Table des matières
- 1. Introduction et Historique
- 2. Programmer avec CUDA
- 3. Le Modèle Logique
- 4. Le Modèle Physique
- 5. Thrust & CUME
- Bibliographie et sitographie
3. Le Modèle Logique
3.1. Grille et bloc
L'essentiel des performances et de l'évolutivité de CUDA réside dans le modèle logique d'exécution qui partitionne les calculs en blocs de threads et les répartit sur l'architecture hautement parallèle du GPU.
La configuration matérielle CUDA joue un rôle important sur les performances d'exécution des kernels comme nous le verrons dans le chapitre suivant.
L'écriture de fonctions parallélisables ne revêt pas de caractère complexe, par contre la répartition des threads qui exécutent les kernels en parallèle pose quelques difficultés lorsque l'on commence à apprendre CUDA.
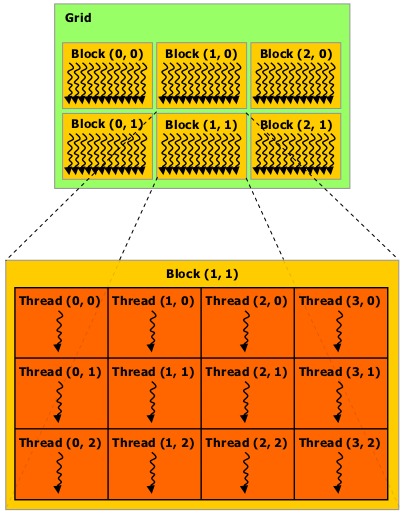
Lorsqu'un kernel est invoqué, il s'exécute sous forme d'une grille (grid) de blocs de threads parallèles. Dans le cas de l'exemple du chapitre 2, Chaque thread exécutera la partie de code z[i] = x[i] + y[i].
- une grille (grid) est un tableau à 1, 2 ou 3 dimensions (selon les caractéristiques du GPU) de blocs : $$ grid = \{ blocks \} $$
- un bloc (block) est un tableau à 1, 2 ou 3 dimensions de threads qui peuvent partager des ressources (shared memory). On parle également de CTA (Cooperative Threads Array) : $$ block = \{ threads \} $$
les blocs seront répartis sur les différents SM (Simultaneous Processors) pour être exécutés
Attention : en prévision de ce que nous verrons dans le chapitre suivant, le nombre maximum de threads dans un bloc est fixé par les caractéristiques de la carte (Compute Capability). Ce nombre maximum de threads sera de 512 ou 1024.
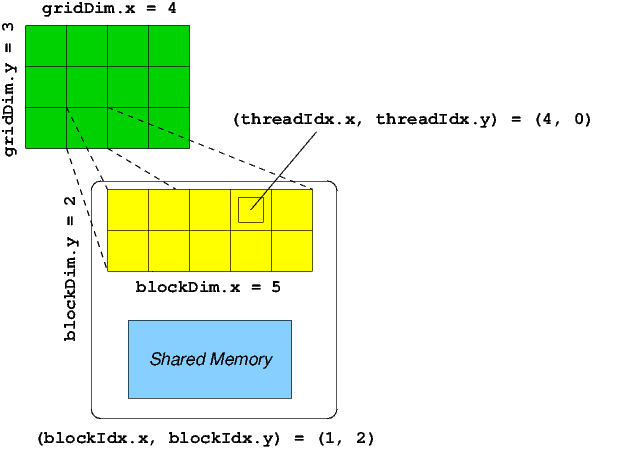
Exemple de grille 2D $(y=2 × x=3)$ avec blocs 2D $(y=3 × x=4)$
Certaines notions sont interchangeables :
- une grille est une matrice de blocs, on peut alors soit parler de grille ou du nombre de blocs de la grille
- un bloc est une matrice (grille) de threads : on peut parler de taille d'un bloc ou du nombre de threads dans un bloc.
Afin d'éviter toute confusion nous parlerons de grille et de bloc. On parlera :
- de la grille et de sa taille (X,Y,Z) en nombre de blocs
- d'un bloc et de sa taille (X,Y,Z) en nombre de thread
Dans l'exemple précédent, on dispose d'une grille de (2 x 3) blocs. Chaque bloc se compose de (3 x 4) threads. Au final on a donc $(2 × 3) × (3 × 4) = 72$ threads à exécuter.
Chaque thread à l'intérieur d'un bloc est identifié par une variable threadIdx (thread index) qui correspond à une structure (dim3) composée de trois champs x, y, z :
typedef struct {
int x, y, z ;
} dim3;
// variable locale au thread au sein du kernel
dim3 threadIdx ;
Cette structure matérialise un bloc de threads qui peut être modélisé par une, deux ou trois dimensions. On peut en fonction des besoins n'utiliser :
- qu'une dimension : le thread sera identifié dans le bloc par la coordonnée x (threadIdx.x)
- deux dimensions : le thread sera identifié par x et y (threadIdx.y)
- trois dimensions : le thread sera identifié par x, y et z (threadIdx.z)
Il faudra alors établir une formule de mise en correspondance avec les indices des données en entrée (qui sont des tableaux), le tout en fonction des coordonnées x, y et z.
Attention : il n'existe pas de variable qui permet d'identifier de manière unique un thread dans l'ensemble des blocs de la grille. C'est à l'utilisateur de réaliser le calcul.
3.1.1. Exemple 1
Par exemple, si les données en entrée sont codées sous forme d'un tableau à une dimension et que le kernel est exécuté par une grille d'un seul bloc :
- pour un bloc de threads d'une seule dimension ($\,D_x\,$) on utilisera la coordonnée $x$ qui correspond à l'indice i dans le tableau
- pour un bloc de threads à deux dimensions $(\,D_x,\, D_y\,)$ l'identifiant de thread de coordonnées $(x,y)$ sera donné par la formule : $$(\,x + y × D_x\,)$$
- pour un bloc de threads à deux dimensions $(\,D_x,\,D_y,\,D_z\,)$ l'identifiant de thread de coordonnées $(\,x,y,z\,)$ sera donné par la formule : $$(\,x + y × D_x + z × D_x × D_y\,)$$

3.1.2. Exemple 2
Voici un autre exemple simple qui s'appuie sur les données à traiter qui sont des tableaux à deux dimensions de float. Ici on n'a pas à établir de formule de correspondance car on établit une relation directe entre les indices de ligne et de colonne des tableaux avec respectivement y et x :
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
int x = threadIdx.x;
int y = threadIdx.y;
C[y][x] = A[y][x] + B[y][x];
}
int main() {
...
// use a block of N * N threads i.e. a grid of size (1,1,1) of (N,N,1) threads
dim3 grid(1,1,1);
dim3 block(N, N);
MatAdd<<< grid, block >>>(A, B, C);
}
Remarque : on aurait pu également utiliser des entiers lors de l'appel :
MatAdd <<< 1, N*N >>>(...)
Cependant, ici, on aura pas un bloc de dimension 2D (N,N) mais un bloc 1D de taille N*N ce qui ne permet pas d'établir la correspondance directe avec i et j. Il faudra alors utiliser la formule:
int y = blockIdx.x;
int x = threadIdx.x;
3.2. Appel d'un kernel
L'appel du kernel est réalisé grâce à l'utilisation de l'opérateur d'exécution de configuration :
kernel <<< ... >>>
Cet opérateur peut prendre entre deux et quatre paramètres :
kernel<<< grid, block, shared_mem*, stream* >>>
(* optionnel)
- grid ( dimensions de la grille) : représente soit un entier, soit un type dim3 et permet de spécifier la dimension de la grille telle que le produit grid.x * grid.y * grid.z correspond au nombre de blocs qui seront créés. Généralement grid.z = 1
- block (dimensions du bloc) : représente soit un entier, soit un type dim3 et définit la taille d'un bloc tel que le produit block.x * block.y * block.z sera égal au nombre de threads par bloc.
- shared_mem (mémoire partagée) : entier naturel qui spécifie la taille en octets de la mémoire partagée allouée par bloc. En général égale à 0 si on a pas de traitement spécifique qui nécessite de la mémoire partagée.
- stream : de type cudaStream_t argument optionnel égal à 0 par défaut qui permet de spécifier un Stream.
Voici quelques exemples d'appel:
kernel<<< 10, 32 >>>(..);
kernel<<< dim3(10), 32 >>>(..);
kernel<<< dim3(10,1,1), dim3(32) >>>(..);
dim3 grid(10);
dim3 block(32);
kernel<<< grid, block >>>(..);
L'appel à une fonction échouera si les paramètres sont erronés ou supérieurs aux tailles maximum définies par la Compute Capability du GPU. Il en va de même si on réserve plus de mémoire partagée que disponible.
Pour traiter, les erreurs, les fonctions CUDA retournent toutes un code d'erreur sauf l'appel au kernel puisqu'un kernel est de type void :
cudaError_t cudaGetLastError(void);
char* cudaGetErrorString(cudaError_t code);
Afin de gérer les erreurs éventuelles qui peuvent survenir il est recommandé de :
- vérifier que l'appel à chaque fonction ne produit pas d'erreur (allocation mémoire, copie des données)
- vérifier que durant l'exécution du kernel aucune erreur n'a été générée (ex: dépassement d'indice, débordement mémoire)
Pour cela on peut définir des macro-instructions en langage C. Le code suivant est issu du package CUME (CUda Made Easy)
- CODE
- cume macros
- // ------------------------------------------------------------------
- // definition of a macro instruction that checks if a CUDA function
- // was successull or not. If the execution of the function resulted
- // in some error we display it and stop the program
- // ------------------------------------------------------------------
- #define cume_check(value) { \
- cudaError_t err = value; \
- if (err != cudaSuccess) { \
- cerr << endl; \
- cerr << "============================================\n"; \
- cerr << "Error: " << cudaGetErrorString(err) << " at line "; \
- cerr << __LINE__ << " in file " << __FILE__; \
- cerr << endl; \
- exit(EXIT_FAILURE); \
- } \
- }
- // ------------------------------------------------------------------
- // Same as cuda_check but for kernel. This macro instruction is used
- // after the execution of the kernel (see the macros KERNEL_EXECUTE_NR
- // and KERNEL_EXECUTE_WR in cume_kernel.h)
- // ------------------------------------------------------------------
- #define cume_check_kernel() { \
- cudaError_t err = cudaGetLastError(); \
- if (err != cudaSuccess) { \
- cerr << endl; \
- cerr << "============================================\n"; \
- cerr << "Kernel Error: " << cudaGetErrorString(err) << " at line "; \
- cerr << __LINE__ << " in file " << __FILE__; \
- cerr << endl; \
- exit(EXIT_FAILURE); \
- } \
- }
- // check that cudaMalloc was executed successfully
- cume_check( cudaMalloc((void**) &x_gpu, SIZE * sizeof(float)) );
- // check that kernel was executed successfully
- sum<<< grid, block >>>(x_gpu, y_gpu, z_gpu, SIZE);
- cume_check_kernel();
3.2.1. Notion de stream
Un Stream représente une série d'opérations à exécuter.
Le stream "0" est complétement synchrone entre host et device et agit comme si on avait inséré l'instruction cudaDeviceSynchronize() avant chaque opération à exécuter sauf si on utilise une instruction asynchrone du type cudaMemcpy*Async
3.2.1.a Exemple de traitement synchrone
double *cmem = new double [ size ];
cudaMalloc(&gmem, size * sizeof(double) );
// completely synchronous
cudaMemcpy(gmem, cmem, SIZE * sizeof(double), cudaMemcpyHostToDevice);
kernel1<<<grid, block>>>(gmem, ...);
kernel2<<<grid, block>>>(gmem, ...);
cudaMemcpy(cmem, gmem, SIZE * sizeof(double), cudaMemcpyDeviceToHost);
3.2.1.b Exemples de traitement Asynchrones
Un premier cas de traitement asynchrone apparaît lorsque l'on exécute du code sur le CPU à l'intérieur d'une série d'instructions CUDA :
double *cmem = new double [ size ];
cudaMalloc(&gmem, size * sizeof(double) );
// completely synchronous
cudaMemcpy(gmem, cmem, SIZE * sizeof(double), cudaMemcpyHostToDevice);
kernel1<<<grid, block>>>(gmem, ...);
some_CPU_code();
kernel2<<<grid, block>>>(gmem, ...);
cudaMemcpy(cmem, gmem, SIZE * sizeof(double), cudaMemcpyDeviceToHost);
Un second cas apparaît avec l'utilisation des streams :
cudaStream_t stream1, stream2, ...;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMalloc( &dev1, size ) ;
cudaMallocHost( &host1, size ) ; // pinned memory required on host
...
cudaMemcpyAsync( dev1, host1, size, H2D, stream1 ) ;
kernel2 <<< grid, block, 0, stream2 >>> ( dev2, ...) ;
kernel3 <<< grid, block, 0, stream3 >>> ( dev3, ...) ;
cudaMemcpyAsync( host4, dev4, size, D2H, stream4 ) ;
some_CPU_code();
Pour de plus amples informations voir ce pdf.
3.2.2. Exemple
On considère l'exemple de la figure suivante pour laquelle on dispose :
- d'une grille 2D de $(3 × 4)$ blocs,
- chaque bloc 2D est composé de $(2 × 5)$ threads
CUDA définit pour le kernel à exécuter des variables de type dim3 :
- gridDim : dimensions de la grille (3, 4, 1)
- blockDim : dimensions d'un bloc (2, 5, 1)
- blockIdx : coordonnées du bloc courant à l'intérieur de la grille
- threadIdx : coordonnées du thread courant à l'intérieur d'un bloc
Au final on dispose d'un ensemble de $(3 × 4) × (2 × 5) = 120$ threads à exécuter qui seront exécutés par blocs de $(2 × 5)$ threads. A l'intérieur du kernel, pour connaître les coordonnées globales d'un thread par rapport à la grille, on utilise les formules suivantes (si la grille est de type 2D et si un bloc est de type 2D) :
int x = blockIdx.x * blockDim.x + threadIdx.x
int y = blockIdx.y * blockDim.y + threadIdx.y
Si chaque thread correspond à un élément d'un tableau stocké de manière linéaire en mémoire, on détermine l'offset de l'élément par la formule :
int offset = y * gridDim.x * blockDim.x + xPar exemple, le thread (y=1,x=3) du bloc (y=1,x=2) a pour valeurs :
x = 2 * 5 + 3 = 13
y = 1 * 2 + 1 = 3
offset = 3 * 4 * 5 + 13 = 73
|
|
|
| ||||||||||||||||||||||||||||||||||||||||
|
|
|
| ||||||||||||||||||||||||||||||||||||||||
|
|
|
|
Comme on peut le voir sur l'exemple précédent, les threads dans un bloc accèdent des éléments d'un tableau de manière linéaire pour chaque ligne. On verra qu'il est plus intéressant d'accèder des éléments consécutifs pour chaque bloc de threads, sinon on risque de dégrader les performances.
3.3. Etude de cas
3.3.1. Somme de longs vecteurs
Considérons le cas de la somme de longs vecteurs 1D. Quel doit être le choix de la taille de la grille ou la taille d'un bloc ?
3.3.1.a solution fixe avec un seul bloc + stride
Un première solution consiste à utiliser une grille composée d'un seul bloc, le bloc étant composé de plusieurs threads et on itère jusqu'à atteindre la taille du vecteur en se déplaçant du nombre de threads (=stride, en français foulée, enjambée, avancée).
const int VECTOR_SIZE = 20480; // = 512 * 40
const int NUMBER_OF_THREADS = 512;
__global__ void kernel_sum(float *x, float *y, float *z, int size) {
int tid = threadIdx.x;
while (tid < size) {
z[tid] = x[tid] + y[tid];
// stride of blockDim.x
tid += blockDim.x;
}
}
kernel_sum<<< 1, NUMBER_OF_THREADS >>>(x_d, y_d, z_d, VECTOR_SIZE);
Pour cette solution qui n'utilise que 512 threads:
- le thread 0 traitera les éléments du tableau d'indice : 0, 512, 1024, ...
- le thread 1 traitera les éléments du tableau d'indice : 1, 513, 1025, ...
- le thread i traitera les éléments du tableau d'indice : i, 512+i, 1024+i, ...
- le thread 511 traitera les éléments du tableau d'indice : 511, 1023, 1535, ...
| threads | time (ms) | occupancy |
| 16 | 37536.0 | 0.021 |
| 32 | 31115.9 | 0.021 |
| 64 | 15745.8 | 0.042 |
| 128 | 8002.9 | 0.083 |
| 256 | 4161.2 | 0.167 |
| 512 | 2118.1 | 0.333 |
| 1024 | 1165.3 | 0.667 |
On note que pour cette solution l'occupancy est faible, il en résulte des temps de calcul élevés par rapport à la solution suivante.
3.3.1.b solution adaptative avec plusieurs blocs
Une deuxième approche consiste à adapter la taille de la grille ou du bloc à la taille du vecteur en utilisant autant de blocs que nécessaire. Dans ce cas le nombre total de threads donnés par la taille de la grille et du bloc doit être supérieur ou égal au nombre de données à traiter.
Pour un vecteur de taille 20480 (20 * 1024) floats :
- si la taille maximale d'un bloc (sur la dimension x) est de 512, alors on a 40 (= 20480 / 512) blocs dans la grille
- si la taille maximale d'un bloc (sur la dimension x) est de 1024, alors on a 20 blocs dans la grille
const int VECTOR_SIZE = 20480;
const int NUMBER_OF_THREADS = 512;
int NUMBER_OF_BLOCKS = (VECTOR_SIZE + NUMBER_OF_THREADS - 1) / NUMBER_OF_THREADS;
__global__ void kernel_sum(float *x, float *y, float *z, int size) {
int gtid = threadIdx.x + blockIdx.x * blockDim.x;
z[gtid] = x[gtid] + y[gtid];
}
kernel_sum<<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS >>>(x_d, y_d, z_d, VECTOR_SIZE);
Quelle solution est la plus intéressante ? Vaut-il mieux avoir peu ou beaucoup de blocs ? Dans le cas présent, on pourrait choisir de prendre des blocs de 32 threads, ce qui donnerait une grille de 640 blocs.
Que faire si la taille de la grille n'est pas un multiple de 16, 32, ... ?
Voici quelques résultats sur GeForce GTX 560 Ti (10.000 itérations pour vecteur de taille 262.144 floats) :
| threads | time (ms) | occupancy |
| 16 | 1333.7 | 0.167 |
| 32 | 694.1 | 0.167 |
| 64 | 404.5 | 0.333 |
| 128 | 295.9 | 0.667 |
| 256 | 278.6 | 1.000 |
| 288 | 265.9 | 0.938 |
| 384 | 262.8 | 1.000 |
| 512 | 280.6 | 1.000 |
| 1024 | 369.6 | 0.667 |
On note que les temps les plus intéressants correspondent à une occupancy généralement maximum mais pas forcément.
3.3.1.c Nombre de threads important mais inférieurs au nombre de données à traiter
Enfin une troisième solution, similaire à la première consiste à disposer de nombreux threads (plus de 1024) mais moins que de données à traiter et à réaliser un stride.
const int VECTOR_SIZE = 20480;
const int NUMBER_OF_THREADS = 512;
int NUMBER_OF_BLOCKS = 4;
__global__ void kernel_sum(float *x, float *y, float *z, int size) {
int gtid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = gridDim.x * blockDim.x;
while (gtid < size) {
z[gtid] = x[gtid] + y[gtid];
gtid += stride;
}
}
kernel_sum<<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS >>>(x_d, y_d, z_d, VECTOR_SIZE);
Dans cet exemple on génère $4 × 512 = 2048$ threads, le stride est donc de 2048, on aura donc 10 itérations de la boucle while.
3.3.1.d Mesure des performances
Les mesures de performance des deux exemples précédents sont réalisées grâce à l'API CUDA.
CUDA fournit des compteurs ainsi que des fonctions associées pour gérer ces compteurs.
- CODE
- events
- // definition CUDA : typedef struct CUevent_st* cudaEvent_t;
- cudaEvent_t start, stop;
- cudaEventCreate(&start);
- cudaEventCreate(&stop);
- cudaEventRecord(start, 0); // current stream
- /* ....appel kernel.... */
- cudaEventRecord(stop, 0);
- cudaEventSynchronize(stop);
- float elapsedTime; // temp écoulé
- cudaEventElapsedTime(&elapsedTime, start, stop);
- printf("elapsed: %3.1f ms\n", elapsedTime);
- cudaEventDestroy(start);
- cudaEventDestroy(stop);
L'appel à cudaEventCreate réalise une allocation mémoire d'une structure de données, il faudra donc libérer l'espace alloué grâce à cudaEventDestroy.
On peut également utiliser l'utilitaire nvprof :
nvprof --unified-memory-profiling off program argumentsou son équivalent graphique nvvp (NVidia Visual Profiler).
Penser à utiliser également --print-gpu-trace ou --metrics achieved_occupancy