<< Page principale
3. Optimisation Combinatoire
3.1. Définition
L'Optimisation Combinatoire est une branche de l'optimisation en mathématiques appliquées et en informatique, également liée à la recherche opérationnelle, l'algorithmique et la théorie de la complexité. On parle également d'optimisation discrète car on travaille sur des domaines discrets (non continus).
On cherche la meilleure ou les meilleures solutions d'un problème par rapport à une fonction entière ou réelle appelée fonction de coût, de score ou fonction objectif. On cherche alors à maximiser ou minimiser cette fonction.
Certains problèmes d'optimisation combinatoire peuvent être résolus de manière exacte en temps polynomial par exemple par un algorithme glouton, un algorithme de programmation dynamique ou en montrant que le problème peut être formulé comme un programme linéaire en variables réelles.
Cependant, la majorité de ces problèmes sont NP-complets et pour les résoudre il est nécessaire de faire appel à d'autres techniques, dites heuristiques ou métaheuristiques, afin d'obtenir une solution approchée de manière à garantir l'obtention d'une solution en un temps raisonnable.
3.2. Types de problèmes
On s'intéresse à des problèmes d'optimisation pour lesquels on cherche une solution qui soit la meilleure. Nous allons notamment nous focaliser sur un modélisation sous forme de CSP (Constraint Satisfaction Problems).
On définit un Problème de Satisfaction de Contraintes par :
- un ensemble de domaines discrets : $D = \{ D_1, D_2, ..., D_n \}$
- un ensemble de variables $X = \{ x_1, x_2, ..., \x_n \}$, chaque $x_i$ prenant ses valeurs dans $D_i$
- un ensemble de contraintes $C = \{ C_1, ..., C_m \}$ qui s'expriment entre les variables
On peut augmenter ce cadre théorique avec une fonction objectif (appelée également fonction de coût ou de score) qui permet d'attribuer une valeur de qualité à une instanciation des variables : $$f : D_1 × ... × D_n → ℝ$$.
On peut alors tenter de rechercher la ou les meilleurs solutions par rapport à la fonction objectif. Il s'agit alors d'un problème d'optimisation sous contraintes.
Résoudre un CSP consiste alors :
- à trouver une instantiation des variables de $X$ qui satisfait les contraintes
- et dans le cas des CSP avec optimisation, à maximiser (ou minimiser) la fonction objectif $f$
Note : on remarquera que pour certains problèmes il peut y avoir moins de domaines que de variables (cf problème ci-après), les variables prenant généralement leurs valeurs dans un seul domaine.
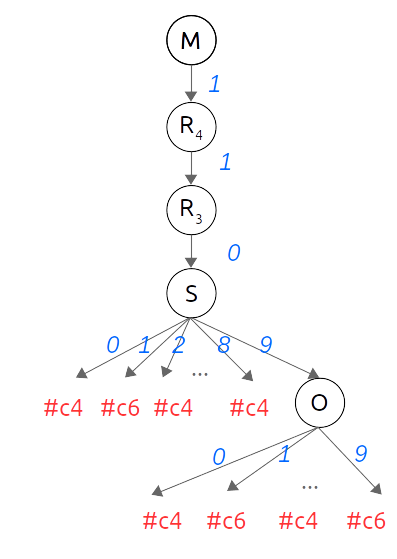
3.2.1. Exemple SEND + MORE = MONEY
Un cryptarithme ou jeu cryptarithmétique est un casse-tête numérique et logique qui consiste en une équation mathématique où les lettres doivent être remplacées par des chiffres, deux lettres ne pouvant pas avoir la même valeur. L'un des plus connus, car probablement le plus ancien, est le problème $SEND + MORE = MONEY$.

Pour résoudre ce genre de problème il est possible de le formuler comme un CSP :
- les domaines sont $D = \{ D_{digits}, D_{carries} \}$ avec
- $D_{digits} = \{ 0, ..., 9 \}$
- $D_{carries} = \{ 0, 1 \}$
- l'ensemble des variables est $V = \{ S, E, N, D, M, O, R, Y, R1, R2, R3, R4 \}$
- les variables $\{ S, E, N, D, M, O, R, Y \}$ prennent leurs valeurs dans $D_{digits}$
- les retenues $\{ R1, R2, R3, R4 \}$ prennent leurs valeurs dans $D_{carries}$
- les contraintes $C = \{ c_1, c_2, c_3, c_4, c_5, c_6 \}$ qui sont définies par :
- $c1$ (addition) : $D + E = Y + 10 × R1$
- $c2$ (addition) : $R1 + N + R = E + 10 × R2$
- $c3$ (addition) : $R2 + E + O = N + 10 × R3$
- $c4$ (addition) : $R3 + S + M = O + 10 × R4$
- $c5$ (égalité) : $R4 = M$
- $c6$ (différents) : alldiff($S, E, N, D, M, O, R, Y$)
Notes
il n'est pas nécessaire de définir une fonction objectif, mais elle peut être définie comme étant le nombre de contraintes non satisfaites, on doit donc la minimiser de manière à atteindre 0.
Les contraintes $c_1$ à $c_5$ peuvent être résumées par une seule contrainte :
$$ \table 10000 × M + 1000 × O + 100 × N + 10 × E + Y = ; 1000 × S + 100 × E + 10 × N + D + ; 1000 × M + 100 × O + 10 × R + E ; $$Dans ce cas, le problème est plus difficile à résoudre car le fait d'avoir plusieurs contraintes permet dès qu'une contrainte est violée de remettre en question les affectations d'un petit nombre de variables.
Résolution
La résolution utilise une méthode exacte pour ce genre de problème :
Ce problème peut être résolu efficacement avec un solveur comme Minizinc :
include "globals.mzn";
var 0..9: S;
var 0..9: E;
var 0..9: N;
var 0..9: D;
var 1..9: M;
var 0..9: O;
var 0..9: R;
var 0..9: Y;
var 0..1 : R1;
var 0..1 : R2;
var 0..1 : R3;
var 0..1 : R4;
array[1..8] of var int : letters = [S,E,N,D,M,O,R,Y];
constraint D+E=Y+10*R1;
constraint R1+N+R=E+10*R2;
constraint R2+E+O=N+10*R3;
constraint R3+S+M=O+10*R4;
constraint R4=M;
constraint all_different(letters);
solve satisfy;
output[" \(R4) \(R3) \(R2) \(R1)\n"];
output[" \(S) \(E) \(N) \(D)\n"];
output[" \(M) \(O) \(R) \(E)\n"];
output[" \(M) \(O) \(N) \(E) \(Y)\n"];
output[" SENDMORY = \(all)\n"];
On trouvera de nombreux autres exemples de cryptarithmes sur cette page comme :
- $HUIT + HUIT = SEIZE$
- $UN + UN + NEUF = ONZE$
Exercice 3.1
Installer Minizinc et résoudre le problème $HUIT + HUIT = SEIZE$.
3.2.2. Exemple les N-Reines
Le problème des N-reines consiste à placer sur un échiquier de $N × N$ cases, $N$ reines de manière à ce qu'aucune reine ne soit en prise avec une autre.
Ce problème a été posé en 1848 par un joueur d'échecs allemand, Max Bezzel, pour $N = 8$.
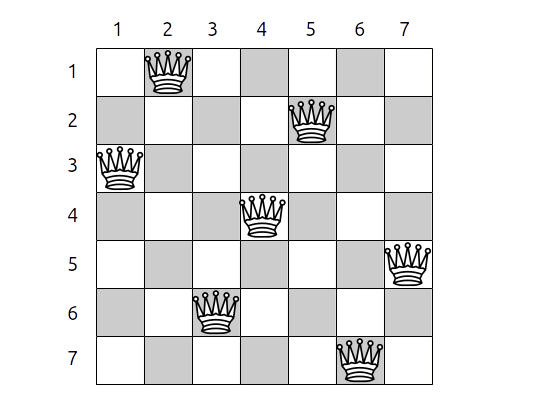
Solution pour N=7 |
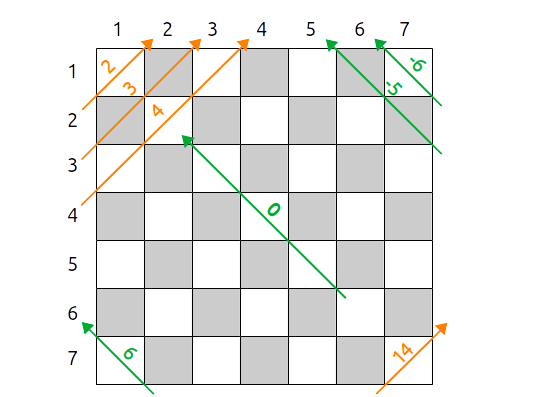
Diagonales droites (orange) et gauches (vert) |
Exercice 3.2
Exprimez ce problème sous forme de CSP en déterminant les variables, les domaines et en exprimant les contraintes sur les colonnes et les diagonales. Comment définir la fonction objectif ?
Voici l'expression du problème en Minizinc.
3.3. Méthodes de résolution des CSP
Voici quelques définitions préalables :
Une configuration est une affectation des variables du problème.
Une configuration partielle est une affectation d'une partie des variables du problème.
Une solution est une configuration qui respecte les contraintes du problème.
Toute configuration n'est pas forcément une solution, mais toute solution est une configuration.
L'espace de recherche du problème est l'ensemble des configurations distinctes du problème.
Une solution optimale $X^{⋆}$, également appelée optimum global, est une solution qui vérifie :
- $f(X^{⋆}) ≥ f(X)$ pour toute solution $X$, s'il s'agit d'un problème de maximisation
- $f(X^{⋆}) ≤ f(X)$ pour toute solution $X$, s'il s'agit d'un problème de minimisation
Une solution dite optimum local est une solution meilleure que celles qui l'entourent mais moins bonne que l'optimum global.
Plusieurs problèmes emblématiques peuvent être modélisés sous forme de CSP :
- problème du voyageur de commerce (Traveling Salesman Problem)
- problème du sac à dos (Knapsack)
- problème de couverture (Set Covering)
- problèmes liés aux graphes (isomorphisme)
- ...
3.4. Méthodes exactes ou complètes
Pour résoudre un CSP, on dispose de deux approches :
- les méthodes exactes également dites complètes
- ou les méthodes incomplètes ou dites inexactes ou approchées
Avantage
L'intérêt des méthodes exactes est qu'elles vont passer en revue l'ensemble des configurations réalisables du problème et si le problème admet une ou plusieurs solutions optimales, elles seront trouvées.
Inconvénient
Plus le problème est difficile, plus on va prendre de temps pour le résoudre. Certains problèmes sont trop volumineux (nombre de variables, taille des domaines, nombre de contraintes) et demandent trop de calculs pour pouvoir être résolus en un temps raisonnable.
3.4.1. Force brute, énumération exhaustive, recherche arborescente
La méthode la plus simple pour résoudre un problème consiste à réaliser l'énumération de ses configurations, cependant il faut obtenir une configuration qui soit une solution et déterminer si elle est meilleure que celles qu'on a pu trouver précédemment.
- force brute, énumération exhaustive : on réalise une énumération des configurations (lorsque cela est possible)
- recherche arborescente : on construit la solution en partant d'une configuration partielle vide, puis à chaque étape on énumère les valeurs d'une variable et on passe à la variable suivante si aucune contrainte n'est violée
- recherche arborescente avec réparation : on construit une configuration qui tente de satisfaire le plus de contraintes et on tente de la réparer, i.e. modifier des valeurs des variables afin de satisfaire de plus en plus de contraintes
La technique arborescente est intéressante car elle permet d'élaguer des branches de l'arbre de recherche et permet ainsi de ne pas passer en revue toutes les configurations existantes.
Certaines techniques dites heuristiques (du grec heuriskô qui signifie "je trouve") ont pour but de mener plus rapidement vers une solution, comme par exemple :
- l'ordre dans lequel les variables sont affectées
- l'ordre dans lequel les valeurs sont affectées aux variables
3.4.1.a Ordre des variables
L'ordre dans lequel on affecte les variables (cf. problème SAT) impacte le temps de résolution de manière importante. Avoir un ordre judicieux permet souvent de gagner beaucoup de temps en évitant les calculs inutiles (cf. problème SAT).
On peut par exemple choisir les variables les plus contraintes (qui participent au plus grand nombre de contraintes, ou appartenant à des contraintes alldiff).
3.4.1.b Ordre des valeurs du domaine
De la même manière, l'ordre dans lequel on choisit les valeurs à affecter aux variables influe sur le temps de résolution.
On peut alors mettre en oeuvre des techniques de consistance (on parle généralement d'arc-consistance) qui dès qu'on affecte une variable vont chercher les contraintes en relation avec la variable et supprimer des valeurs des domaines des autres variables ou restreindre ces domaines :
- par exemple pour une contrainte $\text"all_diff"(x_1, ..., x_n)$, avec des variables qui prennent leurs valeurs dans les domaines $D_i$, si on affecte la valeur 1 à $x_1$ alors on peut supprimer la valeur 1 des domaines des autres variables
- avec une contrainte du type $x_1 + x_2 ≤ 10$ et $x_1, x_2$ prenant leurs valeurs dans $D = \{ 1, ..., 10 \}$, si on attribue la valeur 8 à $x_1$, on sait que l'on peut garder uniquement les valeurs 1 et 2 pour $x_2$.
L'application de ces règles qui assurent la consistance du problème permettent d'éviter de faire des calculs dont on sait qu'ils ne méneront pas à une solution car les contraintes ne seront pas satisfaites.
3.4.2. Exemple des N-Reines
Reprenons le problème des N-Reines et voyons comment le résoudre par des méthodes exactes :
Solution pour N=7
Voici le nombre solutions en fonction de $N$ :
| N | Solutions |
| 2 | 0 |
| 3 | 0 |
| 4 | 2 |
| 5 | 10 |
| 6 | 4 |
| 7 | 40 |
| 8 | 92 |
| 9 | 352 |
| 10 | 724 |
| 11 | 2680 |
| 12 | 14200 |
Une configuration du problème peut être représentée sous forme d'un tableau ou d'une liste qui contient la colonne sur laquelle est placée une reine. L'indice du tableau ou de la liste représentant la ligne sur laquelle elle se trouve.
Pour la solution précédente (N=7), on aurait donc $(2,5,1,4,7,3,6)$, l'indice de la première ligne ou colonne commençant à 1 dans ce cas.
3.4.2.a Enumération exhaustive
On peut résoudre ce problème en réalisant une énumération exhaustive des configurations, il suffit de générer toutes les permutations possibles des valeurs $(1,2, ..., N)$.
Cependant, le nombre de permutations est de l'ordre de $O(n!)$.
| N | Permutations | Solutions | Python | C++ |
| 4 | 24 | 2 | 0.00 | 0.01 |
| 5 | 120 | 10 | 0.01 | 0.01 |
| 6 | 720 | 4 | 0.01 | 0.01 |
| 7 | 5040 | 40 | 0.01 | 0.01 |
| 8 | 40320 | 92 | 0.08 | 0.01 |
| 9 | 362880 | 352 | 0.73 | 0.15 |
| 10 | 3628800 | 724 | 7.42 | 1.77 |
| 11 | 39916800 | 2680 | 86.97 | 22.41 |
| 12 | 479001600 | 14200 | 1095.12 | 292.28 |
| 13 | 6227020800 | 73712 | ? | 3984.28 |
Voici le code python correspondant :

- from itertools import permutations
- import sys, time
- nbr_permutations = 0
- # méthode de résolution
- # basée sur les permutations
- def resoudre(n):
- global nbr_permutations
- columns = range(n)
- for board in permutations(columns):
- nbr_permutations = nbr_permutations + 1
- s1 = set(board[i] + i for i in columns)
- s2 = set(board[i] - i for i in columns)
- if n == len(s1) == len(s2):
- yield board
- # nombre de reines
- N = 8
- if len(sys.argv) > 1:
- N = int(sys.argv[1])
- print("reines=", N)
- t1 = time.time()
- ns = len(list(resoudre(N)))
- t2 = time.time()
- print("permutations=", nbr_permutations)
- print("solutions=", ns)
- print("temps de calcul=", t2-t1)
3.4.2.b Construction d'une solution
On crée une procédure récursive avec backtrack qui positionne la reine $r$ en colonne $c$ de manière à ce qu'elle ne soit pas en conflit avec une autre reine placée précédemment :
- si on trouve une position sans conflit, on passe à la reine $r+1$
- si il n'existe aucune position sans conflit, on revient à la reine $r-1$ que l'on tente de déplacer à une autre position
Cependant, on peut envisager différentes solutions pour construire la solution :
- méthode 1 : soit on positionne les reines sur un échiquier et dès qu'on désire savoir si la reine $r$ qu'on place en position $c$ est en conflit, on examine les lignes supérieures et les diagonales
- méthode 2 : soit dès qu'on positionne une nouvelle reine, on remplit sur l'échiquier la colonne $c$ et les diagonales vers le bas
- méthode 3 : soit on utilise trois tableaux pour représenter les colonnes et les deux diagonales
Méthode 1
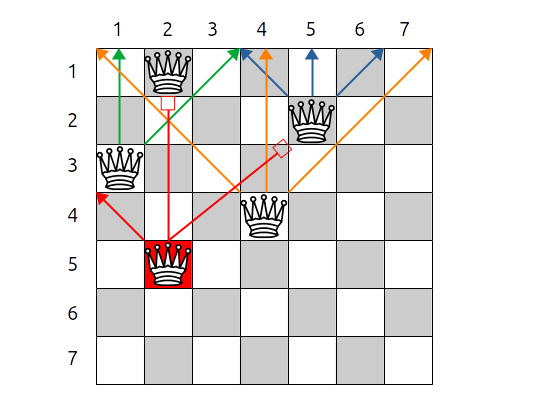
Voici le pseudo code utilisé pour la méthode 1.
- N est un entier // nombre de reines
- echiquier est une matrice[1..N][1..N] entier = 0
- // -------------------------------------------------
- // retourne vrai si il existe déjà une reine sur
- // la colonne x placée précédemment
- // -------------------------------------------------
- fonction conflit_colonne(y, x : entier) : booléen
- y2 est un entier = y - 1
- tant que y2 > 0 faire
- si echiquier[ y2 ][ x ] != 0 alors
- retourner vrai
- fin si
- y2 = y2 - 1
- fin tant que
- retourner faux
- fin fonction
- // -------------------------------------------------
- // retourne vrai si il existe déjà une reine sur
- // la diagonale droite x+y placée précédemment
- // -------------------------------------------------
- fonction conflit_diag_d(y, x sont des entiers) : booléen
- y2 est un entier = y - 1
- x2 est un entier = x - 1
- tant que y2 > 0 et x2 <= N faire
- si echiquier[ y2 ][ x2 ] != 0 alors
- retourner vrai
- fin si
- y2 = y2 - 1
- x2 = x2 + 1
- fin tant que
- retourner faux
- fin fonction
- // -------------------------------------------------
- // retourne vrai si il existe déjà une reine sur
- // la diagonale gauche x-y placée précédemment
- // -------------------------------------------------
- fonction conflit_diag_g(y, x sont des entiers) : booléen
- y2 est un entier = y - 1
- x2 est un entier = x + 1
- tant que y2 > 0 et x2 > 0 faire
- si echiquier[ y2 ][ x2 ] != 0 alors
- retourner vrai
- fin si
- y2 = y2 - 1
- x2 = x2 - 1
- fin tant que
- retourner faux
- fin fonction
- // -------------------------------------------------
- // résolution récursive, si il n'existe aucun conflit
- // pour placer la reine y dans la colonne x alors
- // on place la reine
- // puis on passe à la suivante
- // on supprime la reine de la position (y,x)
- // -------------------------------------------------
- procedure resoudre(y est un entier)
- si y <= N alors
- pour x de 1 à N faire
- si non(conflit_colonne(y,x) ou conflit_diag_d(y,x)
- ou conflit_diag_g(y,x)) alors
- echiquier[y][x] = y
- resoudre(y + 1)
- echiquier[y][x] = 0
- fin pour
- sinon
- print("solution")
- fin si
- fin procedure
Méthode 2
Voici le pseudo code utilisé pour la méthode 2.
- N est un entier // nombre de reines
- echiquier est une matrice[1..N][1..N] entier = 0
- // -------------------------------------------------
- // remplir dans l'échiquier
- // - la colonne x
- // - la diagonale droite y+x
- // - la diagonale gauche y-x
- // -------------------------------------------------
- procedure remplir(y, x sont des entiers)
- y2, x2 sont des entiers
- // remplir la colonne
- y2 = y
- x2 = x
- tant que y2 <= N faire
- echiquier[y2][x2] = echiquier[y2][x2] ou_binaire 2^y
- y2 = y2 + 1
- fin tant que
- // remplir la diagonale droite
- y2 = y + 1
- x2 = x + 1
- tant que y2 <= N et x2 <= N faire
- echiquier[y2][x2] = echiquier[y2][x2] ou_binaire 2^y
- y2 = y2 + 1
- x2 = x2 + 1
- fin tant que
- // remplir la diagonale gauche
- y2 = y + 1
- x2 = x - 1
- tant que y2 <= N et x2 > 0 faire
- echiquier[y2][x2] = echiquier[y2][x2] ou_binaire 2^y
- y2 = y2 + 1
- x2 = x2 - 1
- fin tant que
- fin procedure
- // -------------------------------------------------
- // même code que remplir sauf qu'il faut supprimer la puissance
- // de 2 :
- //
- // echiquier[y2][x2] = echiquier[y2][x2] et_binaire non(2^y)
- // -------------------------------------------------
- procedure effacer(y, x sont des entiers)
- ...
- fin procedure
- // -------------------------------------------------
- // Résolution récursive
- // -------------------------------------------------
- procedure resoudre(y est un entier)
- si y <= N alors
- pour x de 1 à N faire
- si echiquier[y][x] = 0 alors
- remplir(y,x)
- resoudre(y + 1)
- effacer(y,x)
- fin si
- fin pour
- sinon
- print("solution")
- fin si
- fin procedure
Méthode 3
On utilise trois tableaux d'entiers initialisés à 0 :
- colonnes[1..N], tel que colonnes[i] indique dans quelle colonne se trouve la reine en ligne $i$
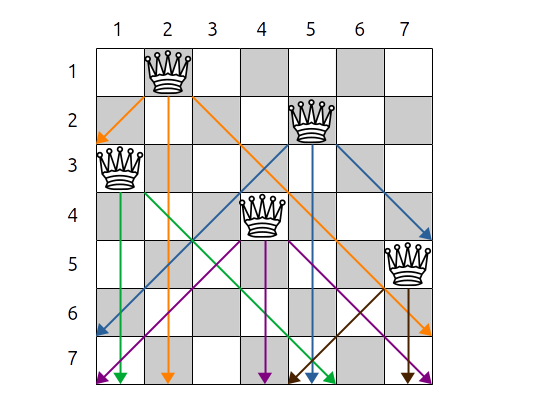
- diag_droite qui indique sur quelle diagonale droite se trouve une reine, par exemple la reine $i$ qui est en colonne $j$ est sur la diagonale droite $i-j$
- diag_gauche qui indique sur quelle diagonale gauche se trouve une reine, par exemple la reine $i$ qui est en colonne $j$ est sur la diagonale gauche $i+j$
Diagonales droites (orange) et gauches (vert)
Voici le pseudo code utilisé pour la méthode 3.
- colonnes est en tableau [1..N] entier = 0
- diag_droite est un tableau [2..2*N] entier = 0
- diag_gauche est un tableau [-(N-1) .. (N-1)] entier = 0
- procedure resoudre(y est un entier)
- si y <= N alors
- pour i de 1 à N faire
- si (colonnes[i] = 0) et (diag_droite[y+i] = 0)
- et (diag_gauche[y-i] = 0) alors
- colonnes[i] = y
- diag_droite[y+i] = y
- diag_gauche[y-i] = y
- resoudre(y+1)
- colonnes[i] = 0
- diag_droite[y+i] = 0
- diag_gauche[y-i] = 0
- fin si
- fin pour
- sinon
- print("solution")
- fin si
- fin procedure
Résultats
Les résultats présentés dans la table suivante montrent l'efficacité des trois méthodes.
| N | Méthode 1 | Méthode 2 | Méthode 3 |
| 8 | 0.00 | 0.00 | 0.00 |
| 9 | 0.00 | 0.00 | 0.00 |
| 10 | 0.00 | 0.00 | 0.00 |
| 11 | 0.00 | 0.00 | 0.00 |
| 12 | 0.04 | 0.00 | 0.00 |
| 13 | 0.24 | 0.03 | 0.02 |
| 14 | 1.46 | 0.22 | 0.15 |
| 15 | 9.37 | 1.41 | 1.03 |
| 16 | 64.19 | 9.31 | 7.20 |
| 17 | 462.73 | 64.69 | 54.12 |
La méthode trois qui utilise trois tableaux pour indiquer si une reine est dans une colonne, une diagonale droite ou une diagonale gauche, est la plus efficace.
Voici le code minizinc du problème des N-Reines :
include "globals.mzn";
int: N = 8;
array[1..N] of var 1..N: queens;
constraint alldifferent(queens);
constraint alldifferent([ queens[i] + i | i in 1..N]); % distinct diagonals
constraint alldifferent([ queens[i] - i | i in 1..N]); % upwards+downwards
% search
solve satisfy;
output [ if fix(queens[j]) == i then "Q" else "." endif ++
if j == N then "\n" else "" endif | i,j in 1..N]3.5. Méthodes inexactes, incomplètes ou approchées
Certaines instances de problèmes peuvent demander des siècles voire des millions ou milliards d'années pour être résolues par des approches exactes.
On décide alors de tenter de trouver une solution sous-optimale (que l'on espère proche de l'optimum global) en passant moins de temps à chercher mais en cherchant intelligemment.
Avantage
On ne s'intéresse qu'à une partie des configurations réalisables du problème, on mettra donc généralement moins de temps à résoudre le problème qu'avec une méthode exacte.
Inconvénient
On risque de ne pas trouver la ou les solutions optimales mais une ou des solutions approchées (sous optimales). Au final on ne sait pas si la solution trouvée est la solution optimale.
Ces méthodes sont souvent qualifiées de métaheuristiques. Une métaheuristique est un algorithme d’optimisation visant à résoudre des problèmes d'optimisation considérés comme difficiles.
On peut classer les métaheuristiques en grands groupes ou suivant leurs caractéristiques sachant qu'on peut également intégrer tel ou tel aspect d'une métaheuristique dans une autre métaheuristique :
- métaheuristiques à un voisin (Recherche Locale) ou à population (Algorithmes Génétiques, Mémétiques, Recherche en Ilots)
- métaheuristiques avec mécanisme de mémoire (Recherche Tabou)
- métaheuristiques basées sur des algorithmes évolutionnaires (Algorithmes Génétiques, Mémétiques, à Essaim Particulaire, Colonies de Fourmis)
- utilisation de voisinage dynamique (Variable Neighborhood Seach)
- utilisation de fonction objectif dynamique
- utilisation de plusieurs fonctions objectif (Multi-objectifs, front Pareto)
3.5.1. La recherche locale (Local Search)
Les méthodes fondées sur la recherche locale se basent sur la notion de voisinage d'une configuration.
Partant d'une configuration $X$, on définit par exemple les voisins ou le voisinage $N(X)$ de $X$ comme étant toutes les configurations $X'$ pour lesquelles on a modifié la valeur d'une des variables $x_i$.
On s'arrange pour que le voisinage soit inclus strictement dans l'ensemble des configurations et/ou qu'il soit plus petit que l'ensemble des configurations possibles.
La taille du voisinage va donc influer sur la recherche : plus le voisinage est grand, plus on pourra explorer d'espace de recherche, mais plus la recherche prendra du temps.
Le principe de la recherche locale également appelée descente ou hill-climbing consiste, partant d'une configuration donnée, à rechercher les voisins améliorants et à en choisir un parmi ceux existants. On s'arrête si on ne trouve pas de voisin améliorant.
- // cas d'un problème de maximisation
- // configuration courante
- X_c = configuration
- // indicateur de poursuite de la recherche
- // s'il est faux alors il n'y a plus de voisin améliorant
- continuer = vrai
- // tant qu'il existe un voisin améliorant, le choisir
- tant que continuer faire
- voisins_ameliorants = { }
- // rechercher les voisins améliorants
- pour tout X_n appartenant à N(X_c) faire
- si f(X_n) > f(X_c) alors
- voisins_ameliorants.ajouter( X_n )
- fin si
- fin pour
- // si pas de voisin améliorant, s'arrêter
- si voisins_ameliorants.est_vide() alors
- continuer = faux
- sinon
- // sinon choisir un voisin améliorant
- // qui devient la solution courante
- X_a = voisins_ameliorants.selection()
- X_c = X_a
- fin si
- fin tant que
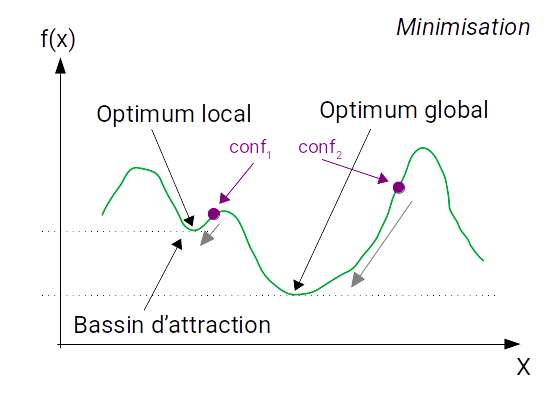
La recherche locale n'est généralement pas assez puissante et plusieurs problèmes se posent alors :
- on peut faire un mauvais choix de voisin (si il y en a plusieurs) et s'orienter vers un chemin qui ne permet pas d'atteindre la solution optimale
- la solution optimale peut ne pas être sur un chemin améliorant
- on peut être bloqué dans un optimum local
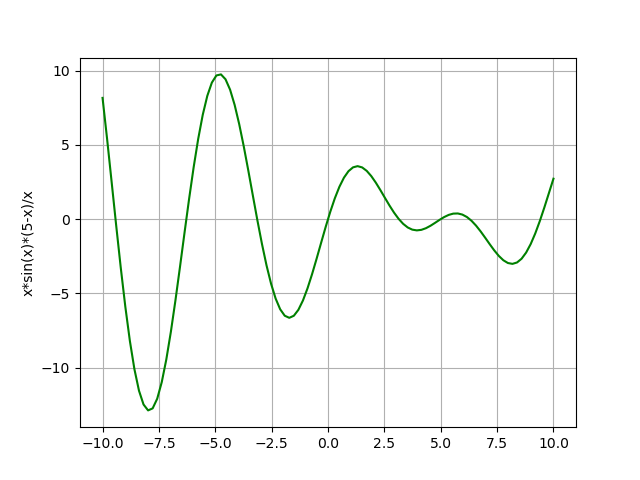
Voici une représentation explicative à une dimension mais il faut bien comprendre que l'on travaille en $n$ dimensions et que les courbes ne sont pas lisses.
Autre exemple :
Plusieurs variantes de la recherche locale existent :
- on peut examiner une partie des voisins en prenant le premier voisin améliorant
- on peut examiner tous les voisins et prendre le meilleur des voisins améliorants
- on peut autoriser le choix d'un voisin de même coût que la solution courante
Les problèmes liés aux méthodes inexactes et métaheuristiques qui en découlent sont liés à l'intensification et la diversification qui sont deux notions complémentaires et contradictoires :
- l'intensification consiste à se focaliser sur une configuration intéressante et à intensifier la recherche autour de cette configuration afin de trouver un meilleur voisin
- la diversification consiste à ne pas focaliser sa recherche autour d'une configuration mais à trouver des voisins plus prometteurs en explorant un plus grand espace de recherche
3.5.2. Recherche Locale Itérée (Iterated Local Search)
La recherche locale itérée consiste à lancer plusieurs fois une recherche locale en partant d'une une nouvelle solution à chaque étape. On gardera la meilleure solution obtenue.
3.5.3. Algorithme glouton (Greedy algorithm)
Le principe de l'algorithme glouton consiste à faire à chaque étape un choix optimum local dans l'espoir d'obtenir un résultat optimum global.
En d'autres termes, on cherche à chaque étape à faire le choix de la minimisation (ou de la maximisation) lors du choix d'une valeur à affecter à une variable.
Cette technique n'est probante que sur des problèmes simples, néanmoins elle peut être utilisée afin de construire une configuration initiale avant de lancer une descente ou une autre metaheuristique.
3.5.4. La recherche Tabou (Tabu Search)
La recherche tabou se fonde sur un mécanisme de mémorisation des configurations déjà visitées afin d'éviter de boucler. Ce mécanisme de mémorisation est appelée liste tabou. En fait il s'agit d'une liste de taille fixe et le fait d'ajouter un nouvel élément en fin de liste supprime l'élément le plus ancien en début de liste.
- $X_0$ = génerer une solution initiale
- $X_m$ = $X_0$
- liste_tabou = []
- while condition_d_arrêt non vérifiée faire
- $X_t$ = descente($X_c$, $N$)
- si $X_t ∉$ liste_tabou alors
- if f($X_t$) < f($X_m$) alors
- $X_m$ = $X_t$
- fin si
- $X_c$ = $X_t$
- liste_tabou.ajouter_en_fin($X_c$)
- fin si
- fin tant que
3.5.5. Le recuit-simulé (Simulated Annealing)
Le recuit simulé (Simulated Annealing) est une métaheuristique basée sur le travail de Metropolis (). Elle se fonde sur une analogie avec le recuit en métallurgie qui consiste par exemple à refroidir un alliage de manière progressive afin de lui conférer des propriétés autres que celles que l'on aurait obtenu avec un refroidissement brutal.
Le recuit simulé est une descente avec un probabilité d'accepter des solutions moins bonnes avec un facteur de probabilité (règle de Metropolis) qui décroit à mesure que le système se refroidit.
- $X_0$ = solution initiale
- $T_0$ = température initiale
- $T_f$ = température finale
- $α$ = facteur de refroidissement
- // on fixe la température courante
- $t$ = $T_0$
- $X_c$ = $X_0$
- // meilleure solution
- $X_m$ = $X_0$
- iteration = 1
- tant que $t ≠ T_f$ faire
- $X_v$ = generer_un_voisin( $X_c$, iteration, $N$ )
- $Δ_f$ = f($X_v$) - f($X_c$)
- $u$ = valeur aléatoire entre [0,1]
- si ($Δ_f$ < 0) ou (exp(-Δ_f / t) > $u$) alors
- $X_c$ = $X_v$
- fin si
- // garder la meilleure solution
- si f($X_c$) < f($X_m$) alors
- $X_m$ = $X_c$
- fin si
- iteration = iteration + 1
- $t$ = $α × t$
- fin tant que
- retourner $X_m$
La difficulté de la méthode repose sur les paramètres qui doivent être déterminés de manière empirique :
- la température initiale $T_0$
- la température finale $T_f$
- le facteur de refroidissement $α$
- le calcul et la gestion de l'exponentielle
Lien
3.5.6. Les algorithmes génétiques (Genetic Algorithms)
Les algorithmes génétiques comme leur nom l'indique se base sur la génétique et la reproduction cellulaire. Ils font partie des algorithmes à population et des algorithmes évolutionnaires c'est à dire qu'ils s'inspirent de la théorie de l'évolution.
On part d'un ensemble de configurations initiales qui constituent la population $P$. Cette population évolue au cours des générations. A chaque génération :
- on choisit deux individus (configurations) de la population $X_p$ le père et $X_m$ la mère
- on mixe ces deux solutions pour enfanter une nouvelle configuration $X_e$ (croisement - crossover)
- on soumet $X_e$ à une ou plusieurs mutations
- on évalue alors le nouvel individu et s'il est meilleur que l'un de ses deux parents il est ajouté à la population $P$ alors que le parent le moins bon comparativement à $f$ est supprimé de $P$ ou alors on élimine l'individu de la population qui est le moins bon
On pratique en quelque sorte un eugénisme.
- $P$ = ensemble de configurations
- $G$ = 500 // nombre maximum de générations
- pour generation de 1 à $G$ faire
- // choisir un père et une mère
- $X_p$, $X_m$ = choisir deux configurations distinctes dans $P$
- // générer un enfant par croisement
- $X_e$ = croisement($X_p$, $X_m$)
- // appliquer une mutation chez l'enfant
- $X_e$ = mutation($X_e$)
- // remplacer le père ou la mère par l'enfant si ce dernier
- // est meilleur que l'un de ses deux parents
- remplacement(P, $X_p$, $X_m$, $X_e$)
- fin pour
Le problème que l'on peut rencontrer, dû à l'eugénisme, est le fait qu'après un certain temps les individus peuvent être similaires ce qui empêche la recherche de trouver des solutions plus intéressantes.
Plusieurs variantes de cet algorithme existent : on peut par exemple générer plusieurs enfants, choisir non pas deux mais plusieurs parents et les combiner.
3.5.7. Les algorithmes mémétiques (Memetic Algorithms)
Un algorithme mémétique est simplement un algorithme génétique pour lequel on applique une descente sur l'enfant généré à partir des deux parents après mutation.
On va donc chercher à obtenir un enfant bien meilleur que ses parents.
3.5.8. Autres algorithmes et techniques
Il existe de nombreux autres algorithmes dont beaucoup sont inspirés de la nature comme :
- les algorithmes à colonies de fourmis (Ant Colony Optimisation)
- les algorithmes à essaims particulaires (Particle Swarm) : déplacement des oiseaux
- l'algorithme des abeilles
- l'algorithme du kangourou
- l'algorithme du singe
Certaines techniques peuvent être développées pour des problèmes particuliers :
- utilisation de symétries pour des problèmes de type SAT afin d'éviter des recherches inutiles
- analyse de solutions afin de déterminer ce qui est commun, différent ou constant (utilisation de techniques d'Apprentissage -- Machine Learning)
- partant de deux bonnes solutions, on peut chercher un chemin pour passer de l'une à l'autre (Path-Relinking) en espérant trouver une meilleure solution sur ce chemin
3.5.8.a Les algorithmes à colonies de fourmis (Ant Colony Optimzation)
On se base sur le comportement des fourmis qui recherchent de la nourriture. La nourriture étant ici une bonne solution.
On dispose d'une population de fourmis qui construisent des solutions et déposent sur les voies qu'elles empruntent des phéromones. Plus il y a de phéromones sur une voie, plus il y a de chance qu'il s'agissent d'un chemin qui mène à une bonne solution.
Cette technique est bien adaptée au problème du voyageur de commerce (cf. Wikipedia.
3.5.8.b Les algorithmes à Essaims Particulaires (Particle Swarm Optimization)
Les algorithmes à Essaims Particulaires reposent sur le principe d'auto-organisation d'un groupe d'organismes vivants (notamment les oiseaux) d'agir ensemble et d'exhiber un comportement complexe, à partir de comportements simples des individus, en respectant les règles suivantes :
- les individus sont attirés vers la position moyenne du groupe (cohésion)
- les individus suivent le même chemin que leurs voisins (alignement)
- les individus tentent d'éviter les collisions et gardent une certaine distance entre eux (séparation)
On pourra lire l'article suivant PSO (de Data Analytics Post) pour de plus amples explications.