Taxonomie de Flynn
Bien que cette classification soit ancienne (1966) elle permet de donner un aperçu des modes de fonctionnement envisageables pour le parallélisme. Le mot single n'est pas à prendre au sens d'unique mais signifie pour les données ne sont pas démultipliées :
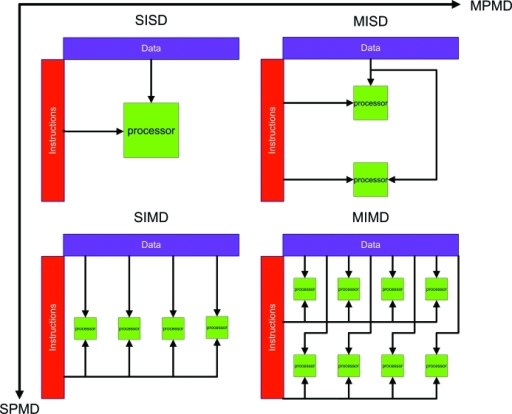
- SISD (Single Instruction, Single Data)
- Correspond à un CPU doté d'un coeur où une instruction travaille sur une donnée à la fois. Il s'agit du modèle classique d'exécution dit de Von Neumann.
- SIMD (Single Instruction, Multiple Data)
- Cas des processeurs vectoriels ou unités vectorielles (SSE, AVX : paddd, addps)
- MISD (Multiple Instructions, Single Data)
- Peu répandu car pas naturel, voire inexistant. Eventuellement on peut penser aux FPGA (Field-programmable Gate Array) pour ce genre de fonctionnement
- MIMD (Multiple Instructions, Multiple Data)
- Cas des processeurs multi-coeurs avec des processus différents qui travaillent sur des données différentes. Cas des clusters de machines
Notons que bien que nos processeurs actuels puissent être dotés d'un seul coeur, ils exploitent néanmoins le parallélisme au niveau des instructions : ILP (Instruction Level Parallelism). Par exemple une instruction sur les entiers (ALU) peut être exécutée en parallèle d'une instruction sur les flottants (FPU).
1.5. Les différents niveaux de parallélisme
Le parallélisme apparaît à tous les niveaux : du microscopique au macroscopique.

Document Intel de Michael Klemm, Senior Application Engineer
1.6. MIMD et Partage de la mémoire
Dans le cas des systèmes MIMD, on distingue plusieurs architectures pour l'accès à la mémoire :
- systèmes à mémoire partagée (shared memory model) : l'ensemble des processeurs a accès à une mémoire globale
- systèmes à mémoire distribuée (distributed memory model) : chaque processeur dispose de sa propre mémoire et doit obtenir des données de la mémoire des autres processeurs par passage de message
En fait on devrait plutôt parler de système :
- à mémoire globale (au lieu de partagé)
- à mémoire répartie (au lieu de distribuée)
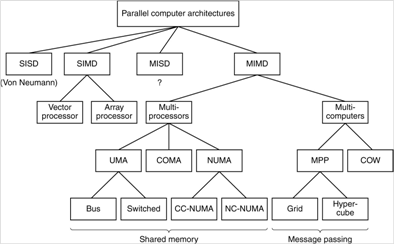
Note : COW signifie Cluster Of Workstations.
1.6.1. Mémoire partagée - ou globale
Un multiprocesseur symétrique (à mémoire partagée), ou symmetric shared memory multiprocessor (SMP) est une architecture parallèle qui consiste à utiliser des processeurs identiques au sein d'un ordinateur de manière à augmenter la puissance de calcul tout en conservant une mémoire unique.
dans ce cas on peut distinguer les organisations :
- Uniform Memory Access (UMA) : les processeurs ont le même temps d'accès à la mémoire par l'intermédiaire d'un seul bus par exemple (bus-based)
- Non-Uniform Memory Access (NUMA) : les processeurs disposent d'une partie de mémoire locale ce qui permet de diminuer le temps d'accès à certaines données
- Cache Only Memory Architecture (COMA) : la mémoire centrale est utilisée comme cache
- Cache Coherent NUMA (ccNUMA) :
- No Remote Memory Access (abbreviated as NoRMA) : the memory is not globally accessible by the processors. Accesses to remote memory modules are only indirectly possible by messages through the interconnection network to other processors, which in turn possibly deliver the desired data in a reply message. The entire storage configuration is partitioned statically among the processors
1.6.1.a Exemple taurus
Cas du cluster taurus du LERIA qui dispose de Racks Bull Novascale R422 composés de deux Xeon E5 2670 v2

- 10 coeurs + 10 HT, soit 20 threads, multiplié par 2 CPU : 40 threads
- jusqu'à 32 Go de mémoire centrale
1.6.1.b Exemple Gigabyte
Voici un autre exemple Gigabyte G492 ZD0 Server dont l'architecture est la suivante :

1.6.2. Mémoire distribuée
Pour connecter les processeurs et leurs mémoires on crée un réseau d'interconnexions qui peut prendre plusieurs formes : carré, grille à deux dimensions, arbre, hypercube, ...
On parle également de Message-Passing MIMD Architecture
1.7. Problèmes rencontrés
Ce sont les mêmes que lors des accès concurrentiels.
1.8. Solutions de parallélisation
Voici une liste non exhaustive des solutions de parallélisation :
1.8.1. Sur un seul processeur ou un SMP (systèmes à mémoire partagée)
- bas niveau :
- haut niveau :
1.8.2. Entre plusieurs processeurs sur différentes machines (systèmes à mémoire distribuée)
- PVM : est un ensemble de bibliothèques logicielles et outils libres de communication (langages C et Fortran) pour machines parallèles et réseaux d'ordinateurs (locaux ou distants, éventuellement hétérogènes). Il permet d’agréger un réseau d'ordinateurs en un seul ordinateur virtuel permettant ainsi d'augmenter la concurrence des calculs. PVM a été graduellement remplacé par MPI.
- MPI (Message Passing Interface) : communication entre machines grâce à l'envoi de messages pour échanger de l'information. Notons que MPI fonctionne également sur les systèmes à mémoire distribuée mais sera moins efficace que OpenMP.
1.8.3. Autres alternatives similaires à OpenMP
- Intel Cilk Plus : is an extension to C and C++ that offers a quick and easy way to harness the power of both multicore and vector processing
- OpenACC pour Open Accelerators permet l'ajout de commandes dans du code source C, C++ et Fortran pour identifier des portions qui pourraient bénéficier d'une accélération, en utilisant des directives du compilateur. Comme en OpenMP 4.0 et suivant, le code peut être exécuté sur CPU et GPU.
Enfin, il existe des solutions de très haut niveau comme StarPU (INRIA) qui se définit comme : a runtime system that offers support for heterogeneous multicore architectures.
1.9. Super calculateurs et High Performance Computing
Un autre aspect de la parallélisation est le HPC (où High Performance Computing) très en vogue depuis quelques années et qui consiste à concevoir et utiliser de manière efficace un ensemble de machines/processeurs afin de réduire le temps d'exécution d'un calcul complexe.
Le calcul haute performance a pour objectif d'atteindre les plus hautes performances possibles en terme de calcul avec des technologies de pointe. Les machines qui résultent de la conception basée sur ce principe sont qualifiées de superordinateurs ou supercalculateurs (super computers). L'activité scientifique chargée de concevoir et programmer ces superordinateurs est appelée Calcul Haute Performance ou HPC en anglais pour High Performance Computing.
La puissance des supercalculateurs est exprimé en Flops (Floating Point Operations per Second) car la plupart des applications susnommées utilisent les nombres réels pour représenter des coordonnées dans l'espace, des distances, des forces, des énergies, ... On utilise le test LINPACK (Résolution de systèmes d'équations linéaires) pour évaluer la puissance des supercalculateurs.
Différentes barrières ont été atteintes au cours du temps :
- 1964 MégaFLOPS ($10^6$ FLOPS) Control Data 6600 (USA)
- 1985 GigaFLOPS ($10^9$ FLOPS) Cray-2 (USA)
- 1997 TéraFLOPS ($10^12$ FLOPS) ASCI Red (USA) avec près de 9300 Intel Pentium Pro 200 Mhz
- 2008 PétaFLOPS ($10^15$ FLOPS) Roadrunner (USA) (6 480 dual core Opteron d'AMD, 12 960 processeurs Cell d'IBM)
On parle également à présent de l'Exascale Computing pour le passage à l'ExaFlop ($10^18$ Flops) prévu (initialement pour 2020) pour 2022 pour la plupart des grandes puissances (Europe, Chine, Japon, USA, Inde).
Les organismes de recherche civils et militaires comptent parmi les utilisateurs de superordinateurs qui sont destinés aux principaux domaines suivants :
- calcul des prévisions météorologiques, étude du climat
- bioinformatique, modélisation moléculaire (calcul des structures 3D des protéines, phylogénie, interaction de gènes, ...)
- simulations physiques (simulations aérodynamiques, résistance des matériaux, simulation d’explosion d’arme nucléaire, étude de la fusion nucléaire, interaction et modélisation spatiale)
- cryptanalyse
- outil d'aide à la décision pour l'exploitation et la gestion des champs pétrolifères (Total, Pangea)
- ...
Le site top500.org recense les superordinateurs les plus puissants.
- en juin 2015, le superordinateur le plus puissant est le Tianhe-2 (Chine) avec une puissance de 33,86 PetaFlops
- en juin 2016, le superordinateur le plus puissant est le Sunway TaihuLight (Chine) avec une puissance de 93 PetaFlops
- en novembre 2021, c'est le Fugaku (Japon) avec 442 PFlops qui est le premier de la liste
On peut également comparer le rapport puissance / nombre de coeurs. Notamment dans la table suivante la colonne estimation correspond à la puissance en PFlops si on utilisait le nombre de coeurs du SunWay TaihuLight. Par exemple $595 = (10649600/560640) × 31,37$
| Système | Rang | Puissance (GFlops) |
Coeurs | Ratio (P/C) | Estimation (PFlops) |
| Sunway TaihuLight | 1 | 93.014.600 | 10.649.600 | 8.73 | 93 |
| Tianhe-2 | 2 | 33.862.700 | 3.120.000 | 10.85 | 37 |
| Titan | 3 | 17.590.000 | 560.640 | 31.37 | 595 |
Le site green500.org recensait, quant à lui, les superordinateurs consommant le moins d'énergie. Il a été intégré au site top500.org
1.9.0.a quelques exemples de supercalculateurs
Voici quelques extraits du dossier complet publié sur Tomshardware.com concernant le sujet :
- Le classement TOP500 fut publié pour la première fois en juin 1993. A cette époque, le plus puissant ordinateur du monde était un CM5, fabriqué par Connection Machines, installé au Los Alamos National Laboratory, un laboratoire de l'Université de Californie géré par le ministère de l'énergie américain. Le CM5/1024 était composé de 1024 processeurs SuperSparc à 32 MHz. Sa puissance théorique était de 131 GFlops, mais il atteignait moins de la moitié (59,7 GFlops) sous le benchmark LINPACK
- Le Tianhe-1 (Voie Lactée) est un supercalculateur du National Supercomputing Center, à Tianjin en Chine. En octobre 2010, une version améliorée de la machine (Tianhe-1A) est devenue le supercalculateur le plus rapide au monde : Processeurs Intel Xeon (14366) + GPU NVIDIA Tesla M2050 (7166).
- Après trois ans de domination le supercalculateur chinois Tianhe-2 a enfin perdu sa première place au TOP500. Il a été détrôné par un compatriote, Sunway TaihuLight. Ce nouveau supercalculateur chinois est extraordinaire a plus d’un titre. D’abord parce qu’il développe 125 Pflops de puissance brute et 93 Pflops en pratique sous Linpack. C’est presque trois fois plus que le Tianhe-2. Son rendement est de 6 GFlops/W, ce qui le place parmi les 3 meilleurs supercalculateurs au monde. De manière remarquable, ces excellents résultats sont obtenus par des puces entièrement conçues et fabriquées en Chine. Le Sunway TaihuLight compte 40960 processeurs ShenWei SW26010, chacun dotés de 260 cœurs RISC 64 bits à 1,45 GHz - soit tout de même 10,6 millions de coeurs.
- Octobre 2012, Le Titan (Oak Ridge National Laboratory, USA, Tennessee) : On passe donc à 18 688 cartes Telsa K20 (a priori), soit 28 704 768 unités de calcul sur le GPU, et 18 688 Opteron 6274, des modèles « Bulldozer » dotés de 16 cores (plus exactement 8 cores et 16 modules), soit 299 008 threads. Il est doté de 710 To de mémoire et sa consommation devrait être de 9 mégawatts environ, soit à peine plus que l'itération précédente du supercalculateur — c'est une simple mise à jour — pour une puissance théorique multipliée par 10 environ.
La machine offre une puissance théorique qui dépassera 20 pétaflops et environ 90 % de la puissance de calcul vient des cartes Tesla (source Tomshardware.com, voir également l'article d'Anandtech) - Depuis la fin 2015, une nouvelle machine est installée au CEA : le Tera 1000. Ce supercalculateur doit offrir à terme (en 2017) une puissance de calcul de 25 Pflops.