Table des matières
- 1. Introduction et Historique
- 2. Programmer avec CUDA
- 3. Le Modèle Logique
- 4. Le Modèle Physique
- 5. Thrust & CUME
- Bibliographie et sitographie
1. Introduction et Historique
Note : ce cours représente une brève introduction à CUDA. On pourra lire les différents ouvrages traitant du sujet [1, 2, 3] pour se familiariser avec les fonctionnalités avancées de CUDA.
![]()
CUDA is a parallel computing platform and programming model invented by NVIDIA. It enables dramatic increases in computing performance by harnessing the power of the graphics processing unit (GPU). NVIDIA provides a complete toolkit for programming on the CUDA architecture, supporting standard computing languages such as C, C++ and Fortran (NVidia)
Ici le verbe harness peut être traduit par : en exploitant au mieux.
1.1. Programmation Multi-core et many-core
- multi-core = CPU ~ dizaines de coeurs
- many-core = GPU ~ centaines ou milliers de coeurs
1.1.1. L'ère du multi-core
Depuis l'invention du microprocesseur (CPU = Central Processing Unit) par Intel en 1971, les circuits intégrés ont connu de nombreuses améliorations qui ont concourru à l'augmentation de leurs performances :
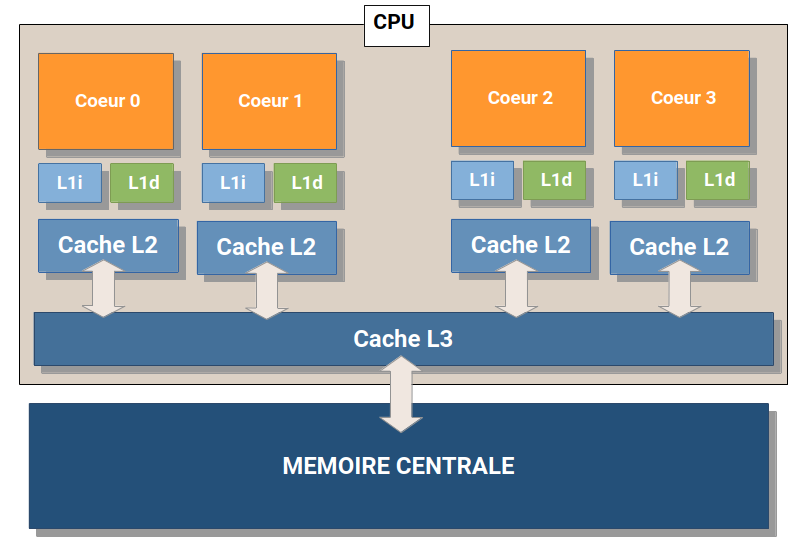
- augmentation de la fréquence
- niveaux et taille de cache (L1, L2, L3, L4=eDRAM)
- exécution super scalaire
- circuits dédiés : FPU, SSE, AVX
- multi-core : dual, tri, quad, hexa, octo, ...
Cependant, en terme de parallèlisme, même si on dispose de plusieurs coeurs, ceux-ci exécutent en général des programmes différents, on est dans un modèle MIMD (Multiple Instructions, Multiple Data). Seules les unités dédiées (SSE, AVX) permettent de faire du calcul parallèle, mais on parle ici de circuits vectoriels capables de traiter 4 réels simple précision dans le cas du SSE4.2.
L'utilisation de plusieurs coeurs de microprocesseurs, ou de plusieurs microprocesseurs pour la programmation en parallèle est qualifiée de programmation multi-core.
Exemple d'application maximum de parcimonie
1.1.2. L'ère du many-core
En parallèle des CPU, les GPU (Graphics Processing Unit) circuits initialement conçus pour l'affichage graphique (notamment la 2D et dans une plus large mesure la 3D), ont connu un essor fulgurant. La rivalité des constructeurs NVidia et ATI (racheté par AMD) a été bénéfique et elle a mené à l'évolution des GPU vers des circuits dédiés au calcul hautement parallèle. En fonction du GPU on est capable de traiter plusieurs centaines ou milliers de réels simple précision en parallèle.
Comparaison multi et many core
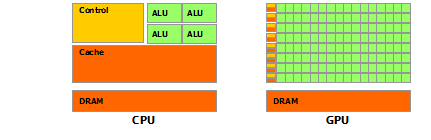
L'utilisation d'un GPU pour le calcul parallèle est qualifiée de programmation many-core et correspond à du SIMD (Single Instruction, Multiple Data) ou plutôt à ce que les constructeurs appellent du SIMT (Single Instruction, Multiple Thread).
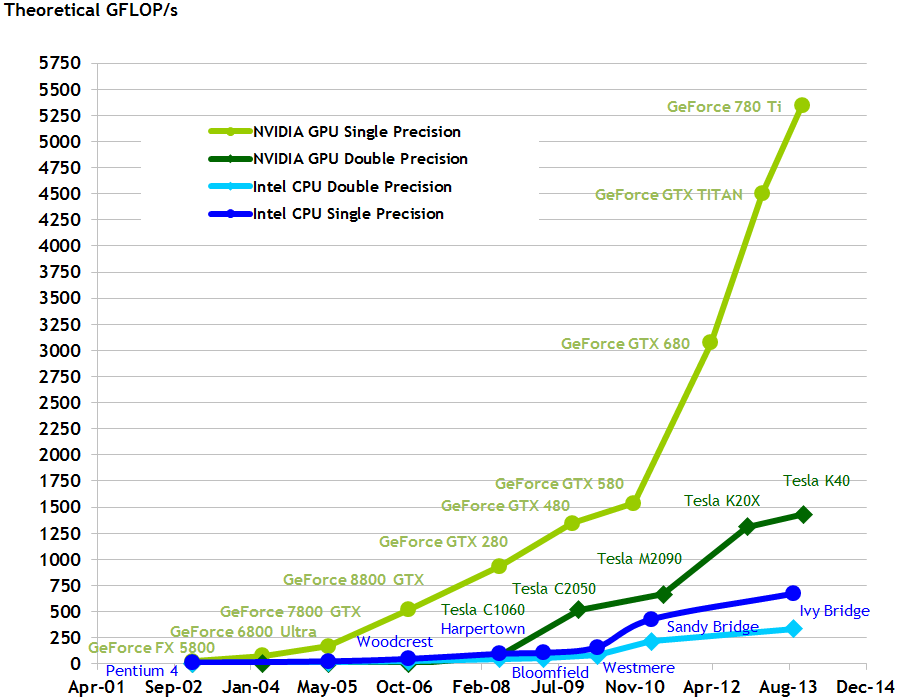
Notons qu'en 2009, la puissance de calcul d'un CPU était d'environ 100 GFlops alors que celle d'un GPU était 1 TFlops, soit 10 fois plus importante.
Les graphiques suivants peuvent être trouvés ici pour des versions plus récentes.
Evolution des performances en GFlops des CPU et GPU
(Source: Nvidia CUDA Programming Guide)
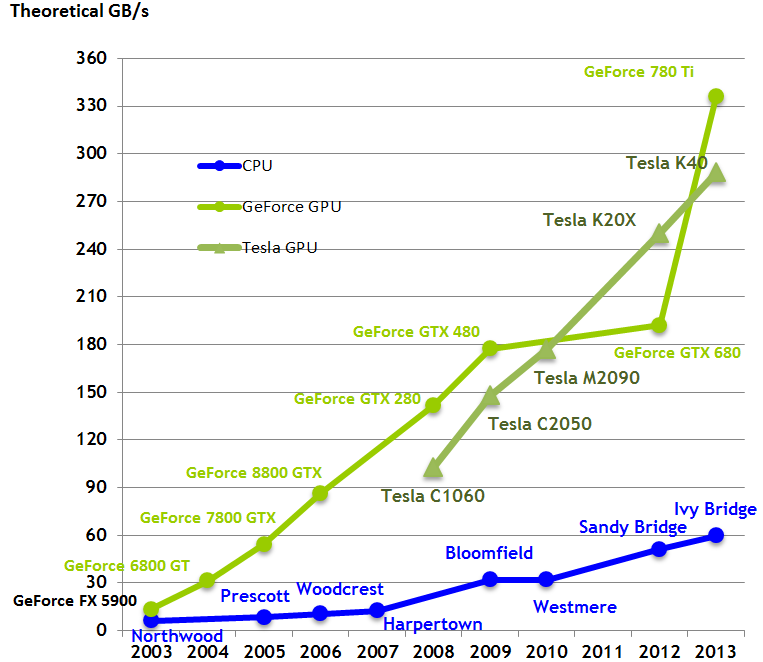
Evolution de la Bande passante mémoire en Go/s des CPU et GPU
(Source: Nvidia CUDA Programming Guide)
| CPU | GPU | |
| concepteur | Intel | NVIDIA |
| modèle | Core i7 920 | GTX 280 |
| date de lancement | Juin 2008 | Novembre 2008 |
| prix (dollars) | 260 | 260 |
| fréquence | 2.66 GHz | 1.3 GHz |
| cores | 4 | 240 |
| threads | 8 | 23040 |
| GFlops | 64 | 933 |
| BP mémoire Go/s | 31.8 | 141.7 |
| TDP | 130W | 236W |
| GFlops/W | 0.49 | 3.95 |
Dans le tableau comparatif précédent, si on désire obtenir la même puissance de calcul qu'une carte graphique grâce à un CPU, on devra utiliser $933 / 64 = 14.57$ soit environ 15 CPU, ce qui représente :
- un coût d'achat de $15 × 260 = 3900$ dollars ($× 15$)
- et une consommation électrique de $15 × 130 = 1950$ Watts ($× 8.26$)
1.2. Evolution des GPU pour le calcul parallèle
1.2.1. Aperçu
Les GPU ont évolué de manière drastique en passant des stations de travail très onéreuses des années 80 (\$50.000) à des périphériques PC abordables de l'ordre de \$200 à la fin des années 1990.
| début 1980 | fin 1990 | |
| pixels/s | 5 x 10^7 | 10^9 |
| vertex/s | 10^5 | 10^7 |
L'évolution des performances est due à deux facteurs:
- diminution de la finesse de gravure des circuits
- amélioration des algorithmes de traitement des données
Au final, on est passé en 30 ans d'un simple pipeline traitant des structures en fil de fer à une conception hautement parallèle composée de plusieurs pipelines capables de produire le rendu de scènes 3D.
On rappelle que le but d'une carte graphique est de produire une image (ensemble 2D de pixels avec couleurs) à partir d'une scène 3D ou les objets sont modélisés par des triangles (composés de 3 sommets) auxquels on applique des textures et des effets de lumière, ceci en fonction de l'angle de vue de l'utilisateur dans la scène et des sources de lumière.
1.2.2. Le pipeline configurable (jusque fin 1990)
Du début des années 1980 à la fin des années 1990, les GPU étaient conçus comme des pipelines dotés de fonctions graphiques dédiées configurables. Les données (vertex) en provenance du CPU sont traitées par le pipeline graphique.
- Réception : le GPU reçoit du CPU (host) les données à traiter
- Vertex Control : formate les données et les place dans le Vertex Cache
- VS/T&L (Vertex Shading, Transform and Lighting) : transforme les coordonnées des sommets et affecte des valeurs : couleur, texture, normale, tangente, couleur d'ombre mais pas appliquée directement à cette étape
- Triangle Setup : crée les équations qui permettent d'interpoler les couleurs des autres pixels
- Raster : détermine quels pixels sont contenus dans chaque triangle, on calcule par interpolation les couleurs, position des textures soumises à l'ombrage
- Shader : détermine la couleur finale de chaque pixel, il existe de ce point de vue plusieurs techniques qui permettent de rendre la scène plus ou moins réaliste
- ROP (Raster OPeration): finalise le calcule et gère la transparence, l'anti-aliasing, supprime les pixels non visibles
- FBI (Frame Buffer Interface) : gère les lectures / écritures avec le tampon d'affichage
1.2.3. Le pipeline programmable (à partir de 2001)
A partir de 2001, l'arrivée du GPU NVidia GeForce 3 représente l'ouverture aux programmeurs du pipeline graphique, notamment la partie VS/T&L. La tendance générale vers une unification des fonctionnalités des différentes étapes de traitement se poursuit également avec les différentes versions de DirectX (version 8 à 10).
Microsoft DirectX est une collection de bibliothèques destinées à la programmation d’applications multimédia, plus particulièrement de jeux ou de programmes faisant intervenir de la vidéo, sur les plates-formes Microsoft (Xbox, systèmes d’exploitation Windows).
(Wikipedia)
On passe alors d'un pipeline pré-programmé à un pipeline programmable dont la logique a été extraite en amont des traitements. On peut faire une analogie avec la construction automobile et les différents niveaux de finition. Plutôt que d'avoir autant de chaînes de productions que de finitions, on crée une seule chaîne. Un modèle de qualité supérieure engendrera plus d'étapes de traitements sur chaîne.
1.2.4. Le GPGPU
Avec l'évolution du matériel des GPU et l'ouverture progressive du pipeline de traitement, certains se sont aperçus qu'il était possible d'utiliser le GPU pour effectuer des calculs parallèles, ceci à partir de la version 9 de DirectX. Cependant, il s'agissait d'un véritable tour de force car l'API de DirectX 9 était encore nettement orientée traitements graphiques.
Le programmeur devait alors coder ses calculs sous forme de traitement de type pixel shader, les données en entrée étaient stockées dans des images de textures et les données en sorties devaient être transformées sous forme de pixels générés par l'opération raster. De nombreux autres problèmes devaient être réglés (cf. [1] page 31).
On qualifie cette première étape d'utilisation des fonctionnalités graphiques des GPU pour le calcul parallèle de GPGPU : General-Purpose computing on GPU, par opposition au GPU computing, où le GPU est dédié au calcul parallèle.
1.2.5. GPU computing
C'est à partir du développement de l'architecture Tesla (2007) que NVidia a réalisé l'utilité de pouvoir modéliser et utiliser le GPU comme un CPU. Attention : ne pas confondre l'architecture Tesla et les cartes Tesla du même constructeur, voir ci-après dans ce chapitre.
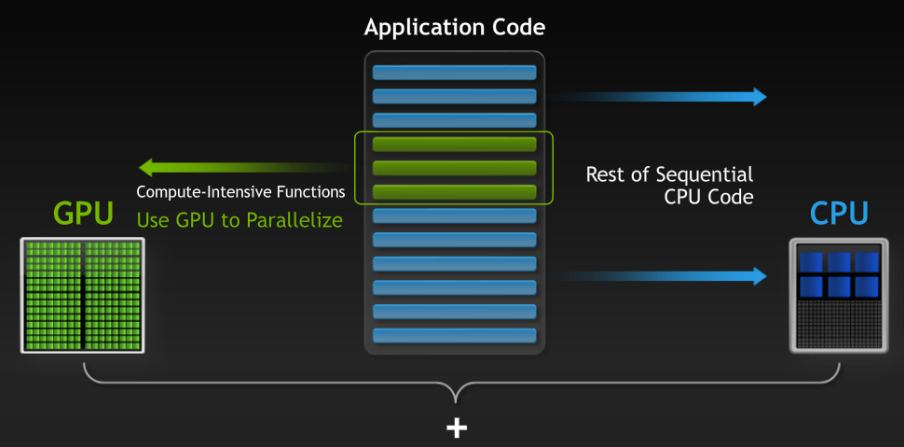
Le code écrit en CUDA peut être infime mais apporter un gain de performance impressionnant
| CPU | Puissance de crête GFlops |
TDP |
| Intel Pentium 4 - 2.8 Ghz - 1 coeur - x86 | 2.7 | 70 W |
| Intel Centrino Duo - 1.66 Ghz - 2 coeurs - x86 | 3.1 | 30 W |
| Intel Xeon 5410 - 2.33 Ghz - 4 coeurs - x64 | 9,5 | 100 W |
| Intel Core I7 980x - 3.33 Ghz - 6 coeurs - x64 | 20 | 130 W |
| AMD Athlon 64 x2 - 3 Ghz - 2 cœurs - x64 | 5,9 | 65 W |
| AMD Phenom II x6 - 3.0 Ghz - 6 cœurs - x64 | 17,8 | 100 W |
| Intel Core i9-13900HX - 5.4 / 3.9 Ghz - 8+16 cœurs - x64 | 845 | 157 W |
| Intel Core Ultra 7 265T - 5.3 / 4.6 Ghz - 8+12 coeurs - x64 | 1940 | 112 W |
| Intel Core Ultra 9 285HX - 5.5 / 4.6 Ghz - 8+16 coeurs - x64 | 1989 | 160 W |
| GPU | Puissance de crête GFlops |
TDP |
| NVidia 9800 GT - 112 cœurs - 600 Mhz | 370 | 230 W |
| NVidia GT240 - 96 coeurs - 550 Mhz | 260 | 180 W |
| NVidia GTX 285 - 240 cœurs - 648 Mhz | 700 | 370 W |
| NVidia GTX 480 - 480 cœurs - 700 Mhz | 1350 | 410 W |
| ATI HD 3870 - 320 cœurs - 775 Mhz | 490 | 240 W |
| ATI HD 4890 - 800 cœurs - 850 Mhz | 1360 | 290 W |
| ATI HD 5970 - 3200 cœurs - 725 Mhz | 4640 | 430 W |
| NVidia GeForce RTX 5090 - 21760 cores - 2017 Mhz | 104800 | 575 W |
| NVidia H200 SXM - 16896 cores - 1500 Mhz | 66910 | 700 W |
| NVidia RTX Pro 6000 - 24064 cores - 1590 Mhz | 126000 | 600 W |
- 2024 : NVidia H200 SXM 141 Go : FP32 66.91 TFLOPS, FP64 33.45 TFLOPS
- 2025 : NVidia GeForce RTX 5090 32 Go : FP32 104.8 TFLOPS, FP64 1.637 TFLOPS
- 2025 : NVIDIA RTX PRO 6000 Blackwell 96 Go : FP32 126.0 TFLOPS, FP64 1.968 TFLOPS
Dans les tableaux précédents, si on désire, en 2025, obtenir la même puissance de calcul qu'une carte graphique RTX Pro 6000 grâce à un CPU du type Core Ultra 9 285HX, on devra utiliser $126000 / 1989 = 63,34$ soit environ 64 CPU, ce qui représente :
- un coût d'achat de $64 × 600 = 38400$ dollars ($× 3,2$), le coût de la carte graphique étant d'environ 12000 €
- et une consommation électrique de $64 × 160 = 10240$ Watts ($× 17,06$), la puissance de la carte graphique étant de 600 W
1.2.6. GPU Computing et High Performance Computing (HPC)
Le calcul haute performance a pour objectif d'atteindre les plus hautes performances possibles en terme de calcul avec des technologies de pointe. Les machines qui résultent de la conception basée sur ce principe sont qualifiées de superordinateurs ou supercalculateurs (super computers). L'activité scientifique chargée de concevoir et programmer ces superordinateurs est appelée Calcul Haute Performance ou HPC en anglais pour High Performance Computing.
Les organismes de recherche civils et militaires comptent parmi les utilisateurs de superordinateurs qui sont destinés aux principaux domaines suivants :
- calcul des prévisions météorologiques, étude du climat,
- bioinformatique, modélisation moléculaire (calcul des structures 3D des protéines, ...),
- simulations physiques (simulations aérodynamiques, résistance des matériaux, simulation d’explosion d’arme nucléaire, étude de la fusion nucléaire),
- cryptanalyse
- LLM (Large Language Models)
La puissance des supercalculateurs est exprimée en FLOPS (FLoating point Operations Per Second) car la plupart des applications susnommées utilisent les nombres rééls pour représenter des coordonnées dans l'espace, des distances, des forces, des énergies, ... On utilise le test LINPACK (Résolution de systèmes d'équations linéaires) pour évaluer la puissance des supercalculateurs.
1.2.6.a quelques exemples
Rappelons que l'ASCI Red (1996--2006) d'Intel fut le premier à atteindre en 1997 la puissance d'1 PFlops en utilisant près de 9300 Intel Pentium Pro 200 Mhz.
Le Tianhe-1 (Voie Lactée) est un supercalculateur du National Supercomputing Center, à Tianjin en Chine. En octobre 2010, une version améliorée de la machine (Tianhe-1A) est devenue le supercalculateur le plus rapide au monde : Processeurs Intel Xeon (14366) + GPU NVIDIA Tesla M2050 (7166).
Avec le Tianhe-2 la chine ambitionne de passer le cap des 100 PFlops d'ici à trois ans, puis d'accélérer encore pour dépasser le seuil hautement symbolique de l'exaflops (1 EFlops = 1 000 PFlops = $10^{18}$ calculs en virgule flottante à la seconde) d'ici 2018. (source Tomshardware.com).
Octobre 2012, Le Titan (Oak Ridge National Laboratory, USA, Tennessee) : On passe donc à 18 688 cartes Telsa K20 (a priori), soit 28 704 768 unités de calcul sur le GPU, et 18 688 Opteron 6274, des modèles « Bulldozer » dotés de 16 cores (plus exactement 8 cores et 16 modules), soit 299 008 threads. Il est doté de 710 To de mémoire et sa consommation devrait être de 9 mégawatts environ, soit à peine plus que l'itération précédente du supercalculateur — c'est une simple mise à jour — pour une puissance théorique multipliée par 10 environ.
La machine offre une puissance théorique qui dépassera 20 pétaflops et environ 90 % de la puissance de calcul vient des cartes Tesla (source Tomshardware.com, voir également l'article d'Anandtech)
Tesla dévoile le nouveau superordinateur Dojo
1.2.6.b liens
Le site top500.org recense les superordinateurs les plus puissants. En Juin 2015, le superordinateur le plus puissant est le Tianhe-2 avec une puissance de 33,86 petaflop/s pour LINPACK.
Le site green500.org recensait, quant à lui, les superordinateurs consommant le moins d'énergie. Il a été intégré au site top500.org.
De plus en plus de superordinateurs utilisent de GPU compatibles CUDA en raison d'une consommation énergétique beaucoup plus faible, pour un coût de revient plus faible et une puissance de calcul supérieure à celle des CPU.
En Mai 2005, le superordinateur le plus puissant est El Capitan du Lawrence Livermore National Laboratory (LLNL) en Californie avec une puissance de 1,7 Exa Flops, composé de 11,039,616 coeurs formés par des processeurs AMD EPYC 24C et AMD Instinct MI300A (APU).
1.3. La gamme de produits NVidia
On distingue 4 types de produits pour des usages différents compatibles CUDA :
- GeForce : cartes graphiques pour usage général : jeux, infographie, calcul parallèle
- Quadro : cartes graphiques dédiées aux professionnels : création de contenu digital, CAO, DAO
- Tesla : cartes graphiques dédiées uniquement au calcul parallèle
- Tegra : liée aux systèmes mobiles (téléphones, tablettes)
1.3.1. Les GeForce
A partir de la série GeForce 400 qui correspond à la 11ème génération de GPU GeForce, les chipsets sont identifiés par la lettre qui correspond à l'architecture suivi d'un numéro à 3 chiffres :
- GeForce 300 Series (Tesla) GT215, GT216, GT218, GT200
- GeForce 400 Series (Fermi, Tesla) GT216, GT218, GF100, GF104, GF106, GF108, GF114
- GeForce 500 Series (Fermi) GF106, GF108, GF110, GF114, GF116, GF119
- GeForce 600 Series (Fermi, Kepler) GF108, GF116, GF119, GK104, GK106, GK107, GK208
- GeForce 700 Series (Fermi, Kepler, Maxwell) GF117, GF119, GK104, GK106, GK107, GK110, GK208, GM107
- GeForce 900 Series (Maxwell) : GM10x, GM20x
- GeForce 1000 Series (Pascal)
Le problème est que pour une architecture donnée (ex. Fermi) il existe plusieurs sous-architectures (GF100, GF104, ...).
| Année | Architecture | Famille (Nom de code) | Faits marquants / innovations |
|---|---|---|---|
| 2006 | Tesla | G80 | Première architecture unifiée CUDA (Tesla C870) |
| 2008 | GT200 | GT200 | Amélioration de la puissance brute, toujours dans la gamme Tesla |
| 2010 | Fermi | GF100 | Double précision améliorée, ECC, lancement de CUDA 3.0 |
| 2012 | Kepler | GK104, GK110 | Meilleure efficacité énergétique, Dynamic Parallelism |
| 2014 | Maxwell | GM204, GM206 | Meilleure performance/Watt, compression de textures |
| 2016 | Pascal | GP100, GP104 | Utilisation de HBM2, NVLink, Tensor Cores expérimentaux |
| 2017 | Volta | GV100 | Premiers vrais Tensor Cores, conçu pour l’IA et le calcul scientifique |
| 2018 | Turing | TU102, TU104 | Cœurs RT pour ray tracing, Tensor Cores pour DLSS |
| 2020 | Ampere | GA100, GA102 | 2e génération Tensor & RT Cores, boost majeur IA/Jeu |
| 2022 | Hopper | H100 | Spécifique au calcul IA (data center), 4e génération Tensor Cores |
| 2022 | Ada Lovelace | AD102, AD104 | GPU grand public (RTX 40xx), meilleure efficacité IA et ray tracing |
| 2024 | Blackwell | B100, B200 | Nouvelle génération IA pour data centers (successeur de Hopper) |
PCI Express
Les GeForce sont généralement connectées au travers du bus PCI Express 1.0 à 5.0..
| Caractéristiques | PCI Express 1.0 | PCI Express 2.0 | PCI Express 3.0 | PCI Express 4.0 | PCI Express 5.0 |
| bande passante (GT/s) | 2.5 | 5 | 8 | 16 | 32 |
| débit par ligne (Mo/s) | 250 | 500 | 984.6 | 1969.2 | 3938 |
| débit pour 16 lignes (Go/s) | 4 | 8 | 15.754 | 31.508 | 63.02 |
- PCIe 1.0 et 2.0 utilisent un codage 8b/10b, introduisant une surcharge de 20%
- à partir de PCIe 3.0, un codage plus efficace 128b/130b est utilisé, réduisant la surcharge à environ 1,5%
Le PCIe est un bus full-duplex, permettant des transferts simultanés en lecture et en écriture. La bande passante totale est donc le double de celle indiquée par direction.
Par exemple pour le PCI Express 3.0, les données sont encodées sur 128 bits + 2 bits pour le contrôle, (alors que dans les versions précédentes on utilisait un encodage 8/10 bits). On parle d'encodage 128b/130b. Dans ce cas on perd 1.54% ( $(130-128)/130×100 = 1.538 ≈ 1.54$ ).
La bande passante est donc de $8000/8×(100-1.54)/100 = 984.60$ Mo/s
Connexion de plusieurs cartes graphiques
Sur certaines cartes mères, par exemple celles basées sur le chipset Z87 (Haswell) ou Z77 (Ivy Bridge), on dispose de plusieurs modes :
- 1 x 16 : 1 seule carte
- 2 x 8 : 2 cartes
- 1 x 8 + 2 x 4 : 3 cartes
Avec une seule carte on utilise 16 lignes PCI Express, mais avec 2 cartes on utilise 8 lignes par carte.
Autre exemple avec la carte MSI 287M-G43, on dispose de :
- 2x PCIe x16 slots
- PCI_E1 supports PCIe 3.0
- PCI_E4 supports PCIe 2.0
- Support x16, x4/x4 modes
- 2x PCIe 2.0 x1 slots
Il faut connecter la carte la plus puissante sur le port PCI Express 3.0
1.3.2. Tesla de NVidia
Pour le Calcul Haute Performance NVidia propose sa gamme de produits Tesla qui possède des avantages par rapport aux cartes graphiques dédiées aux jeux. Voilà ce que nous dit NVidia :
- Performances remarquables de virgule flottante en double précision
- Double précision plus élevée qu’avec les produits grand public : 2910 GFlops en DP pour Tesla K80, par comparaison une GTX Titan (mars 2015) autorise 192 GFlops en DP
- Communications PCIe plus rapides
- Le seul produit NVIDIA avec deux moteurs DMA pour des communications PCIe bidirectionnelles
- Performances plus élevées avec les applications techniques aux gros volumes de données
- Mémoire embarquée plus importante (3 Go et 6 Go, 12 Go pour K80)
- Communications plus rapides avec le bus InfiniBand compatible avec NVIDIA GPUDirect
- Patch spécial pour Linux, pilote InfiniBand et pilote CUDA
Voici quelques extraits d'un article de The Platform.net :
While the CUDA programming environment for GPU offload was invented in 2006 for the GeForce 8800 graphics cards, the concept of a separate Tesla GPU coprocessor aimed at supercomputing clusters did not happen until two years later with the launch of the Tesla C870 and D870 devices, which offered single precision floating point processing.
... the Tesla line is now at an annual revenue run rate of several hundred million dollars and grew at around 50 percent in the last fiscal year for Nvidia (2015), driven by strong adoption by both HPC and hyperscale organizations. ... New at the GTC 2015 event this week was Huang divulging that Nvidia has shipped a cumulative 450,000 Tesla coprocessors, an increase of 7.5 percent from 2008. (Cumulative CUDA downloads have increased by a factor of 20X, and that is because CUDA works on all Nvidia GPUs, not just Tesla coprocessors.)
Exemple
- Tesla C2075 : 448 cores, 6 Go GDDR5, BP 144 Go/s, 515 GFlops en double précision, 1,03 TFlops en simple précision
- Tesla K40 : 1 Kepler GK110, 2880 cores, 12 Go GDDR5, BP 288 Go/s : 1,66 TFlops double précision (boost), 5 TFlops simple précision (boost), 4.29 TFlops en simple précision
- Tesla K80 : 2 Kepler GK210, 4992 cores, 24 Go GDDR5, BP 480 Go/s (2 x 240) : 2.91 double précision (boost), 8,74 TFlops simple précision (boost), 5.6 TFlops en simple précision
- Tesla V100 (Volta), 16 Go HBM2, 900 Go/s, 7.5 TFlops en double précision, 15 TFlops en simple précision, 120 TFlops (deep learning)
NVidia propose également des stations de calcul haute performance :
| Composant | Caractérisique |
| Carte mère | Dual socket LGA 1366, chipset Intel 5520/ICH10R |
| Processeurs | 2 x Intel Xeon 6 Core X5670 (2.93Ghz, 12Mo de cache, 1333MHz, 95W) |
| Mémoire | 24Go DDR3 1333Mhz ECC REG - Extensible à 64Go |
| Disques durs | 2 x 1To SATA II - 64Mo |
| GPU | 4 x NVIDIA Tesla C2075, 6Go de mémoire DDR5, 1 x interface PCIe x16 2.0 |
| Système d'exploitation | Linux Fedora |
Exemple chez Transtec d'un noeud CUDA 3230 Compute Node Système Rack 1U :
| Composant | Caractérisique |
| Processeur | 1 x Intel Xeon 6 Core E5-2603v3 (1.6 Ghz, 15 Mo de cache L3, 1333MHz, 85W) |
| Mémoire | 8 GB DDR4 DIMM, 2133 MHz, registered, ECC |
| Disques durs | 1 x 500 Go SATA, 7200 tr/min |
| GPU | 1 Tesla K80 24 Go |
| Total | 15997 € |
NVIDIA a vendu son premier DGX-1V : 960 TFLOPS pour 149 000 dollars - Septembre 2017
Évolution du DGX-1 doté de puces à architecture Pascal, le DGX-1V embarque 8 cartes Tesla V100 basées sur l'architecture Volta. Les caractéristiques sont les suivantes :
- CUDA Core : 5120 x 8 = 40960, Tensor Cores : 5120
- FP 16 : 960 TFlops (with Tensor cores)
- FP 32 : 14 TFlops x 8 = 112 TFlops
- FP 64 : 7 TFlops x 8 = 56 TFlops
- 3200 W, soit 112000/3200 = 35 GFlops/W
1.3.3. Quelques prix des produits NVidia
| Carte graphique | Prix € | SP GFlops | DP Glops |
| PNY Tesla M60 16 Go | 7122 | 9650 | 300 |
| PNY Quadro M6000 12 Go | 5633 | 6070 | 190 |
| MSI GTX 1080 Ti 11 Go | 769 | 16609 | 332 |
| MSI GTX 1080 Gaming 8 Go | 579 | 8228 | 257 |
| Asus GTX 1070 STRIX 8 Go | 485 | 5783 | 181 |
| Carte graphique | Prix € | SP GFlops | DP Glops |
| PNY GeForce GTX 970 4 Go GDDR5 | 309 | 3494 | 109 |
| Gigabyte GeForce GTX 980 4 Go GDDR5 | 559 | 4612 | 144 |
| PNY Tesla K20 5 Go | 4709 | 4100 | 1173 |
| PNY Tesla K40 12 Go | 3507 | 5364 | 1430 |
| PNY Quadro K4000 3 Go | 5610 | 1626 | - |
| NVidia Quadro K6000 12 Go | 5463 | 5196 | 1732 |
Exercice: comparer le rapport performance / prix entre GTX 970 et Tesla K40.
| Carte graphique | Prix € |
| PNY GeForce GTX 580 1536Mo GDDR5 | 417 |
| PNY GeForce GTX 680 2Go GDDR5 | 499 |
| PNY Tesla C2050 | 1874 |
| PNY Quadro 5000 2.5 Go | 4969 |
1.4. Evolution de CUDA en quelques chiffres
| Année | 2008 | 2015 | Gain |
| GPUs vendus | 100 millions | 600 millions | x 6 |
| Superordinateurs | 1 | 75 | x 75 |
| Cours universitaires | 60 | 840 | x 14 |
| papiers académiques | 4.000 | 50.000 | x 12.5 |
1.5. Informations liées à CUDA sur le net
NVidia diffuse une newsletter relative à CUDA : CUDA Week in Review. Les sujets abordés sont les suivants :
- informations généralistes
- epmlois
- recherche, thèse
- séminaires, conférences, cours
On trouvera également la liste des GPUs compatibles CUDA ainsi que la NVidia Developer Zone.
1.6. Librairies accélérées par CUDA
- Thrust : STL C++
- cuBLAS : Basic Linear Algebra
- cuSPARSE : calculs avec matrices creuses
- NPP (NVidia Performance Primitives) et cuFFT : traitement de l'image et du signal
1.7. CUDA pour quels domaines ?
Etudes de cas de NVidia
- Life Sciences : TeraChem 650x
- Life Sciences : Accelerator-Oriented Algorithm Transformation for Temporal Data Mining 431x
- Graphics : Fast image blurring 300x
- Graphic processors to speed-up simulations for the design of high performance solar receptors 420x
- Implementation of a Lattice-Boltzmann method for numerical fluid mechanics 1840x
1.8. Ressources
- le site de NVidia
- le SDK : ~/NVIDIA_GPU_Computing_SDK, notamment le sous-répertoire CUDALibraries/doc
1.9. Performances en GFlops des CPU
Il existe un utilitaire linpack lié à la MKL (Math Kernel Library) d'Intel qui permet de connaître la puissance en GFlops de votre processeur Intel (Linux, Windows, MacOS) : Intel MKL Linpack
Intel® Optimized LINPACK Benchmark is a generalization of the LINPACK 1000 benchmark. It solves a dense (real*8) system of linear equations (Ax=b), measures the amount of time it takes to factor and solve the system, converts that time into a performance rate, and tests the results for accuracy. The generalization is in the number of equations (N) it can solve, which is not limited to 1000. It uses partial pivoting to assure the accuracy of the results. source: Intel
./linpack_11.0.0/benchmarks/linpack/runme_xeon32
Intel(R) Optimized LINPACK Benchmark data
Current date/time: Tue Oct 16 14:35:06 2012
CPU frequency: 3.390 GHz
Number of CPUs: 1
Number of cores: 4
Number of threads: 4
Performance Summary (GFlops)
Size LDA Align. Average Maximal
15000 15000 4 75.3443 75.3443
14000 14008 4 77.2016 77.2368
13000 13000 4 75.2261 76.5220
12000 12008 4 72.3286 76.1669
11000 11000 4 71.7737 74.3548
10000 10008 4 75.4813 75.7207
8000 8008 4 67.0813 67.9952
6000 6008 4 71.4119 71.5401
1000 1000 4 49.5919 53.2004
Autres résultats :
| CPU | Freq. (Ghz) | Cores | Threads | MaxPeak (GFlops) |
| Core i5-4570 | 3.20 | 4 | 4 | 71.43 |
| Core i7-2600 | 3.40 | 4 | 8 | 81.15 |
| Core i5 3570k | 3.40 | 4 | 4 | 77.20 |
| Core i7 860 | 2.80 | 4 | 8 | 38.70 |
| Core2 Quad Q9300 | 2.50 | 4 | 8 | 34.27 |
| Core 2 Duo E8400 | 3.00 | 2 | 2 | 20.33 |
| Core i7-2760QM | 2.40 | 4 | 8 | 59.28 |
| CPU | Freq. (Ghz) | Cores | Threads | MaxPeak (GFlops) |
| Core i5-4570 | 3.20 | 4 | 4 | 118.06 |
| Core i7-2760QM | 2.40 | 4 | 8 | 66.66 |
On note que pour le Core i5-4570, le fait d'être en 64 bits augmente les performances.
1.10. Exemples
1.10.1. Fibonacci - entiers
Calcul récursif Fibonacci : soit une matrice d'entiers de dimension $N$ calculer $m[i,j] = fib(m[i,j])$, telle que fib est une fonction récursive.
| N | CPU | CPU (4 coeurs) | GPU | Accélération |
| 1024 | 0.178 | 0.071 | 0.016 | x4.43 |
| 2048 | 0.692 | 0.252 | 0.065 | x3.87 |
| 4096 | 2.720 | 0.806 | 0.249 | x3.23 |
| 8192 | 10.945 | 3.375 | 0.945 | x3.57 |
- CPU : Core i5-4570 à 3.20 Ghz, 4 coeurs (4 threads)
- GPU : GTX 660 (960 CUDA Cores à 980 Mhz)
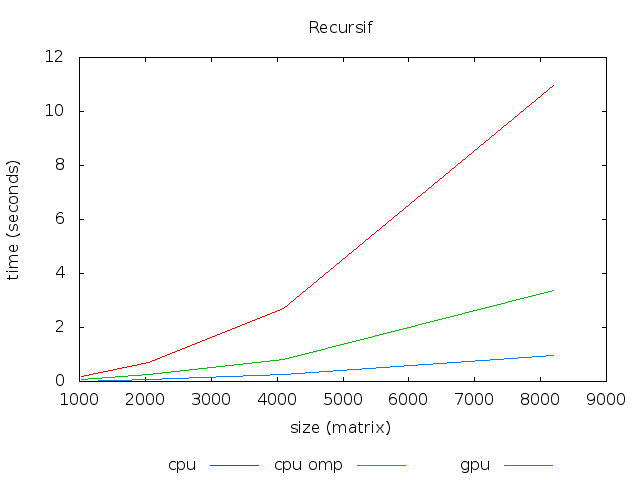
Note: OpenMP ou OMP (Open Multi-Processing) est une interface de programmation pour le calcul parallèle sur architecture à mémoire partagée.
1.10.2. Nombres premiers
soit une matrice d'entiers de dimension $N$, déterminer si $m[i,j]$ est un nombre premier.
| CPU/GPU | N | tCPU | tCPU (4 coeurs) | tGPU | Accélération |
| i5-4570 / GTX 770 | 1024 | 0.261 | 0.092 | 0.012 | x7.66 |
| i5-4570 / GTX 770 | 2048 | 1.892 | 0.653 | 0.091 | x7.17 |
| i5-4570 / GTX 770 | 4096 | 13.785 | 4.787 | 0.713 | x6.71 |
| i5-3570K / GTX 560 Ti | 1024 | 0.284 | 0.092 | 0.030 | x3.06 |
| i5-3570K / GTX 560 Ti | 2048 | 2.002 | 0.666 | 0.238 | x2.79 |
| i5-3570K / GTX 560 Ti | 4096 | 14.661 | 4.860 | 1.862 | x2.61 |
| i7-4790 / GTX 970 | 1024 | 0.241 | 0.080 | 0.012 | x6.66 |
| i7-4790 / GTX 970 | 2048 | 1.699 | 0.584 | 0.078 | x7.48 |
| i7-4790 / GTX 970 | 4096 | 12.401 | 4.247 | 0.610 | x6.96 |
1.10.3. Julia - réels
Calcul d'image pour courbe de Julia (cf TD)
| Methode | Temp (s)s | Accélération |
| CPU (1 coeur) | 30.535 | - |
| CPU (4 coeurs, OpenMP) | 8.355 | x3.65 |
| GPU (G=512x512, B=16x16) | 0.736 | x41.48 |
- CPU : Core i5-4570 à 3.20 Ghz, 4 coeurs (4 threads)
- GPU : GTX 660 (960 CUDA Cores à 980 Mhz)
1.10.4. Mandelbrot - réels
Cf cours INRA interopérabilité avec Python.
1.11. Découverte du matériel et SDK
SDK et informations sur les cartes graphiques
Le SDK (Standard Development Kit) CUDA est généralement installé dans le répertoire /usr/local/cuda. Ce répertoire contient notamment les sous répertoires :
- bin : nvcc, nvprof, nvvp, nsight
- doc : la documentation, notamment le répertoire pdf
- include avec cuda.h et le sous-répertoire thrust
- lib ou lib64 : librairies notamment libcudart
- samples : utilitaires et exemples de démonstration
Se placer dans le répertoire /usr/local/cuda/samples et taper make pour générer les exécutables des exemples.
Une fois compilés, lancer :
cd /usr/local/cuda/samples
1_Utilities/deviceQuery/deviceQuery
1_Utilities/bandwidthTest/bandwidthTest
nvidia-smi
- GTX 1070 :
- device query pour GTX 1070 : CC 6.1, 8 Go, 1920 (=15x128) coeurs, GK104, PCI 3.0 x16, 5783 Gflops
- bandwidth pour GTX 1070 : (H2D, D2H, H2H) 11, 12, 183 Go/s
- GTX 970 :
- device query pour GTX 970 : CC 5.2, 4 Go, 1664 (=13x128) coeurs, GM204, PCI 3.0 x16, 3494 Gflops
- bandwidth pour GTX 970 : (H2D, D2H, H2H) ?, 12, 142 Go/s
- PCI Express 3.0 : HtoD 12,5 Go/s, DtoD 142 Go/s
- PCI Express 2.0 : HtoD 6.5 Go/s, DtoD 142 Go/s
- nvidia-smi pour GTX 970: Driver Version: 346.46
- GTX 770 :
- device query pour GTX 770 : CC 3.0, 2 Go, 1536 (=8x192) coeurs, GK104, PCI 3.0 x16, 3213 Gflops
- bandwidth pour GTX 770 : (H2D, D2H, H2H) 3.2, 3.2 175 Go/s
- nvidia-smi pour GTX 770: Driver Version: 340.29
- GTX 660 :
- device query pour GTX 660 : CC 3.0, 2 Go, 960 coeurs, GK106, PCI 3.0 x16, 1881 Gflops
- bandwidth pour GTX 660 : (H2D, D2H, H2H) 1.4, 1.6, 115 Go/s
- nvidia-smi pour GTX 660: Driver Version: 346.46
- GTX 560 Ti :
- device query pour GTX 560 Ti : CC 2.1, 1 Go, 384 (=8x48) coeurs, GF114, PCI 2.0 x16, 1263 Gflops
- bandwidth pour GTX 560 Ti : (H2D, D2H, H2H) 5.9, 4.7, 99 Go/s
- nvidia-smi pour GTX 560 Ti: Driver Version: 295.41
- Quadro K610m (portables étudiants) :
- device query pour Quadro K610m : CC 3.5, 1 Go, 192 (=1x192) coeurs, GK208, PCI 3.0 x16, 376 Gflops
- bandwidth pour Quadro K610m : (H2D, D2H, H2H) 6.3, 6.4, 14 Go/s
- nvidia-smi pour Quadro K610m: Driver Version: 352.39
- GT 650M (portable) :
- device query pour GT 650m : CC 3.0, 1 Go, 384 (=2x192) coeurs, GK 107, PCI 3.0, 641 Gflops
- bandwidth pour GT 650m : (H2D, D2H, H2H) 10.7, 11.5, 20.7 Go/s
- Tesla K20m (cluster taurus2) :
- device query pour Tesla K20m : CC 3.5, 4 Go, 2496 (=13x192) coeurs, GK110, PCIe 2.0 or 3.0 x16 ?, 3524 Gflops
- bandwidth pour Tesla K20m : (H2D, D2H, H2H) 5.8, 6.5, 91 Go/s
- nvidia-smi pour Tesla K20m: Driver Version: 340.29
Nvidia-smi et nvidia-settings
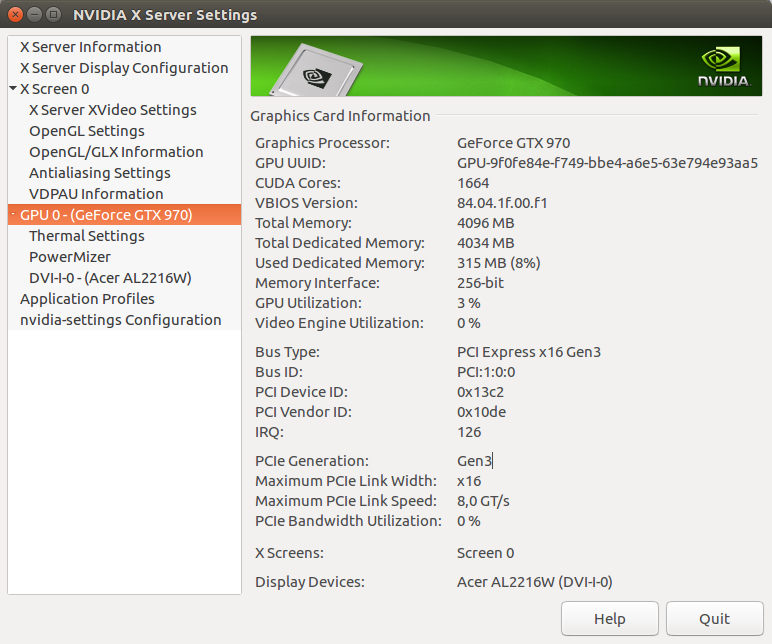
L'utilitaire en ligne de commande nvidia-smi donne des informations sur les cartes présentes :
\$ nvidia-smi
Wed Sep 27 08:58:29 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 378.13 Driver Version: 378.13 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 970 Off | 0000:01:00.0 On | N/A |
| 1% 53C P0 46W / 200W | 246MiB / 4034MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1345 G /usr/lib/xorg/Xorg 166MiB |
| 0 2586 G compiz 34MiB |
| 0 3417 G ...s-passed-by-fd --v8-snapshot-passed-by-fd 42MiB |
+-----------------------------------------------------------------------------+
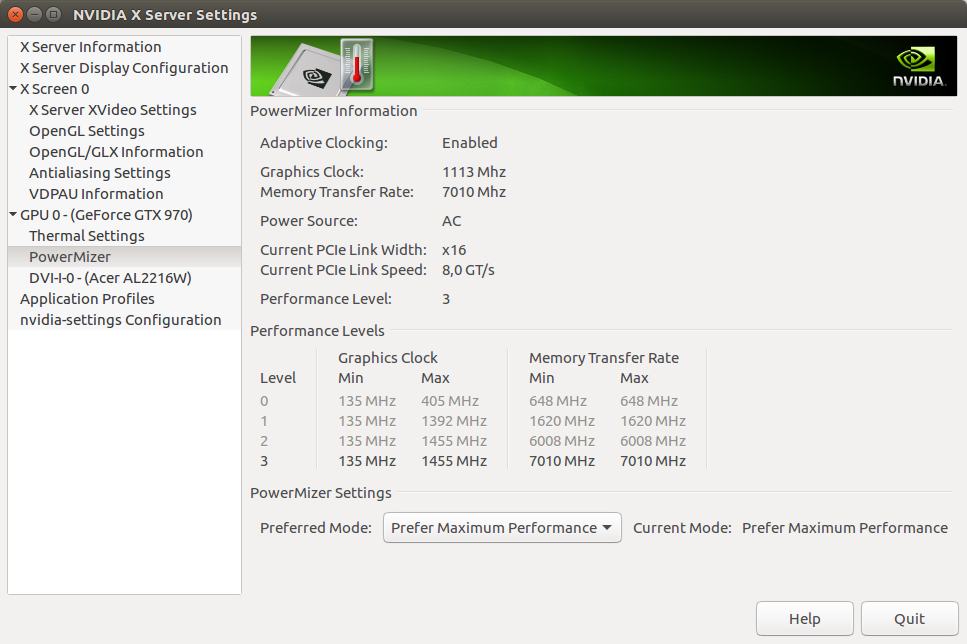
L'utilitaire graphique nvidia-settings est généralement plus intéressant et permet de régler la puissance du GPU: