Table des matières
- 1. Introduction et Historique
- 2. Programmer avec CUDA
- 3. Le Modèle Logique
- 4. Le Modèle Physique
- 5. Thrust & CUME
- Bibliographie et sitographie
4. Modèle physique
4.1. Introduction
Décrire l'architecture d'un GPU n'est pas chose aisée car les informations relatives à l'architecture laissent souvent place à la confusion ou à des interrogations.
Un GPU est un système très spécifique qui n'offre que peu de marge de manoeuvre en terme de configuration. A l'opposé un CPU lié à une mémoire centrale offre des avantages et notamment dans le cas de code ou apparaissent de nombreux branchements. Pour des problèmes ou le parallèlisme est évident et les branchements sont peu nombreux, l'usage du GPU se révèle beaucoup plus intéressant et peut apporter un facteur de performance parfois très important.
Le GPU GeForce 8800 de NVidia, introduit en novembre 2006, basé sur le chipset G80 (Tesla), a donné naissance à un nouveau mode de programmation des GPU et a apporté plusieurs innovations majeures :
- support du langage C pour la programmation GPU
- remplacement des vertex et pixel pipelines avec un seul processeur unifié
- introduction du mode d'exécution SIMT (Single-Instruction Multiple-Thread)
- introduction de la mémoire partagée et de la synchronisation des threads
L'ensemble de ces technologies ont été regroupées sous l'appellation CUDA pour Compute Unified Device Architecture. CUDA est l'architecture logicielle et matérielle qui permet aux GPU NVidia d'exécuter des programmes écrits en C, C++, Fortran, OpenCL, DirectCompute, ainsi que d'autres langages.
- en juin 2008, NVidia introduisit une révision majeure de l'architecture G80, l'architecture GT 200 (introduite dans les GPU : GeForce GTX 280, Quadro FX, 5800, and Tesla T10) qui augmenta le nombre de SM (Streaming Processors) de 128 à 240.
- en 2010, NVidia introduit l'architecture Fermi qui apporte de nombreuses améliorations par rapport à G80/GT200.
- en mars 2012, c'est l'architecture Kepler qui voit le jour avec la GeForce GTX 680 (GK 104).
- en février 2014, l'architecture Maxwell apparaît avec la GeForce GTX 750 (GM 107)
- en 2016, Pascal introduit la mémoire 3D (ou Stacked RAM) qui doit délivrer une bande passante de l'ordre du Tera octet/s ainsi que le calcul réel en 16 bits qui est suffisant pour certaines applications liées à l'apprentissage ou le traitement des images
- en 2017, on passe à l'architecture Volta
- en 2018, NVidia lance l'architecture Turing qui intègre la technique de lancer de rayon.
- en 2020, nait l'architecture Ampère
- en 2022, c'est au tour de l'architecture Ada de voir le jour
4.2. Compute capability
4.2.1. Définition
NVidia classe ses GPU compatibles CUDA par capacité de calcul (Compute Capability) qui a une influence sur les performances de chaque GPU.
| C.C. | GPUs | Exemples de Carte |
| 1.0 | G80, ... | GeForce 8800GTX, 9600GT, 9800GT |
| 1.1 | G86, ... | GeForce 8400GS/GT, 8600GT/GTS |
| 1.2 | GT218, ... | GeForce 210, GT 220/40 |
| 1.3 | GT200, GT200b | GeForce GTX 260 |
| 2.0 | GF100, GF110 | GeForce TX465, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce GT 430, GTX 560 Ti |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 680, GTX 660M |
| 3.5 | GK110 | GeForce GTX 780, 780 Ti, Titan |
| 3.7 | GK201 | Tesla K80 |
| 5.0 | GM107, GM108 | GeForce 930M, 940M, 950M, 960M, GTX 750, 750 Ti |
| 5.2 | GM200, GM204, GM206 | GeForce GTX 950, 960, 970, 980, 980 Ti |
| 5.3 | GM20B | Tegra X1 |
| 6.1 | GP104-200-A1 | GTX 1070 |
| 7.0 | GV100 | |
| 8.0 | GA100 | |
| 8.9 | AD102 | RTX 4090 |
voir Comparison of Nvidia graphics processing units ou GPUZoo et CUDA GPU.
La liste des caractéristiques des cartes graphiques liées à la COmpute Capability peut être trouvée dans le CUDA Programming Guide (v7.5) notamment dans la section Features and Technical Specifications.
On peut voir notamment que la version 5.3 possède des caractéristiques plus faibles que la version 5.2. Cela est du au fait que la version 5.3 concerne le Tegra X1 qui est une architecture pour les produits embarqués.
| Compute Capability | 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.5 | 5.0 |
| SM Version | sm_10 | sm_11 | sm_12 | sm_13 | sm_20 | sm_21 | sm_30 | sm_35 | sm_50 |
| Threads / Warp | 32 | 32 | 32 | 32 | 32 | 32 | 32 | 32 | 32 |
| Warps / Multiprocessor | 24 | 24 | 32 | 32 | 48 | 48 | 64 | 64 | 64 |
| Threads / Multiprocessor | 768 | 768 | 1024 | 1024 | 1536 | 1536 | 2048 | 2048 | 2048 |
| Thread Blocks / Multiprocessor | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 16 | 32 |
| Max Shared Memory / Multiprocessor (bytes) | 16384 | 16384 | 16384 | 16384 | 49152 | 49152 | 49152 | 49152 | 49152 |
| Register File Size | 8192 | 8192 | 16384 | 16384 | 32768 | 32768 | 65536 | 65536 | 65536 |
| Register Allocation Unit Size | 256 | 256 | 512 | 512 | 64 | 64 | 256 | 256 | 256 |
| Allocation Granularity | block | block | block | block | warp | warp | warp | warp | warp |
| Max Registers / Thread | 124 | 124 | 124 | 124 | 63 | 63 | 63 | 255 | 255 |
| Shared Memory Allocation Unit Size | 512 | 512 | 512 | 512 | 128 | 128 | 256 | 256 | 256 |
| Warp allocation granularity (for registers) | 2 | 2 | 2 | 2 | 2 | 2 | 4 | 4 | 4 |
| Max Thread Block Size | 512 | 512 | 512 | 512 | 1024 | 1024 | 1024 | 1024 | 1024 |
| Shared Memory Size Configurations (bytes) | 16384 | 16384 | 16384 | 16384 | 49152 | 49152 | 49152 | 49152 | 65536 |
Lien vers CUDA Occupancy Calculator
4.2.2. Obtention des caractéristiques du GPU
CUDA C définit les structures et méthodes permettant d'accéder aux caractéristiques du GPU (cd documentation Runtime API) :
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
struct cudaDeviceProp {
char name[256];
size_t totalGlobalMem; // memory size in bytes
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock; // maximum number of threads/block
int maxThreadsDim[3];
int maxGridSize[3];
size_t totalConstMem;
int major; // Compute capability (ex. 5 for 5.0)
int minor; // Compute capability (ex. 0 for 5.0)
int clockRate;
size_t textureAlignment;
int deviceOverlap;
int multiProcessorCount;
int kernelExecTimeoutEnabled;
int integrated;
int canMapHostMemory;
int computeMode;
....
}
On fournit en paramètre de la fonction cudaGetDeviceProperties une structure de type cudaDeviceProp ainsi qu'un identifiant numérique de la carte graphique : 0 pour la première carte graphique, 1 pour la seconde, ...
cudaDeviceProp device;
if (cudaGetDeviceProperties( &device, 0 ) == cudaErrorInvalidDevice) exit(1);
cout << "Grid Size = ";
cout << device.maxGridSize[0] << " x ";
cout << device.maxGridSize[1] << " x ";
cout << device.maxGridSize[2] << ;
Pour obtenir le nombre de cartes graphiques, on utilise la fonction :
cudaError_t cudaGetDeviceCount(int *count);
Il existe un certain nombre d'autres fonctions pour choisir les cartes :
- cudaError_t cudaSetDevice(int device) : choix de la carte
- cudaError_t cudaChooseDevice(int *device, const struct cudaDeviceProp *prop) : choix de la carte qui se rapproche le plus des propriétés fournies en paramètre
- cudaError_t cudaGetDevice(int *device) : retourne la carte utilisée
4.3. Eléments architecturaux : organisation modulaire
4.3.1. Une architecture adaptative (scalable)
This scalable programming model allows the GPU architecture to span a wide market range by simply scaling the number of multiprocessors and memory partitions: from the high-performance enthusiast GeForce GPUs and professional Quadro and Tesla computing products to a variety of inexpensive, mainstream GeForce GPUs.
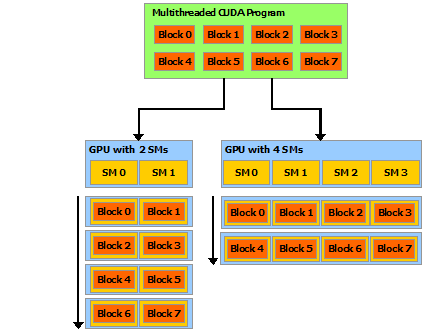
The NVIDIA GPU architecture is built around a scalable array of multithreaded Streaming Multiprocessors (SMs). When a CUDA program on the host CPU invokes a kernel grid, the blocks of the grid are enumerated and distributed to multiprocessors with available execution capacity. The threads of a thread block execute concurrently on one multiprocessor, and multiple thread blocks can execute concurrently on one multiprocessor. As thread blocks terminate, new blocks are launched on the vacated multiprocessors.
4.3.2. Warp et half-warp
Avec CUDA, un groupe de 32 threads consécutifs est appelé un warp (terme issu des métiers à tisser, en français : fils de chaîne ou trame). Les threads d'un warp sont exécutés en parallèle sur le même SM.
The multiprocessor creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps. Individual threads composing a warp start together at the same program address, but they have their own instruction address counter and register state and are therefore free to branch and execute independently. The term warp originates from weaving, the first parallel thread technology. A half-warp is either the first or second half of a warp. A quarter-warp is either the first, second, third, or fourth quarter of a warp.
Un tissu est formé du croisement de deux ensembles de fils : la chaîne et la trame. Les fils de chaîne sont tendus sur le métier à tisser Avec la (ou les) navette, on fait passer le fil de trame alternativement au-dessus et au-dessous des fils de chaîne.
Avec les architectures plus anciennes (G80, GT200), c'est seulement 16 threads (half warp) qui étaient exécutés par cycle d'horloge. Il fallait donc 2 cycles d'horloges pour exécuter un warp. De la même manière des instructions envoyées au SFU bloquaient l'exécution d'autres instructions.
Avec GF100, les explications concernant l'exécution du warp ne sont pas claires :
The SM schedules threads in groups of 32 parallel threads called warps. Each SM features two warp schedulers and two instruction dispatch units, allowing two warps to be issued and executed concurrently. Fermi’s dual warp scheduler selects two warps, and issues one instruction from each warp to a group of sixteen cores, sixteen load/store units, or four SFUs. Because warps execute independently, Fermi’s scheduler does not need to check for dependencies from within the instruction stream.
Avec Fermi on dispose de deux unités de répartition des instructions (dispatch units). Chaque unité peut lancer l'exécution d'un half-warp à chaque cycle. Les threads peuvent appartenir à différents warps de manière à avoir un maximum d'opérations indépendantes.
Cependant, chaque thread du warp doit exécuter la même instruction.
| Fermi | FP32 | FP64 | INT | SFU | LD/ST |
| Ops par cycle | 32 | 16 | 32 | 4 | 16 |
4.3.2.a divergence au sein d'un warp : if
Les structures de contrôle conditionnelles (if) peuvent impacter de manière significative l'efficacité de l'exécution. En effet, lors d'un if les parties then et else sont exécutées, cependant seule la partie concernées sera validée (écriture du résultat, évaluation d'adresse, lecture d'opérande, ...).
Avec $N$ if imbriqués on peut rencontrer un ralentissement de l'ordre de $2^N$.
A warp executes one common instruction at a time, so full efficiency is realized when all 32 threads of a warp agree on their execution path. If threads of a warp diverge via a data-dependent conditional branch, the warp serially executes each branch path taken, disabling threads that are not on that path, and when all paths complete, the threads converge back to the same execution path. Branch divergence occurs only within a warp; different warps execute independently regardless of whether they are executing common or disjoint code paths.
4.3.2.b objectif des SM : diminuer les temps de latence
La manière pour un GPU de diminuer les latences liées au calcul des ALU/SFU et l'accès mémoire, consiste à gérer plusieurs WARPs et exécuter la prochaine instruction de ceux qui sont prêts à être exécutés. On parle alors de TLP où Thread Level Parallelism, il faut donc faire en sorte d'augmenter le TLP d'un SM.
La notion d'occupancy (que l'on peut traduire par occupation ou activité en français) est définie comme le rapport du nombre de warps affectés à un SM divisé par le nombre maximum de warps que peut gérer un SM. Plus cette valeur est proche de 1.0, plus on peut diminuer les temps de latences de la mémoire et des circuits de calcul.
4.3.2.c l'ILP : augmenter la performance en diminuant le TLP
Paradoxalement, disposer d'une occupancy proche de 1.0 (soit 100 %) ne se traduit pas forcément par un temps de calcul plus faible dans certains cas.
l'ILP ou Instruction Level Parallelism joue également un rôle, cette notion est liée au nombre de registres dont disposent les SP.
4.3.3. Architecture Fermi (2010)
La première architecture Fermi était composée de 512 coeurs organisés sous forme de 16 SM (Streaming Multiprocessors) composé chacun de 32 coeurs.
Le GPU possède 6 partitions mémoire de 64-bits doté d'un bus d'une largeur de 384 bits, capable de supporter un maximum de 6 Go de GDDR5 DRAM.
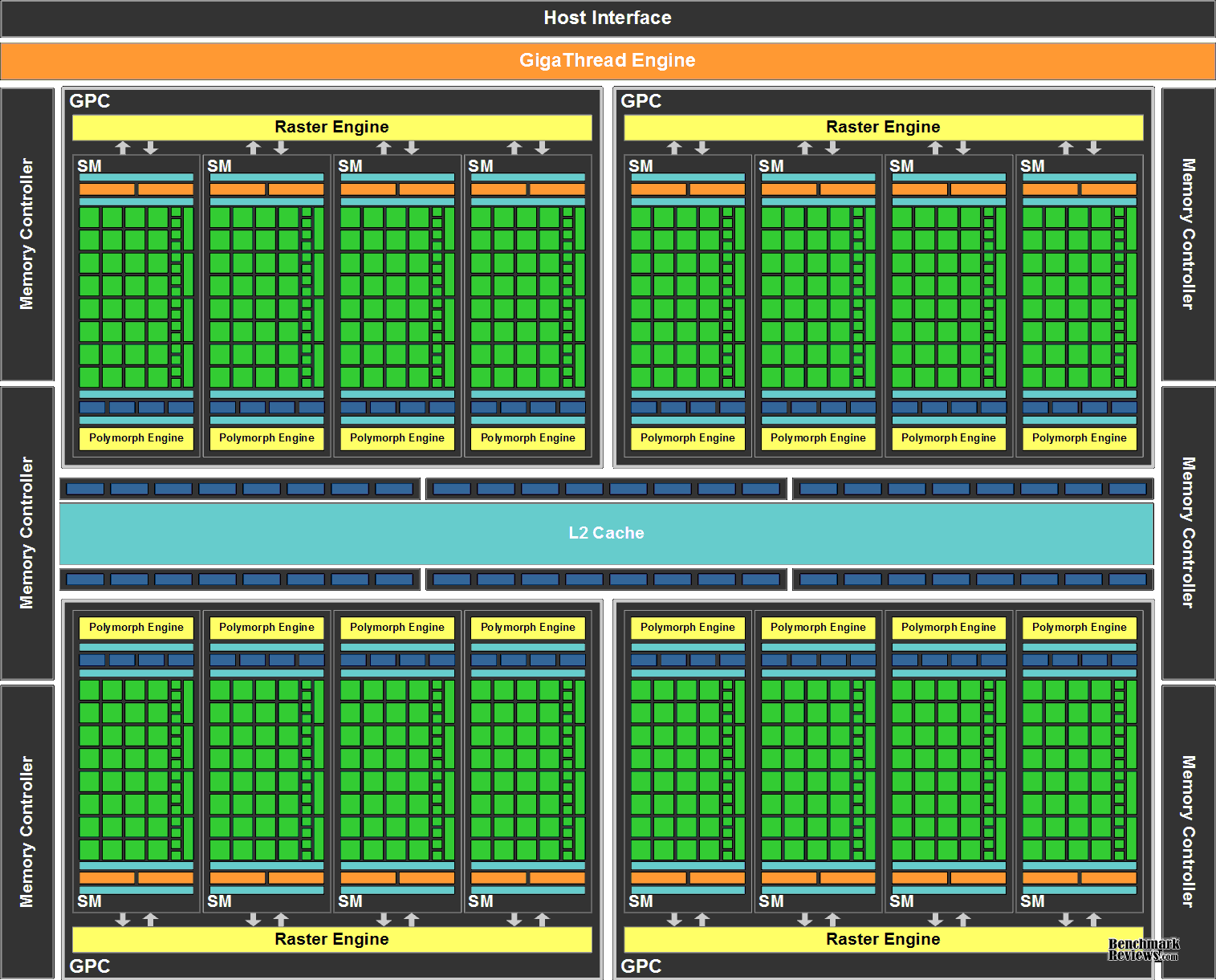
4.3.3.a Fermi Streaming Multiprocessor (SM)
Le Multiprocesseur traite des blocs de threads, pour cela il est doté de :
- 32 CUDA cores (soit 4x plus que le GT200)
- 64 ko de mémoire cache L1 + mémoire partagée configurable
- 16 unités load/store qui permettent le calcul de l'adresse source ou destination pour 16 threads par cycle d'horloge
- 4 SFU (Special Function Units) chargées du calcul des fonctions réelles complexes comme sinus, cosinus, logarithme, ...
Ce qui lui permet d'atteindre 8x plus de performance que le GT 200
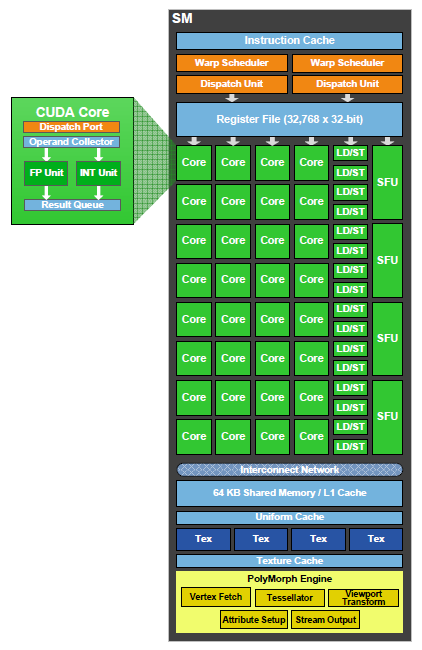
4.3.3.b Fermi Streaming Processor (SP)
Chaque coeur CUDA (appelé Streaming Processor) possède des unités de traitement pour les entiers (ALU) et les réels (FPU).
Les GPU plus anciens utilisaient la norme de calcul IEEE 754-1985, l'architecture Fermi utilise la norme IEEE 754-2008 qui comporte l'opération FMA (Fused Multiply-Add) pour la simple et double précision.
L'intérêt du FMA par rapport à la méthode MAD (Multiply-Add) est qu'elle effectue la multiplication et l'addition avec une seule étape finale d'arrondi sans perte de précision pour l'addition. Dans les deux cas on calcule $A × B + C$
4.3.4. Architecture Kepler (2012)
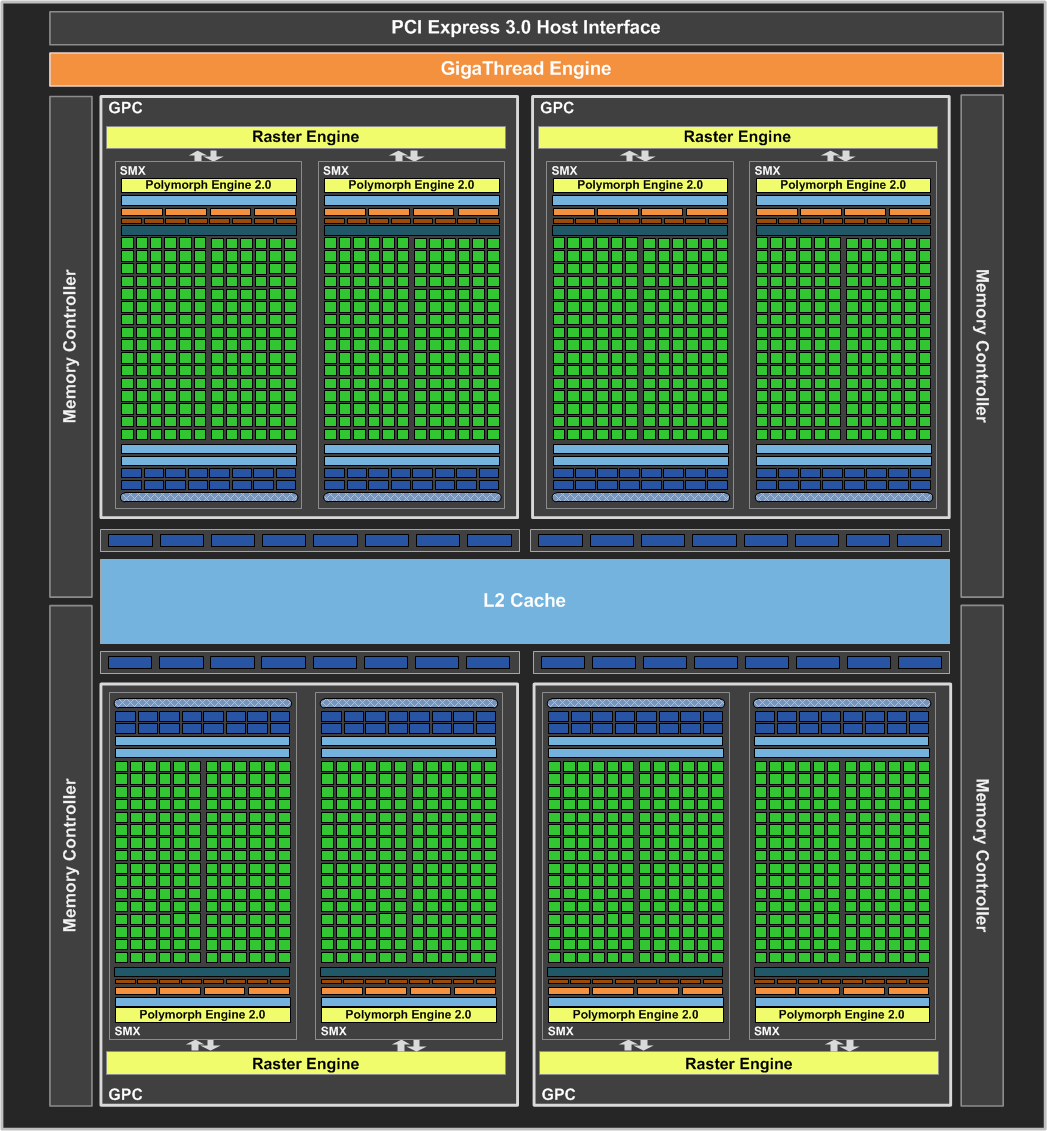
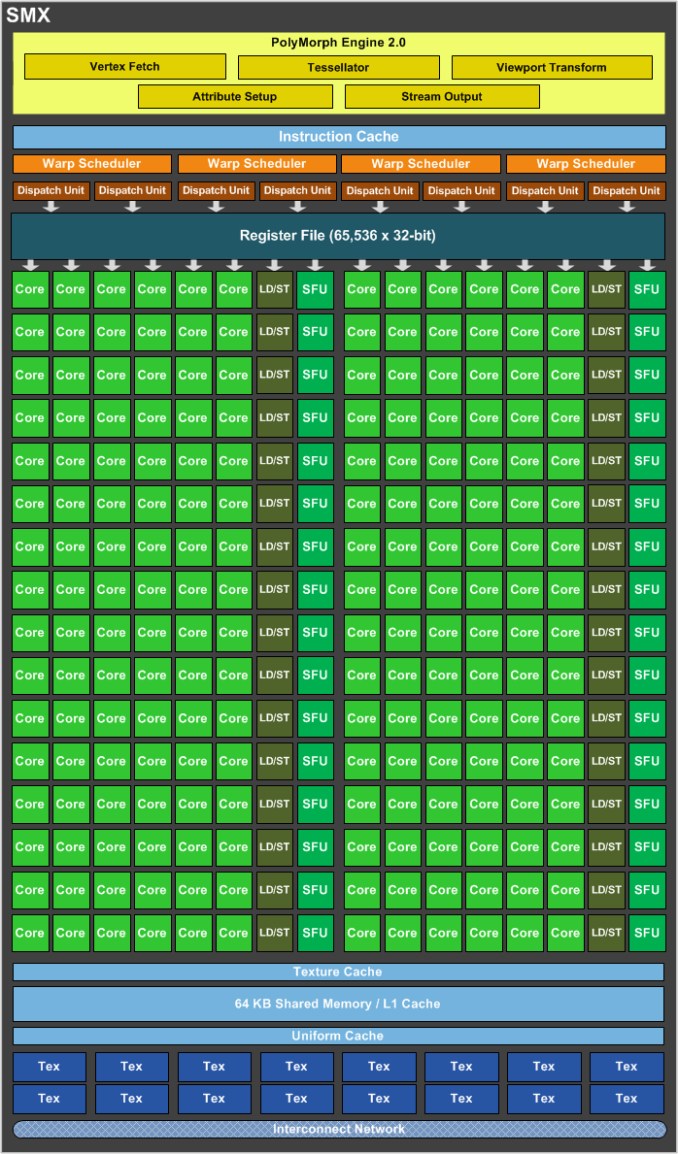
4.3.4.a Kepler Next Generation Streaming Multiprocessor (SMX)
Each of the Kepler GK110/210 SMX units feature 192 single-precision CUDA cores
Each SMX features four warp schedulers and eight instruction dispatch units, allowing four warps to be issued and executed concurrently. Kepler’s quad warp scheduler selects four warps, and two independent instructions per warp can be dispatched each cycle. Unlike Fermi, which did not permit double precision instructions to be paired with other instructions, Kepler GK110/210 allows double precision instructions to be paired with other instructions.
4.3.5. Architecture Maxwell (2014)
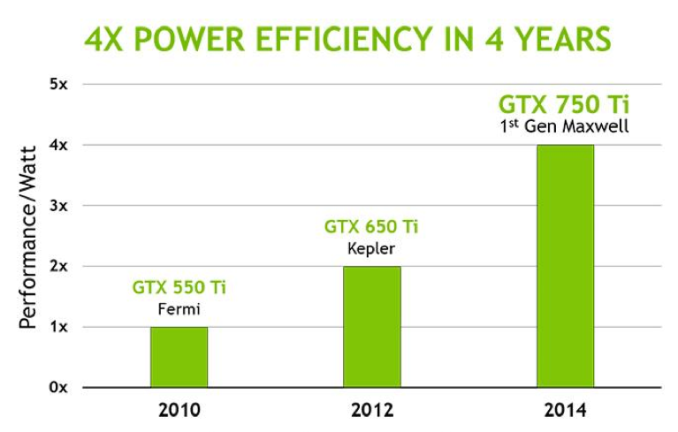
Les premières cartes estampillées Maxwell furent la GeForce 750 (512 cores) et 750 Ti (640 cores).
L'architecture Maxwell a été pensée pour améliorer :
- l'efficacité énergétique : dépenser le moins d'énergie
- la performance par watt : pour 1 Watt, on augmente le nombre de Flops
- l'espace occupé par les circuits : diminution de la taille
Maxwell introduces an all-new design for the Streaming Multiprocessor (SM) that dramatically improves energy efficiency. Although the Kepler SMX design was extremely efficient for its generation, through its development, NVIDIA's GPU architects saw an opportunity for another big leap forward in architectural efficiency; the Maxwell SM is the realization of that vision.
Tuning Applications for Maxwell - DA-07173-001_v6.0 | February 2014
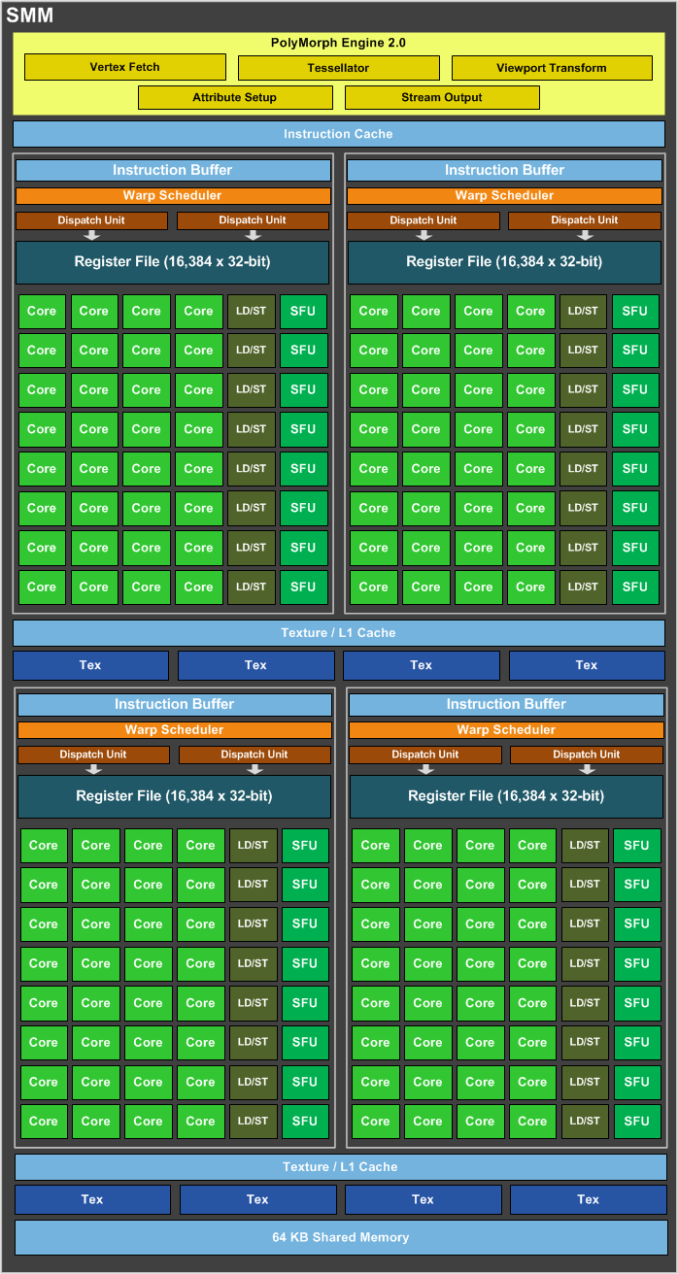
4.3.5.a Maxwell Streaming Multiprocessor (SMM)
Les SM Maxwell sont composées de 128 cores répartis en quatre blocs de 32 cores.
L'espace occupé par le SMM de 128 cores est plus petit que pour Kepler et délivre 90% de la performance des 192 cores d'un SMX.
4.3.6. Architecture Pascal (2016)
The first product based on the Pascal architecture is the NVIDIA Tesla™ P100 accelerator. With an 18 billion transistor Pascal GPU, NVIDIA NVLINK™ high performance interconnect that greatly accelerates GPU peer-to-peer and GPU-to-CPU communications, and exceptional power efficiency based 16nm FinFET technology, the Tesla P100 is not only the most powerful, but also the most advanced GPU accelerator ever built. (Source NVidia)
Par exemple la GeForce GTX 1080 (GP104) est composée de 4 GPCs, 20 Pascal Streaming Multiprocessors (SM), et 8 controlleurs mémoire.
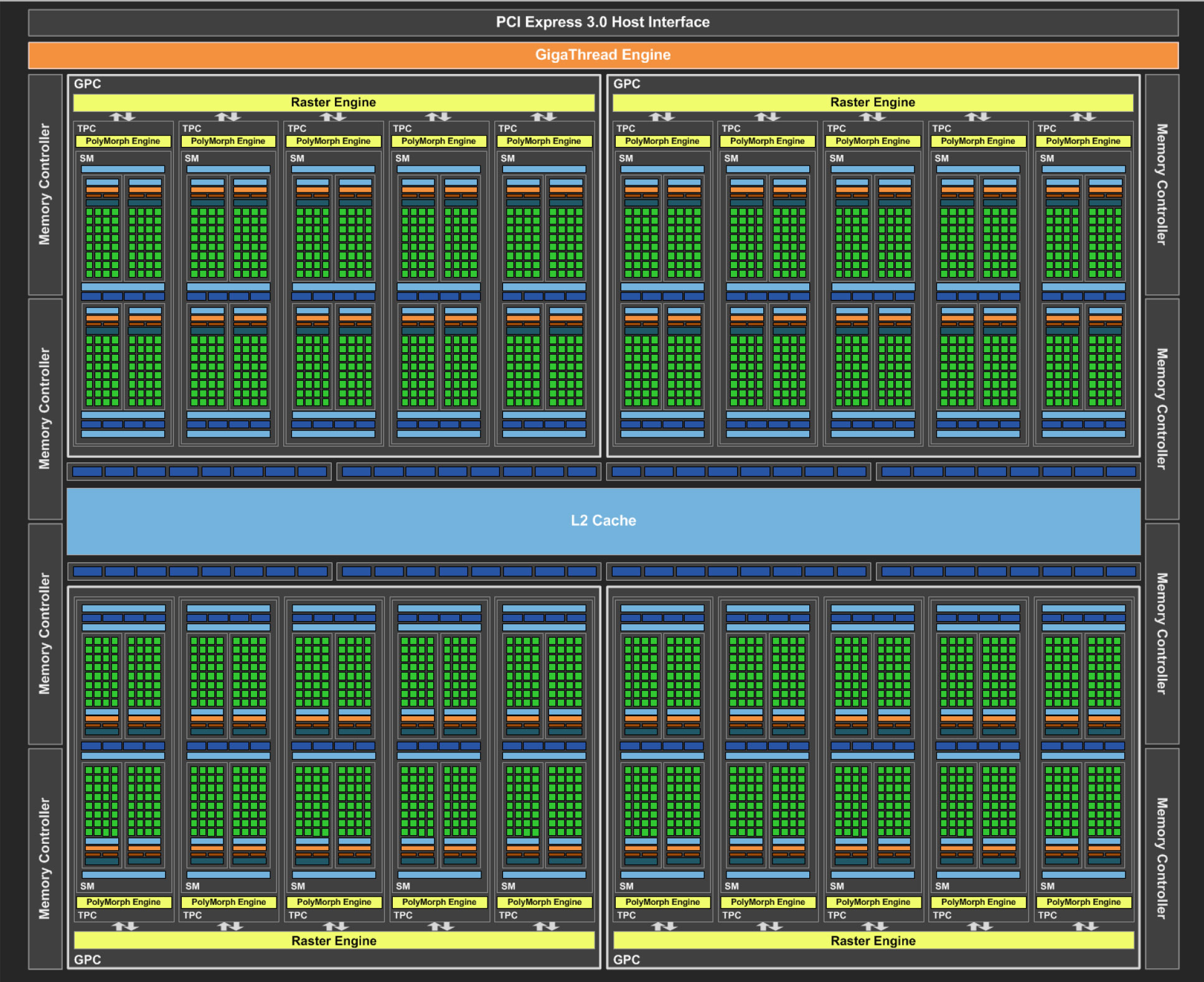
Chaque SM contient 128 CUDA cores, 256 Ko de registres, 96 Ko de mémoire partagée, 48 Ko de L1 cache et 8 unités de texture.

Avec 20 SMs, la GeForce GTX 1080 contient 2560 CUDA cores et 160 unités de texture.
4.3.7. Architecture Volta (2017)
En Mai 2017 apparait le premier GPU Volta Tesla V100 (GV100) de Compute Capability (CC) de niveau 7. Parmi les propriétés caractéristiques de cette nouvelle architecture on notera :
- New Streaming Multiprocessor (SM) Architecture Optimized for Deep Learning Volta features a major new redesign of the SM processor architecture that is at the center of the GPU. The new Volta SM is 50% more energy efficient than the previous generation Pascal design, enabling major boosts in FP32 and FP64 performance in the same power envelope. New Tensor Cores designed specifically for deep learning deliver up to 12x higher peak TFLOPs for training. With independent, parallel integer and floating point datapaths, the Volta SM is also much more efficient on workloads with a mix of computation and addressing calculations
- HBM2 Memory: Faster, Higher Efficiency Volta’s highly tuned 16GB HBM2 memory subsystem delivers 900 GB/sec peak memory bandwidth. The combination of both a new generation HBM2 memory from Samsung, and a new generation memory controller in Volta, provides 1.5x delivered memory bandwidth versus Pascal GP100 and greater than 95% memory bandwidth efficiency running many workloads.
Les puissances de calcul du GPU Tesla V100 (basé sur le GPU Boost clock rate) sont les suivantes :
- 7.5 TFLOP/s en double précision floating-point (FP64)
- 15 TFLOP/s en simple précision (FP32)
- 120 Tensor TFLOP/s précision FP16/32 matrix-multiply-and-accumulate
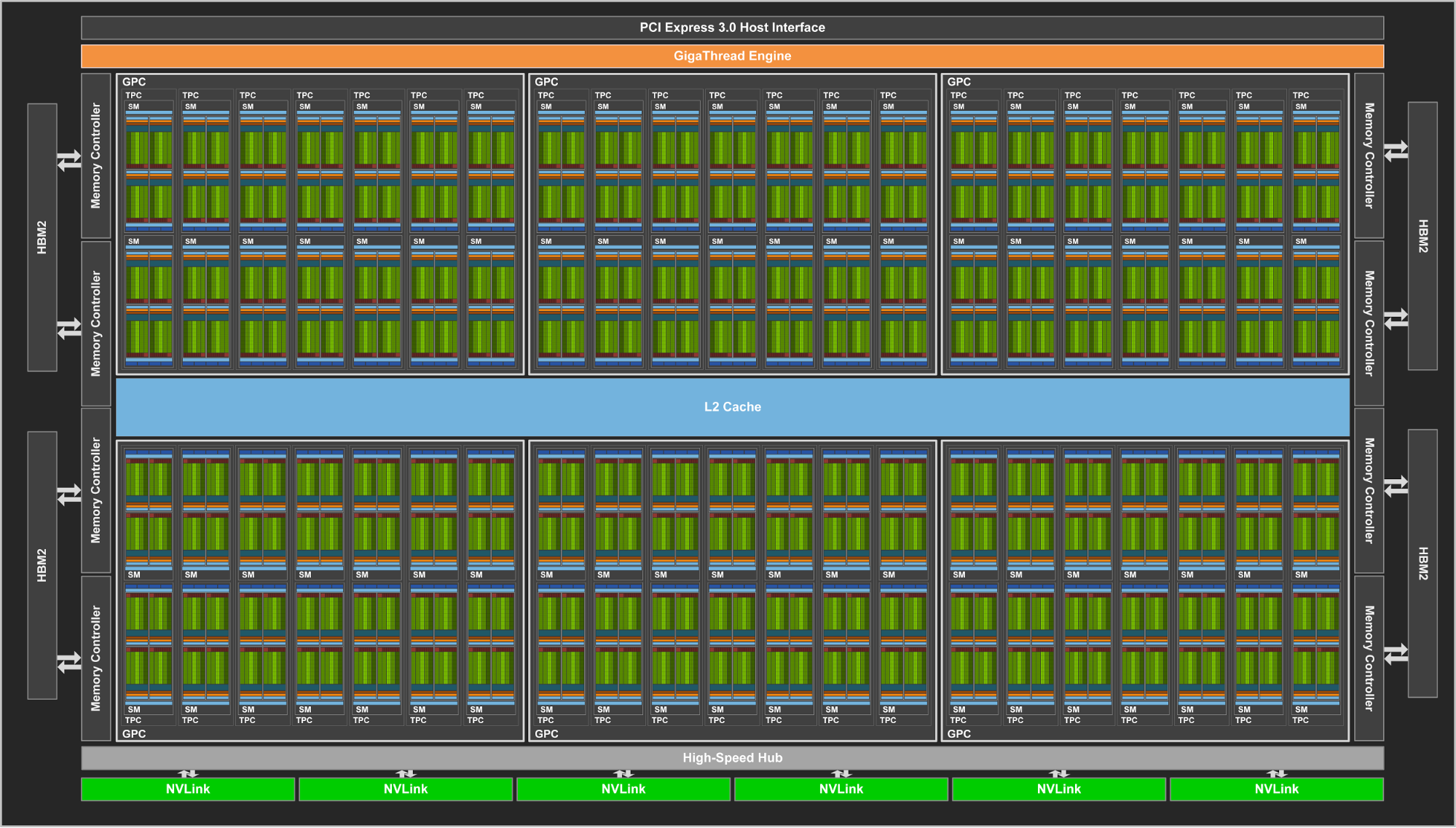
Avec 84 SMs, l'architecture GV100 GPU possède au total:
- 5376 FP32 cores
- 5376 INT32 cores
- 2688 FP64 cores
- 672 Tensor Cores
- 336 unités de texture
Comme l'architecture Pascal GP100, une SM de type GV100 comprend 64 FP32 cores et 32 FP64 cores per SM. Cependant, la SM GV100 utilise une nouvelle méthode de partionnement afin d'améliorer l'utilisation des circuits.
Une SM Pascal GP100 SM est partitionnée en deux blocs chacun ayant 32 FP32 Cores, 16 FP64 Cores, un buffer d'instructions, un ordonnanceur de warp (Warp scheduler), deux unités de répartition (Dispatch units) et 128 Ko de registres.
Une SM GV100 SM comprend 4 blocs de traitement chacun ayant 16 FP32 Cores, 8 FP64 Cores, 16 INT32 Cores, et 2 mixed-precision Tensor Cores pour l'apprentissage (Deep learning). un nouveau cached'instructions L0 utilisé pour améliorer l'efficacité des buffers d'instructions des architectures précédentes.
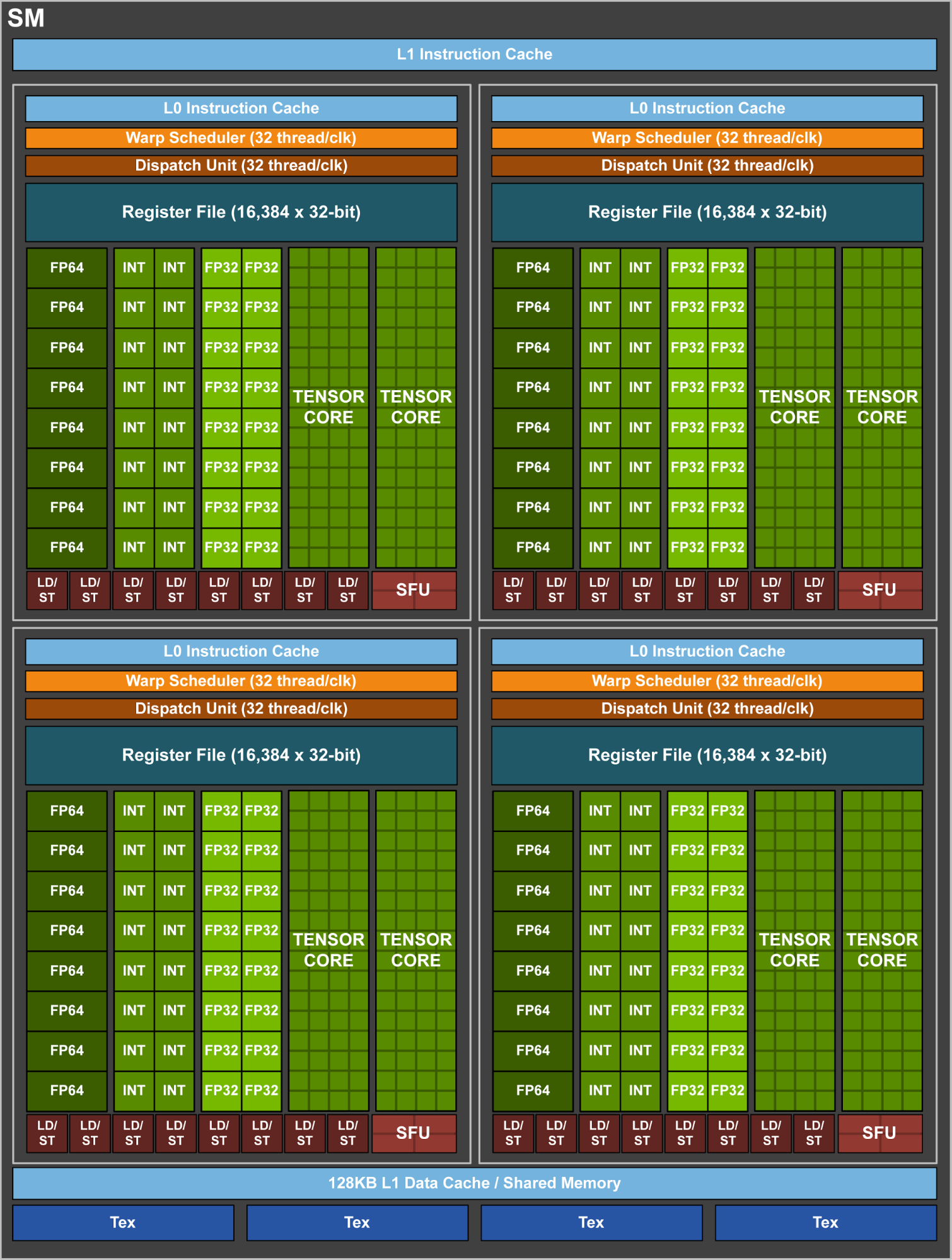
Coeurs Tensors
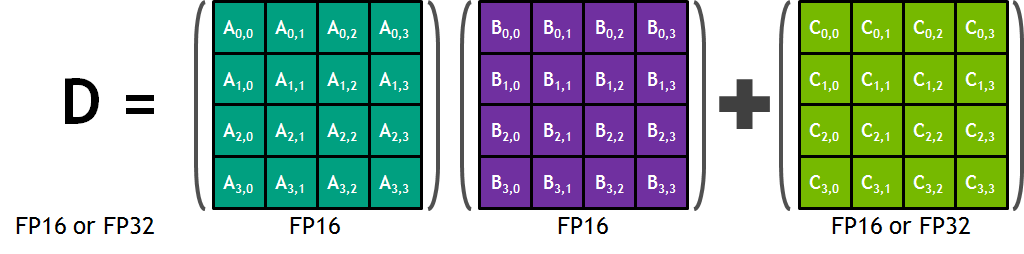
Le produit de matrices (Matrix-Matrix multiplication - BLAS GEMM) est au coeur des dispositifs d'apprentissage des réseaux neuronaux (RN) et est utilisé pour multiplier de grandes matrices (entrées, poids) des couches interconnectées du RN. Les Tensor Cores dans l'architecture Tesla V100 améliorent sensiblement les performances de ces opérations par un facteur 9 comparé à l'architecture Pascal.
Chaque Tensor Core permet la multiplication de matrices $4×4$ afin de calculer rapidement $D = A × B + C$, où $A, B$ sont des matrices $4×4$ de valeurs FP16, alors que $C$ et $D$ sont de type FP16 ou FP32.
Chaque Tensor Core est capable de calculer 64 produits FMA par cycle et donc 8 Tensor Cores dans une SM effectuent un total de $1024$ opérations par cycle (mais $64 × 8 = 512$, donc $× 2$ mais pourquoi ?)
4.3.8. synchronisation des threads
Les threads d'un bloc peuvent synchroniser leur activité en utilisant la fonction __syncthreads(), ce qui permet de s'assurer que les threads ont tous terminé l'exécution d'une même partie de code avant de poursuivre.
Une autre fonction __threadfence() permet la synchronisation des données écrites dans la mémoire globale du GPU de manière à ce que les changements soient visibles pour les autres blocs.
4.3.9. opérations atomiques
Atomic memory operations are important in parallel programming, allowing concurrent threads to correctly perform read-modify-write operations on shared data structures. Atomic operations such as add, min, max, and compare-and-swap are atomic in the sense that the read, modify, and write operations are performed without interruption by other threads. Atomic memory operations are widely used for parallel sorting, reduction operations, and building data structures in parallel without locks that serialize thread execution. Thanks to a combination of more atomic units in hardware and the addition of the L2 cache, atomic operations performance is up to 20× faster in Fermi compared to the GT200 generation.
On dispose d'un certain nombre d'opérations atomiques :
- atomicCAS (int)
- atomicAnd, atomicOr, atomicXor (int)
- atomicAdd (int, float)
- atomicSub, atomicMin, atomicMax, atomicInc, atomicDec (int)
Notamment AtomicCAS est une opération de base :
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsigned int* address,unsigned int compare, unsigned int val);
unsigned long long int atomicCAS(unsigned long long int* address,
unsigned long long
int compare,
unsigned long long int val);reads the 32-bit or 64-bit word old located at the address address in global or shared memory, computes (old == compare ? val : old) and stores the result back to memory at the same address. These three operations are performed in one atomic transaction. The function returns old.
4.3.10. calculs MAD et FMA
Une opération utilisée fréquemment en infographie, algèbre linéaire ou lors de calculs scientifique et l'opération MAD pour Multiply-add qui consiste à multiplier deux nombres puis en ajouter un troisième :
$D = A × B + C$
Cette opération a été implantée de manière très efficace sous forme d'une multiplication tronquée suivie d'une addition avec approximation (multiplication with truncation, followed by an addition with round-to-nearest even).
L'architecture Fermi implante l'opération dite FMA (Fused Multiply-Add) pour les réels simple et double précision qui évite de tronquer les nombres et apporte une meilleure précision.
4.4. Mémoire
Les données qui doivent être traitées en parallèle par les threads sont premièrement transférées depuis la mémoire de l'ordinateur (host memory) vers celle du GPU (global device memory). Malheureusement, travailler uniquement avec la mémoire globale ne permet pas de tirer partie de la puissance totale du GPU car les accès mémoires ont une latence importante (de l'ordre de la centaine de cycles d'horloge) et une bande passante limitée.
Bien que l'ILP (Instruction Level Paralellism) obtenu par les nombreux threads permette de masquer les temps de latence, on peut se retrouver dans une situation de congestion où de nombreux threads ne peuvent progresser ce qui contraint les SM à rester en attente de traitement. Afin d'éviter cet état de congestion, CUDA introduit un certain nombre d'autres méthodes d'accès à la mémoire qui permettent d'éviter les accès à la mémoire globale afin d'améliorer de manière significative les performances du GPU comme figuré sur le schéma suivant :
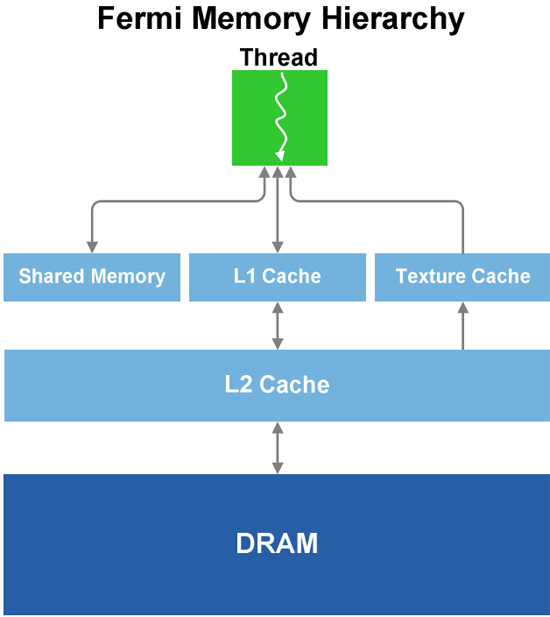
On notera que la bande passante mémoire des registres et de la mémoire partagée est très importante par rapport à celle de la mémoire globale du GPU.
| Type | BP (Go/s) |
| registre | 8000 |
| shared | 1600 |
| globale | 177 |
4.4.1. mémoire globale
La mémoire globale du GPU (Global Memory) est la plus importante et elle varie de 512 ko à 24 Go (Tesla K80 12 Go/GPU en 2015). Elle sert à stocker les données en entrée et sortie des kernels et est off-chip, c'est à dire située sur le PCB (Printed Circuit Board) du GPU mais pas à l'intérieur du circuit de calcul.
Comme pour la programmation traditionnelle avec le CPU, l'alignement mémoire est important et influe sur les performances. Avec CUDA on parle de coalesced memory access, ce que l'on peut traduire en français par accès mémoires voisins ou contigüs. Le fait de ne pas aligner les données peut diviser la bande passante mémoire par un facteur N (4/32=1/8 sous Fermi).
Le fait d'aligner les données est imposé par les warp qui réalisent les accès mémoires en parallèle : si les données sont voisines alors l'utilisation de la bande passante est maximale car on a besoin que d'un seul accès mémoire. Par contre, l'accès à des données non voisines peut mener à une dégradation des performances de telle manière à ce que les accès mémoires soient sérialisés (et non plus parallèles)
Un premier facteur limitatif concerne la bande passante de la mémoire globale. Par exemple pour le G80, la BP est de 86,4 Go/s. Si on transfère des rééls simple précision, la BP est de 86,4/4 = 21,6 Go/s.
Il existe deux types de chargements depuis la mémoire :
- avec cache (caching loads) : il s'agit du mode par défaut, l'accès aux données passe par les deux caches L1, L2 puis la mémoire globale si les données ne résident pas dans les caches
- sans cache (noncaching loads) : lorsque des données doivent être accèdées depuis des adresses non voisines il est préférable d'interdire l'utilisation du cache L1 grâce aux options -Xptxas -dlcm=gc de nvcc
Les lignes de cache ont une taille de 128 octets (soit 32 * 4 octets) ce qui correspond à un warp (32 threads) qui accède à des valeurs 32 bits (entier ou réel simple précision).
4.4.1.a allocation
L'allocation mémoire peut être réalisée de manière statique ou dynamique :
- statique :
__device__ float array_d[200]; - dynamique : l'utilisation de cudaMalloc retourne une adresse multiple de 256
int size = 1024; float *array_d; cudaMalloc((void **)&array_d, 200*sizeof(float)); ... cudaFree(array_d);
4.4.1.b transfert
// eventuellement, redéfinir les constantes CUDA qui sont trop longues
#define H2D cudaMemcpyHostToDevice
#define D2H cudaMemcpyDeviceToHost
// envoi vers le GPU
cudaMemcpy( array_d, array_h, size * sizeof(float), cudaMemcpyHostToDevice);
...
// récupération sur le CPU
cudaMemcpy( array_h, array_d, size * sizeof(float), cudaMemcpyDeviceToHost);4.4.2. Mémoire cache L2
Il s'agit du premier niveau de cache après la mémoire globale, la plupart des données qui transitent entre mémoire globale et thread de calcul sont placées dans ce cache d'un taille de 768 ko sur Fermi.
4.4.3. Mémoire cache L1
On dispose sur l'architecture Fermi d'un cache configurable de 64 ko qui peut être utilisé en tant que cache L1 ou comme mémoire partagée :
- cache L1 de 48 ko + 16 ko de mémoire partagée
- cache L1 de 16 ko + 48 ko de mémoire partagée
Le cache L1 possède des caractéristiques qu'il est préférable de connaître :
- il est conçu pour un accès spatial et non temporel
- les écritures en mémoire globales n'affectent pas le cache L1 (bypass)
- possède une latence de 10 à 20 cycles
4.4.4. Mémoire partagée (shared memory)
La mémoire partagée (Shared Memory ou smem) est commune à un bloc de threads. Un bloc de thread peut donc échanger ou stocker temporairement de l'information afin d'augmenter les performances d'un calcul.
Elle est organisée soit sous forme de 16 ko ou 48 ko par SM comprenant 32 bancs mémoire de 32 bits de manière à ce que 32 threads puissent accéder en parallèle aux données.
La mémoire partagée bénéficie à de nombreux traitements, mais n'est pas appropriée à tous les cas de figure. Certains algorithmes tirent partie de la mémoire partagée alors que d'autres tirent partie d'une hiérarchie de cache comme utilisée par le CPU.
Les conflits d'accès sont les mêmes que pour la mémoire globale, si N threads d'un warp causent un conflit d'accès alors ces derniers seront sérialisés.
La mémoire partagée est capable de diffuser à plusieurs threads une donnée (multicast), par exemple si N threads d'un warp accèdent à la même adresse alors on ne fait qu'un seul accès mémoire.
Les threads n'ont pas besoin de se synchroniser -- __synthreads() -- s'ils sont à l'intérieur d'un warp.
Enfin, si la mémoire partagée est utilisée pour communiquer entre warps d'un même bloc, alors il faut utiliser le préfixe volatile lors de sa déclaration afin d'éviter que le compilateur ne place les données dans des registres :
- compute 1.x : accès direct à la mémoire partagée
- compute 2.0 : possibilité de placer les données dans des registres
La déclaration de la mémoire partagée peut être réalisée de manière statique ou dynamique :
- statique :
__global__ kernel(...) { __shared__ float array_s[64]; ... } - dynamique : taille déclarée lors de l'appel du kernel
__global__ kernel(...) { extern __shared__ float array_s[]; ... } kernel<<<1, 512, 64*sizeof(float)>>>(...);
4.4.5. Mémoire locale
La mémoire locale est une abstraction, il s'agit, suivant l'architecture :
- soit d'une partie de la mémoire globale du GPU (Compute Device < 2.0) : ce qui causait une perte de performance sensible
- ou la mémoire cache L1
Les variables automatiques déclarées dans un kernel sont remplacées par un registre. Cependant le choix entre un registre ou la mémoire locale n'est pas précise, le compilateur peut choisir d'utiliser la mémoire locale dans les cas suivants :
- il n'y a plus de registres disponibles
- une structure serait susceptible d'utiliser trop de registres
- on ne peut pas déterminer si un tableau est indexé avec des valeurs constantes.
Pour en savoir plus.
4.4.6. Mémoire constante
Constant memory is read only from kernels and is hardware optimized for the case when all threads read the same location. Amazingly, constant memory provides one cycle of latency when there is a cache hit even though constant memory resides in device memory (DRAM).
If threads read from multiple locations, the accesses are serialized. The constant cache is written to only by the host (not the device because it is constant!) with cudaMemcpyToSymbol and is persistent across kernel calls within the same application.
Up to 64 ko of data can be placed in constant cache and there is 8 ko of cache for each multiprocessor. Access to data in constant memory can range from one cycle for in cache data to hundreds of cycles depending on cache locality. The first access to constant memory often does not generate a cache "miss" due to pre-fetching
Il existe 64 ko de mémoire constante sur les GPU Fermi et sert à stocker les données qui ne seront pas modifiées.
Ce type de mémoire est mis en cache, le premier accès est donc le plus pénalisant.
Pour tous les threads d'un half-wrap la lecture d'une même constante est aussi rapide qu'un accès à un registre. Par contre, l'accès à des données différentes est sérialisé ce qui est plus pénalisant.
4.4.7. Mémoire de texture
Il s'agit d'une mémoire qui peut agir comme un cache liée généralement aux traitements graphiques et notamment optimisée pour les accès en 2 dimensions. Il y a normalement 8 ko de texture par SM
4.4.8. Les registres
Les registres sont une ressource limitée qui influe sur les performances des kernels.
Pour le G80, chaque SM possède 8192 registres et peut gérer un maximum de 768 threads. Si on utilise de manière optimale chaque SM, chaque thread se voit attribuer un maximum de 8192 / 768 = 10,66 registres. Cependant, si chaque thread utilise plus de 10 registres, le nombre de threads qui peuvent êtres exécutés de manière concurrentielle dans chaque SM sera diminué, on passera par exemple de 768 threads à 512.
Sur Fermi, on dispose de 32 k (32768) registres. Si on utilise l'ensemble des threads, soit 1536, on disposera de 32768/1536 = 21 registres par thread. par défaut, le nombre maximum de registres associés à un thread est de 63.
4.4.9. Pinned memory
La mémoire dite pinned (épinglée) permet, dans certains cas, d'améliorer les transferts mémoires entre CPU et GPU. Elle n'est pas paginée mais vérrouillée (page locked).
Pinned memory is not zero-copy since the GPU cannot access it (it's not mapped in its address space) and it's used to efficiently transfer from the host to the GPU. It's page-locked (valuable kernel resource) memory and has some performance advantages over pageable normal memory.
Host (CPU) data allocations are pageable by default. The GPU cannot access data directly from pageable host memory, so when a data transfer from pageable host memory to device memory is invoked, the CUDA driver must first allocate a temporary page-locked, or “pinned”, host array, copy the host data to the pinned array, and then transfer the data from the pinned array to device memory
int *c_tab; // on CPU
int *g_tab; // on GPU
int main(void) {
int data_size = 1000 * sizeof(int);
// use this instead of malloc(data_size)
cudaHostAlloc( (void**)& c_tab, data_size, cudaHostAllocDefault);
cudaMalloc( (void**)& g_tab, data_size));
// Transfer from CPU to GPU
cudaMemcpy(g_tab, c_tab, data_size, cudaMemcpyHostToDevice);
....
// Transfer from GPU to CPU
cudaMemcpy(c_tab, g_tab, data_size, cudaMemcpyDeviceToHost);
// free memory
cudaFreeHost(c_tab);
cudaFree(g_tab);
return 0
4.4.10. Zero copy
La fonctionnalité zero copy a été ajoutée dans la version 2.2 du Toolkit CUDA et autorise le GPU a accéder à la mémoire de l'host. Il est nécessaire de faire appel à la mémoire mapped pinned (non-pageable).
Du fait que les données ne soient pas mises dans le cache la mémoire mapped pinned ne doit être lue ou écrite qu'une seule fois et il faut que les lectures / écritures des threads soient voisines (coalesced).
La mémoire Zero-copy représente une alternative à l'utilisation des streams
int *c_tab; // on CPU
int *g_tab; // on GPU
int main() {
cudaGetDeviceProperties(&prop, 0);
if (!prop.canMapHostMemory) exit(0);
cudaSetDeviceFlags(cudaDeviceMapHost);
int data_size = 1000 * sizeof(int);
// use this instead of malloc(data_size)
cudaHostAlloc( (void**)& c_tab, data_size, cudaHostAllocMapped);
cudaHostGetDevicePointer(&g_tab, c_tab, 0);
kernel<<<gridSize, blockSize>>>(g_tab);
...
}
cudaMallocHost : can do two things:
- allocate pinned memory: this is page-locked host memory that the CUDA runtime can track. If host memory allocated this way is involved in cudaMemcpy as either source or destination, the CUDA runtime will be able to perform an optimized memory transfer.
- allocate mapped memory: this is also page-locked memory that can be used in kernel code directly as it is mapped to CUDA address space. To do this you have to set the cudaDeviceMapHost flag using cudaSetDeviceFlags before using any other CUDA function. The GPU memory size does not limit the size of mapped host memory.
4.4.11. En pratique :
Mémoire paginée :
./bandwidthTest --memory=pageable
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce RTX 3050
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PAGEABLE Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.8
Device to Host Bandwidth, 1 Device(s)
PAGEABLE Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.6
Device to Device Bandwidth, 1 Device(s)
PAGEABLE Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 196.6
Mémoire page-lock :
./bandwidthTest --memory=pinned
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce RTX 3050
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.7
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.8
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 201.5
Utiliser l'utilitaire bandwidthTest de CUDA Samples avec l'option --mode=shmoo pour obtenir les temps de transfert pour différentes tailles de données.
4.4.12. UVA (CUDA 4 and higher) - UMA (CUDA 6 and higher)
Unified Memory — Simplifies programming by enabling applications to access CPU and GPU memory without the need to manually copy data from one to the other, and makes it easier to add support for GPU acceleration in a wide range of programming languages.
Unified Memory creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The key is that the system automatically migrates data allocated in Unified Memory between host and device so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.
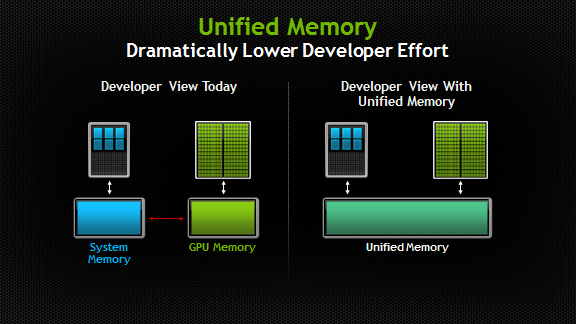
Voir le lien suivant pour plus d'informations : Unified Memory in CUDA 6
Devices of compute capability 2.x support a special addressing mode called Unified Virtual Addressing (UVA) on 64-bit Linux, Mac OS, and Windows XP and on Windows Vista/7 when using TCC driver mode. With UVA, the host memory and the device memories of all installed supported devices share a single virtual address space.
4.5. Atteindre le maximum de performances
4.5.1. résoudre le goulet d'étranglement des registres
On dispose de mécanismes de contrôle lors de la compilation :
- --maxrregcount <N> ou -maxrregcount=N permet de spécifier le nombre maximum de registres affectés à un thread
- --ptxas-options=-v donne des renseignements sur le nombre de registres utilisés et la mémoire constante
Exemple ptxas :
__global__ void sum1(float *a, float *b, float *c, int size) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < size) {
c[i] = a[i] + b[i];
}
}
L'étape de compilation indique l'utilisation de 4 registres et de la mémoire constante pour stocker des données comme les paramètres du kernel :
nvcc --compile --ptxas-options=-v -gencode arch=compute_20,code=sm_20 --optimize=2 ...
ptxas info : Compiling entry function '_Z4sum1PfS_S_i' for 'sm_20'
ptxas info : Function properties for _Z4sum1PfS_S_i
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 4 registers, 48 bytes cmem[0]
L'utilisation de cuobjdump -sass vector_sum_cuda.o, nous permet de voir le résultat de la compilation sour format PTX (Parallel Thread eXecution), on constate :
- l'utilisation de 4 registres R0 à R3
- l'utilisation de la mémoire constante pour stocker les paramètres de la fonction
- l'utilisation d'un prédicat P0 pour gérer la conditionnelle if
__global__ void kernel_sum(float *x, float *y, float *z, const float a, int size) {
int i = threadIdx.x ;
if (i < size) {
z[i] = a * x[i] + y[i]; // paralell part
}
}
code for sm_30
Function : _Z10kernel_sumPfS_S_fi
.headerflags @"EF_CUDA_SM30 EF_CUDA_PTX_SM(EF_CUDA_SM30)"
/* 0x2232c28002c28007 */
/*0008*/ MOV R1, c[0x0][0x44]; /* 0x2800400110005de4 */
/*0010*/ S2R R0, SR_TID.X; /* 0x2c00000084001c04 */
/*0018*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x15c], PT; /* 0x1b0e40057001dc23 */
/*0020*/ @P0 BRA.U 0x90; /* 0x40000001a00081e7 */
/*0028*/ @!P0 MOV32I R5, 0x4; /* 0x18000000100161e2 */
/*0030*/ @!P0 IMAD R6.CC, R0, R5, c[0x0][0x140]; /* 0x200b80050001a0a3 */
/*0038*/ @!P0 IMAD.HI.X R7, R0, R5, c[0x0][0x144]; /* 0x208a80051001e0e3 */
/* 0x228292c2027202c7 */
/*0048*/ @!P0 IMAD R8.CC, R0, R5, c[0x0][0x148]; /* 0x200b8005200220a3 */
/*0050*/ @!P0 IMAD.HI.X R9, R0, R5, c[0x0][0x14c]; /* 0x208a8005300260e3 */
/*0058*/ @!P0 LD.E R3, [R6]; /* 0x840000000060e085 */
/*0060*/ @!P0 LD.E R2, [R8]; /* 0x840000000080a085 */
/*0068*/ @!P0 IMAD R4.CC, R0, R5, c[0x0][0x150]; /* 0x200b8005400120a3 */
/*0070*/ @!P0 IMAD.HI.X R5, R0, R5, c[0x0][0x154]; /* 0x208a8005500160e3 */
/*0078*/ @!P0 FFMA R0, R3, c[0x0][0x158], R2; /* 0x3004400560302000 */
/* 0x200000000002e007 */
/*0088*/ @!P0 ST.E [R4], R0; /* 0x9400000000402085 */
/*0090*/ EXIT; /* 0x8000000000001de7 */
/*0098*/ BRA 0x98; /* 0x4003ffffe0001de7 */
/*00a0*/ NOP; /* 0x4000000000001de4 */
/*00a8*/ NOP; /* 0x4000000000001de4 */
/*00b0*/ NOP; /* 0x4000000000001de4 */
/*00b8*/ NOP; /* 0x4000000000001de4 */
code for sm_50
Function : _Z10kernel_sumPfS_S_fi
.headerflags @"EF_CUDA_SM50 EF_CUDA_PTX_SM(EF_CUDA_SM50)"
/* 0x003fb400e3a007e6 */
/*0008*/ MOV R1, c[0x0][0x20]; /* 0x4c98078000870001 */
/*0010*/ S2R R0, SR_TID.X; /* 0xf0c8000002170000 */
/*0018*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x15c], PT; /* 0x4b6d038005770007 */
/* 0x001f9040fe4007fd */
/*0028*/ @P0 EXIT; /* 0xe30000000000000f */
/*0030*/ SHL.W R3, R0.reuse, 0x2; /* 0x3848008000270003 */
/*0038*/ SHR R4, R0, 0x1e; /* 0x3829000001e70004 */
/* 0x001fc000fe4007ed */
/*0048*/ IADD R8.CC, R3, c[0x0][0x140]; /* 0x4c10800005070308 */
/*0050*/ IADD.X R9, R4, c[0x0][0x144]; /* 0x4c10080005170409 */
/*0058*/ IADD R10.CC, R3, c[0x0][0x148]; /* 0x4c1080000527030a */
/* 0x001ec400fc4007ed */
/*0068*/ LDG.E R2, [R8]; /* 0xeed4200000070802 */
/*0070*/ IADD.X R11, R4, c[0x0][0x14c]; /* 0x4c1008000537040b */
/*0078*/ LDG.E R0, [R10]; /* 0xeed4200000070a00 */
/* 0x041f8800fe2007ed */
/*0088*/ IADD R6.CC, R3, c[0x0][0x150]; /* 0x4c10800005470306 */
/*0090*/ IADD.X R7, R4, c[0x0][0x154]; /* 0x4c10080005570407 */
/*0098*/ FFMA R0, R2, c[0x0][0x158], R0; /* 0x4980000005670200 */
/* 0x001ffc00fc6000f1 */
/*00a8*/ STG.E [R6], R0; /* 0xeedc200000070600 */
/*00b0*/ DEPBAR {0}; /* 0xf0f0000000070001 */
/*00b8*/ EXIT; /* 0xe30000000007000f */
/* 0x001f8000fc0007ff */
/*00c8*/ BRA 0xc8; /* 0xe2400fffff87000f */
/*00d0*/ NOP; /* 0x50b0000000070f00 */
/*00d8*/ NOP; /* 0x50b0000000070f00 */
/* 0x001f8000fc0007e0 */
/*00e8*/ NOP; /* 0x50b0000000070f00 */
/*00f0*/ NOP; /* 0x50b0000000070f00 */
/*00f8*/ NOP; /* 0x50b0000000070f00 */
.......................................
4.5.2. utiliser l'occupancy calculator
Ce fichier Excel est disponible sous le répertoire C/tools du NVidia SDK.
Par exemple :
Comment atteindre l'Occupancy Maximale.
| Compute capability | 2.1 | 2.1 | 2.1 | 2.1 | 3.0 |
| Threads per block | 128 | 256 | 512 | 1024 | 1024 |
| registers per thread | 16 | 16 | 16 | 16 | 16 |
| active threads / SM | 1024 | 1536 | 1536 | 1024 | 2048 |
| Warps per SM | 32 | 48 | 48 | 32 | 64 |
| Threads blocks / SM | 8 | 6 | 3 | 1 | 2 |
| Occupancy | 67% | 100% | 100% | 67% | 100% |