Ce site est en cours de reconstruction certains liens peuvent ne pas fonctionner ou certaines images peuvent ne pas s'afficher.
Cette page fait partie du cours de polytech PeiP1 et 2 Bio
9. Mise en pratique : Régressions Linéaires
9.1. Introduction
9.1.1. Fouille de données
On s'intéresse dans ce TP à la Fouille de Données (Data Mining) qui est un domaine de l'informatique qui, à partir d'ensembles de données brutes, tente d'établir des relations entre les données dans le but d'extraire des connaissances enfouies et donc non visibles à l'oeil nu ou que l'on ne peut déduire facilement car la relation qui lie les données est complexe.
Le manque de visibilité tient généralement au fait qu'il est difficile de voir ces relations d'autant plus que le volume de données est important.
Dans ce genre d'étude on considère un ensemble de données sous forme d'une matrice $D$ qui correspondent à $N$ individus ou objets (lignes de la matrice) décrits par $K$ propriétés ou colonnes ($P_1, ..., P_K$).
Parmi ces propriétés, on distingue :
- celles qui sont inutiles pour la recherche de la relation et qu'il faudra supprimer (n° identifiant, nom, ...)
- celles qui sont utiles et qui seront :
- soit quantitatives (poids, longueur, ...)
- soit qualitatives (0=mauvais, ..., 5=très bon)
Parmi les propriétés utiles $X$, on tente généralement de prédire l'une d'entre elles appelée la cible $y$ (target) en fonction des autres et que l'on va extraire de la matrice $X$.
La matrice initiale des données $D$ est donc composée des données inutiles $I$, des données utiles à l'établissement de la relation $X$ et de la cible $y$ :
$$ D(N,K) = [ X(N,K-Z-1), y(N,1), I(N,Z) ] $$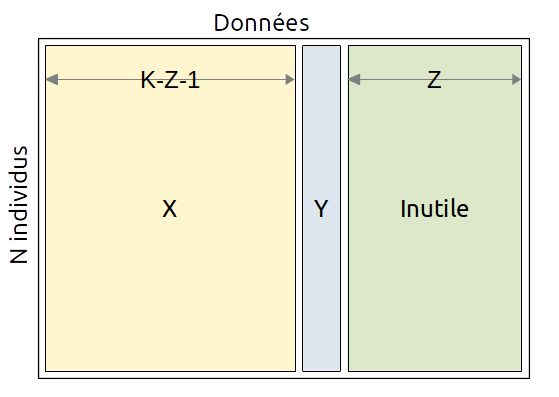
On cherche alors à trouver une fonction / relation $f$ telle que :
$$ y ≈ f(X) $$Une fois $f$ déterminée on pourra calculer $y' = f(X)$ et comparer $y$ à $y'$ afin de déterminer si $f$ établit bien une relation dès lors que $|y - y'|^2$ est proche de 0.
On pourra consulter ce document pour comprendre comment on trouve les coefficients de la droite.
9.1.2. Régression linéaire
La régression linéaire est un procédé simple qui permet de vérifier que des données sont corrélées, c'est à dire qu'elles sont liées par une relation linéaire du type $y = ax + b$.
La régression linéaire avec deux variables $(x,y)$ peut être étendue à plusieurs variables, on parle alors de régression linéaire multiple : $y = a_1 x_1 + a_2 x_2 + ... + a_n x_n + b$.
La droite ou l'hyperplan obtenu permet dans certains cas de classer (séparer) les données en deux classes, on parle alors de classifieur (issus de l'anglais classifier) mais le but de la régression est de rassembler les données plutôt que de les séparer. Nous verrons d'ailleurs que les SVM (Support Vector Machine) sont mieux adaptés à la classification.
En Apprentissage Automatique (Machine Learning) le rôle du classifieur est de classer dans des groupes (des classes) des données (individus) qui ont des propriétés similaires. Un classifieur linéaire est un type particulier de classifieur qui calcule la décision par combinaison linéaire des échantillons.
9.2. Régression linéaire simple
On considère un exemple simple de régression linéaire où à partir de données pour l'axe des $x$, on génère des points autour de la droite d'équation $y = 2x + 3$. La procédure à suivre est la suivante :
- définir la fonction $f(x) = 2x + 3$
- générer un vecteur $X$ de valeurs entre 1 et 20 par pas de 0.5 en utilisant numpy.arange
- générer le vecteur $y$ qui résulte de l'application de $f$ sur $X$ et auquel on ajoute des valeurs aléatoires entre -0.5 et +0.5 grâce à numpy.random.uniform
- utiliser la classe sklearn.linear_model.LinearRegression pour créer un modèle de régression :
Warning: file_get_contents(polytech/regression_lineaire_simple_create_model.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/regression_lineaire_simple_create_model.py
- calculer le modèle grâce à la méthode fit de la classe. Attention il faut modifier la forme de $X$ pour en faire une colonne et non une ligne !
- afficher intercept_ et coeff_
- calculer $y'$ à partir du modèle de régression et de $X$
- afficher $y$ et $y'$ sur le même graphique
- afficher les informations statistiques du modèle :
Warning: file_get_contents(polytech/regression_lineaire_simple_stats.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/regression_lineaire_simple_stats.py
On obtiendra par exemple le résultat suivant :
==================================================
Rubriques (axe des x) :
==================================================
[ 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5 6. 6.5 7. 7.5
8. 8.5 9. 9.5 10. 10.5 11. 11.5 12. 12.5 13. 13.5 14. 14.5
15. 15.5 16. 16.5 17. 17.5 18. 18.5 19. 19.5]
==================================================
y à prédire :
==================================================
[ 5.09610762 6.02063373 7.20869107 7.55953374 8.69358316 10.45456651
11.09560257 12.26032477 12.73454373 13.90524987 14.67045322 16.47500536
17.21316613 18.23809807 18.70526737 19.57808864 21.22759304 21.61884707
23.08646438 24.00087065 24.57424951 25.72739112 27.12351844 28.04040252
29.078628 30.2117482 31.21699936 32.21579627 32.50008577 33.7951452
35.35486701 35.7705316 36.73241912 38.40707455 38.91780429 40.15356994
41.01813109 42.08555222]
Calcul de la régresion...
coefficients : [2.00117446]
constante : 2.9818198074834257
==================================================
Prédiction : [ 4.98299427 5.9835815 6.98416873 7.98475596 8.98534319 9.98593042
10.98651765 11.98710488 12.98769211 13.98827934 14.98886657 15.9894538
16.99004103 17.99062826 18.99121549 19.99180272 20.99238995 21.99297718
22.99356441 23.99415164 24.99473887 25.9953261 26.99591333 27.99650056
28.99708779 29.99767502 30.99826225 31.99884948 32.99943671 34.00002394
35.00061117 36.0011984 37.00178563 38.00237286 39.00296009 40.00354732
41.00413455 42.00472178]
OLS Regression Results
===============================================================================
Dep. Variable: y R-squared: 0.999
Model: OLS Adj. R-squared: 0.999
Method: Least Squares F-statistic: 5.946e+04
Date: sam., 08 févr. 2020 Prob (F-statistic): 1.56e-59
Time: 15:43:41 Log-Likelihood: -4.1622
No. Observations: 38 AIC: 12.32
Df Residuals: 36 BIC: 15.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.9818 0.095 31.257 0.000 2.788 3.175
x1 2.0012 0.008 243.847 0.000 1.985 2.018
==============================================================================
Omnibus: 4.839 Durbin-Watson: 2.176
Prob(Omnibus): 0.089 Jarque-Bera (JB): 1.959
Skew: -0.156 Prob(JB): 0.375
Kurtosis: 1.932 Cond. No. 24.8
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Pour simplifier, on a une régression linéaire si :
- R^2 (R-squared) est proche de 1.0
Mais il est toujours préférable de dessiner des données afin de vérifier qu'elles sont bien linéaires.
Les coefficiens doivent être pris en compte si P > |t| est proche de 0 et généralement inférieur à $0.05$.
On peut également regarder le coefficient Kurtosis qui représente une mesure de l'aplatissement des données mais pour une gaussienne. S'il est normalisé il est proche de 0, s'il est non normalisé il est proche de 3. Ici le coefficient est non normalisé, il est donc inférieur à 2 ce qui tendrait à dire que les données ne sont pas applaties or elles le sont.
Si le Kurtosis est non normalisé on considère que les données sont aplaties dans l'intervalle $[2,4]$ et non aplaties en dehors de cet intervalle.
Exercice 9.1
On considère les données du Quartet d'Anscombe.
Etablir pour chaque couple $(x_i,y_i)$ la régression linéaire simple et afficher les informations concernant la régression (OLS regression results).
Warning: file_get_contents(polytech/regression_lineaire_anscombe.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/regression_lineaire_anscombe.py
Etudier les paramètres suivants :
- $R^2$
- Prob (F-statistic)
- Kurtosis
- P > |t| pour les coefficients
9.3. Régression linéaire multiple en Python
9.3.1. Cas d'école
Etant donné un ensemble d'individus, connaissant leur nom, leur sexe, leur age, leur taille et leur poids, on se demande s'il est possible d'établir une relation linéaire qui permettrait de calculer le poids en fonction des autres données.
regression_lineaire_multiple.py
Warning: file_get_contents(polytech/regression_lineaire_multiple.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/regression_lineaire_multiple.py
9.3.2. Campagne de publicité
Nous allons considérer l'exemple advertising.csv qui est un fichier de données qui donne le millier d'unités vendues (Sales) pour un produit donné en fonction du budget marketing en milliers de dollars par le moyen de la télévision (TV), la Radio (radio) et des journaux (newspaper).
Premièrement, on charge le fichier .csv grâce à pandas et on récupère en retour un DataFrame qui est une classe pandas. On affiche ensuite les premières lignes du fichier.
Warning: file_get_contents(polytech/lr_ex1_load_data.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_load_data.py
On s'aperçoit que la première colonne, appelée 'Unnamed: 0', n'a aucun intérêt pour la prédiction car elle représente un identifiant de ligne (variant de 1 à 200), il faut donc la supprimer grâce à la méthode drop du dataframe :
|<-- colonne DataFrame
|
Unnamed: 0 TV Radio Newspaper Sales
0 1 230.1 37.8 69.2 22.1
1 2 44.5 39.3 45.1 10.4
2 3 17.2 45.9 69.3 9.3
3 4 151.5 41.3 58.5 18.5
4 5 180.8 10.8 58.4 12.9
On trace ensuite un pair plot avec seaborn afin d'identifier des régressions linéaires potentielles :
Warning: file_get_contents(polytech/lr_ex1_pair_plot.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_pair_plot.py
Exercice 9.2
Y a t-il des régressions linéaires entre deux variables sur le graphe obtenu ?
La matrice de corrélation permet également d'identifier des relations :
Warning: file_get_contents(polytech/lr_ex1_corr_plot.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_corr_plot.py
On tente d'établir une régression linéaire multiple de manière à savoir si les campagnes marketing (TV, Radio, Journaux) ont une influence sur le résultat des ventes :
$$ Sales = constante + a_1 × TV + a_2 × Radio + a_3 × Newspaper $$Warning: file_get_contents(polytech/lr_ex1_reg_lin.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_reg_lin.py
Dès lors, on peut afficher les coefficients de la relation :
Warning: file_get_contents(polytech/lr_ex1_reg_lin_expr.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_reg_lin_expr.py
Il faut ensuite déterminer quelles variables sont pertinentes pour la relation.
Warning: file_get_contents(polytech/lr_ex1_reg_lin_stats.py): Failed to open stream: No such file or directory in /home/jeanmichel.richer/public_html/ez_web.php on line 418
Afficher le code polytech/lr_ex1_reg_lin_stats.py
Le meilleur moyen est d'utiliser la p-value qui permet ou non de rejeter l'hypothèse nulle, c'est à dire le fait qu'il n'y a pas de relation de corrélation entre une variable des caractéristiques et la variable à prédire.
Si la p-value est inférieure à 0.05 alors la variable est corrélée à la variable à prédire.
===============================================================================
Dep. Variable: Sales R-squared: 0.897
Model: OLS Adj. R-squared: 0.896
Method: Least Squares F-statistic: 570.3
Date: jeu., 06 févr. 2020 Prob (F-statistic): 1.58e-96
Time: 18:22:19 Log-Likelihood: -386.18
No. Observations: 200 AIC: 780.4
Df Residuals: 196 BIC: 793.6
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.9389 0.312 9.422 0.000 2.324 3.554
TV 0.0458 0.001 32.809 0.000 0.043 0.049
Radio 0.1885 0.009 21.893 0.000 0.172 0.206
Newspaper -0.0010 0.006 -0.177 0.860 -0.013 0.011
==============================================================================
Omnibus: 60.414 Durbin-Watson: 2.084
Prob(Omnibus): 0.000 Jarque-Bera (JB): 151.241
Skew: -1.327 Prob(JB): 1.44e-33
Kurtosis: 6.332 Cond. No. 454.
==============================================================================
On voit donc qu'a priori les journaux (newspaper) n'ont pas d'influence sur la relation linéaire.
Exercice 9.3
Afficher sous forme de graphique 3D la propriété à prédire et celle prédite en fonction de TV et Radio. Que remarque t-on ?
Exercice 9.4
Quels résultats (combien d'unités seront vendues) avec les budgets suivants :
- [57.0, 32.0, 23.0] (TV, Radio, Newspaper)
- [23.0, 32.0, 78.0] (TV, Radio, Newspaper)
Que peut-on dire de ces résultats, sont-ils valides ?
Exercice 9.5
On s'intéresse à la durée de la période de gestation de femmes ayant fumé ou pas pendant leur grossesse.
On dispose d'un fichier de 32 femmes et leurs enfants pour lesquels on a les données suivantes :
- Wgt : poids en grammes du bébé à la naissance
- Gest : durée de la période de gestation en semaines
- Smoke : le fait que la maman ait fumé (yes) ou non (no)
Dessiner un graphique avec la période de gestation en fonction des fumeuses ou non fumeuses.
Note : les données sont disponibles ici.