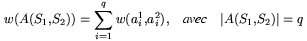La ressemblance ou similaritť de deux sťquences d'ADN peut Ítre expliquťe en prenant comme postulat de dťpart que toutes les espŤces sont issues d'un mÍme ancÍtre originel. Selon cette thťorie, des mutations ont eu lieu au cours de l'ťvolution gťnťrant des sťquences qui ont donnť naissance ŗ des espŤces de natures diffťrentes. La plupart des changements sont dus ŗ des mutations locales sur les brins d'ADN qui sont soient :
- des insertions d'un nuclťotide ou d'un ensemble de nuclťotides,
- des suppressions d'un nuclťotide ou d'un ensemble de nuclťotides,
- des substitutions d'un nuclťotide par un autre nuclťotide.
Deux sťquences peuvent donc Ítre proches ou ťloignťes. Il existe plusieurs degrťs de ressemblance (ou de similaritť) entre sťquences :
- l'identitť : deux sťquences sont dites identiques si elles se correspondent parfaitement. La notion d'identitť fait ťgalement rťfťrence au pourcentage de rťsidus identiques en regard dans un alignement,
- la similaritť : deux sťquences sont dites similaires si elles sont relativement proches sans toutefois Ítre identiques,
- l'homologie est un cas particulier de similaritť dans lequel on considŤre que deux sťquences similaires dťrivent d'un ancÍtre commun, c'est-ŗ-dire que les sťquences sont des ťvolutions d'une sťquence initiale commune pour laquelle certaines parties ont ťtť ajoutťes, supprimťes ou remplacťes.
Matrice de score
 |
L'opťration d'alignement consiste ŗ faire apparaÓtre le possible cheminement d'une ťvolution d'une sťquence par rapport ŗ une autre ou des deux sťquences par rapport ŗ un hypothťtique ancÍtre commun.
L'opťration d'alignement consistera donc ŗ mettre en regard les caractŤres de deux sťquences S1 et S2 de maniŤre ŗ ce que les sťquences se correspondent le mieux possible. Les sťquences n'ťtant de maniŤre gťnťrale pas strictement identiques on autorise le dťcalage des caractŤres en insťrant des espaces (ou gap) dans les sťquences.
Un alignement peut Ítre construit gr‚ce ŗ quatre opťrations de base :
- l'appariement (match) : (a,a), un caractŤre de la premiŤre sťquence est mis en regard d'un caractŤre identique dans la deuxiŤme sťquence,
- la substitution : (a,b), un caractŤre de la premiŤre sťquence est mis en regard d'un caractŤre diffťrent dans la deuxiŤme sťquence,
- l'insertion d'un gap dans S1 : (-,b)
- l'insertion d'un gap dans S2 : (a,-)
Remarque : l'insertion dans une sťquence peut ťgalement Ítre considťrťe comme une suppression (ou deletion en anglais) dans la sťquence en regard. On parle alors d'opťrateurs d'indel (INsertion-DELetion).
Exemple
Soient les sťquences S1 = {CATTGC} et S2 = {ACAGTC}. Un exemple d'alignement est :
La construction de cet alignement correspond ŗ la suite d'opťrations suivantes :
| (-,A) | insertion d'un gap dans S1 |
| (C,C) | appariement |
| (A,A) | appariement |
| (T,G) | substitution |
| (T,T) | appariement |
| (G,-) | insertion d'un gap dans S2 |
| (C,C) | appariement |
Cependant, d'autres alignements semblent tout aussi valables :
|
Afin de dťterminer le ou les meilleur(s) alignment(s), on attribue un coŻt ŗ chaque opťration d'alignement suivant une matrice de score (notťe w) et on tente d'optimiser le coŻt de l'ensemble de ces opťrations. Un exemple simple de matrice de score est la matrice identitť :