Ce site est en cours de reconstruction certains liens peuvent ne pas fonctionner ou certaines images peuvent ne pas s'afficher.
Pandas
Pandas est un paquet Python qui permet de manipuler des données sous forme de tableaux à une ou plusieurs dimensions. Un tableau à une dimension est appelé Series alors qu'un tableau à deux dimensions est qualifié de Dataframe. On peut également manipuler des tableaux à trois dimensions (Panel) ou à quatre dimensions (Panel4D).
Pandas permet notamment d'extraire ou de remplacer des données de manière simple, de récupérer des données depuis des fichiers CSV et d'analyser les données en interagissant avec d'autres paquets.
1.1. Définition d'un DataFrame
Il existe une multitude de manières de définir un DataFrame avec Pandas. Voici un exemple concret avec des personnes dont on connait les caractéristiques (nom, age, sexe, poids, taille).
Le DataFrame est une matrice dont les lignes sont des individus ou des objets et les colonnes sont les propriétés associées à ces individus. L'intérêt des Dataframe et qu'ils permettent de manipuler plusieurs colonnes avec des types différents (entier, réel, chaîne de caractères) alors qu'avec numpy> les données doivent être du même type.
1.1.1. Description des données sous forme de listes
Afficher le code
- import pandas as pd
- # listes des ages, poids, sexe, noms
- ages = [ 20, 10, 15, 30, 45, 18 ]
- poids = [ 80, 25, 35, 120, 75, 41 ]
- sexe = [ 'M', 'F', 'F', 'M', 'M', 'F' ]
- noms = [ 'John', 'Julia', 'Janet', 'Jack', 'Jeff', 'Jane' ]
- # création d'une matrice de 6 lignes par 4 colonnes sous forme
- # de tuples
- l = list(zip(noms,sexe,ages,poids))
- print("zip = ", l)
- df = pd.DataFrame( data = l , columns=['nom','sexe','age','poids'])
- print(df)
1.1.2. Sous forme de fichier CSV
Attention : ne surtout pas mettre d'espace entre les champs dans la définition de StringIO sinon certaines valeurs ne serons pas reconnues. Par exemple pour :
"John","M",20,80
La chaine "M" sera reconnue comme tel, mais si on écrit :
"John", "M",20,80
La même valeur sera reconnue en tant que ' "M"'
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv( data = donnees, sep=",")
- print(df)
1.2. Informations d'un DataFrame
Les informations concernant le DataFrame sont par exemple :
- la propriété shape : nombre de lignes et de colonnes sous forme d'un tuple
- la propriété index : nombre de lignes sou forme d'un range
- la propriété dtypes qui donne le type de chaque colonne
- le fonction describe() qui donne une description statistique des données numériques
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- print("shape=", df.shape)
- print("index=", df.index)
- print("=== types ====\n", df.dtypes)
- print("=== description ===\n", df.describe())
shape= (6, 4)
index= RangeIndex(start=0, stop=6, step=1)
=== types ====
nom object
sexe object
age int64
poids int64
dtype: object
=== description ===
age poids
count 6.000000 6.000000 # nombre de données
mean 23.000000 62.666667 # moyenne des données
std 12.649111 35.758449 # écart type
min 10.000000 25.000000 # valeur minimum
25% 15.750000 36.500000 # centiles
50% 19.000000 58.000000 #
75% 27.500000 78.750000 #
max 45.000000 120.000000 # valeur maximum
1.3. Manipulation d'un DataFrame
1.3.1. Renommer les colonnes
La variable inplace à vrai permet de ne pas refaire l'assignation du DataFrame.
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- df.rename(columns={'nom': 'name', 'sexe': 'sex'}, inplace=True)
- print(df.head())
1.3.2. Supprimer des colonnes
La variable inplace à vrai permet de ne pas refaire l'assignation du DataFrame.
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- df1 = df.drop(['nom','sexe'], 1)
- print(df1)
- #
- # ou utiliser :
- #
- df.drop(['nom','sexe'], 1, inplace=True)
- print(df.head())
1.3.3. Extraire des colonnes
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- df_age_poids = df[ ['age', 'poids'] ]
- print(df_age_poids)
1.3.4. Sélectionner des lignes
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- # sélection des lignes paires
- df1 = df.loc[ 0:6:2 ]
- print(df1)
- # sélection des colonnes 'sexe' à 'poids'
- # pour les lignes paires
- df2 = df.loc[ 0:6:2, 'sexe':'poids' ]
- print(df2)
- # sélection des colonnes 'sexe' et 'poids'
- # pour les lignes impaires
- df3 = df.loc[ 1:7:2, ['sexe','poids'] ]
- print(df3)
1.3.5. Sélection suivant critères
Afficher le code
- from io import StringIO
- import pandas as pd
- donnees = StringIO("""nom,sexe,age,poids
- "John","M",20,80
- "Julia","F",10,25
- "Janet","F",15,35
- "Jack","M",30,120
- "Jeff","M",45,75
- "Jane","F",18,41
- """)
- df = pd.read_csv(donnees, sep=",")
- #
- # Sélection des hommes de plus de 20 ans
- # on réalise le traitement de deux manières différentes
- #
- df1 = df.loc[ (df.sexe.str.contains("M")) & (df.age > 20)]
- print(df1)
- df2 = df[ (df.sexe == "M") & (df.age > 20)]
- print(df2)
1.4. Modification des données
Le fichier CSV suivant qui contient des données sur les iris de Fisher possède des noms de colonnes que l'on désire modifier et une colonne "variety" que l'on désire transformer en une valeur : 0 pour Setosa, 1 pour Versicolor et 2 pour Virginica.
"sepal.length","sepal.width","petal.length","petal.width","variety"
5.1,3.5,1.4,.2,"Setosa"
4.9,3,1.4,.2,"Setosa"
4.7,3.2,1.3,.2,"Setosa"
4.6,3.1,1.5,.2,"Setosa"
...
6.3,2.5,5,1.9,"Virginica"
6.5,3,5.2,2,"Virginica"
6.2,3.4,5.4,2.3,"Virginica"
5.9,3,5.1,1.8,"Virginica"
Afficher le code
- import pandas as pd
- iris = pd.read_csv("http://www.info.univ-angers.fr/~richer/polytech/iris.csv", sep=",")
- print(iris.head())
- iris.columns = ["sl","sw","pl","pw","sp"]
- print(iris.head())
- def conv_species(x):
- if x == "Setosa":
- return 0
- if x == "Versicolor":
- return 1
- if x == "Virginica":
- return 2
- iris.sp = iris.sp.apply( conv_species )
- print(iris)
1.5. Interaction avec seaborn
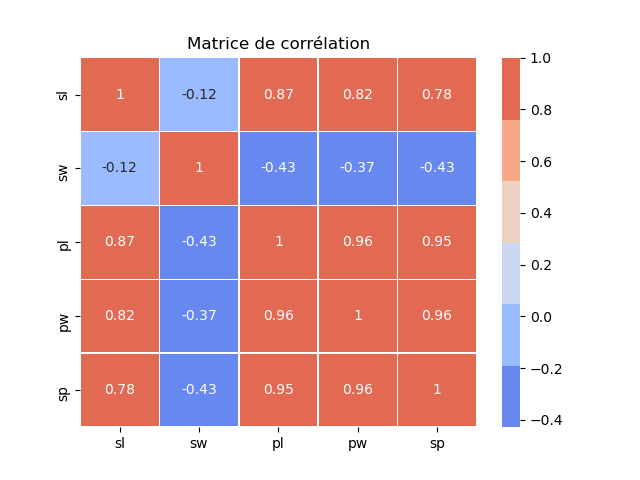
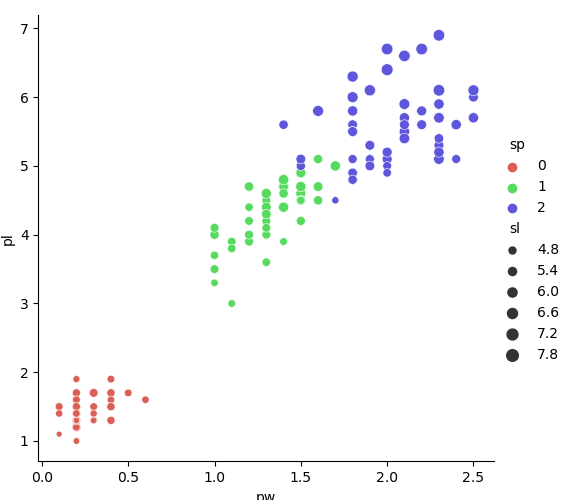
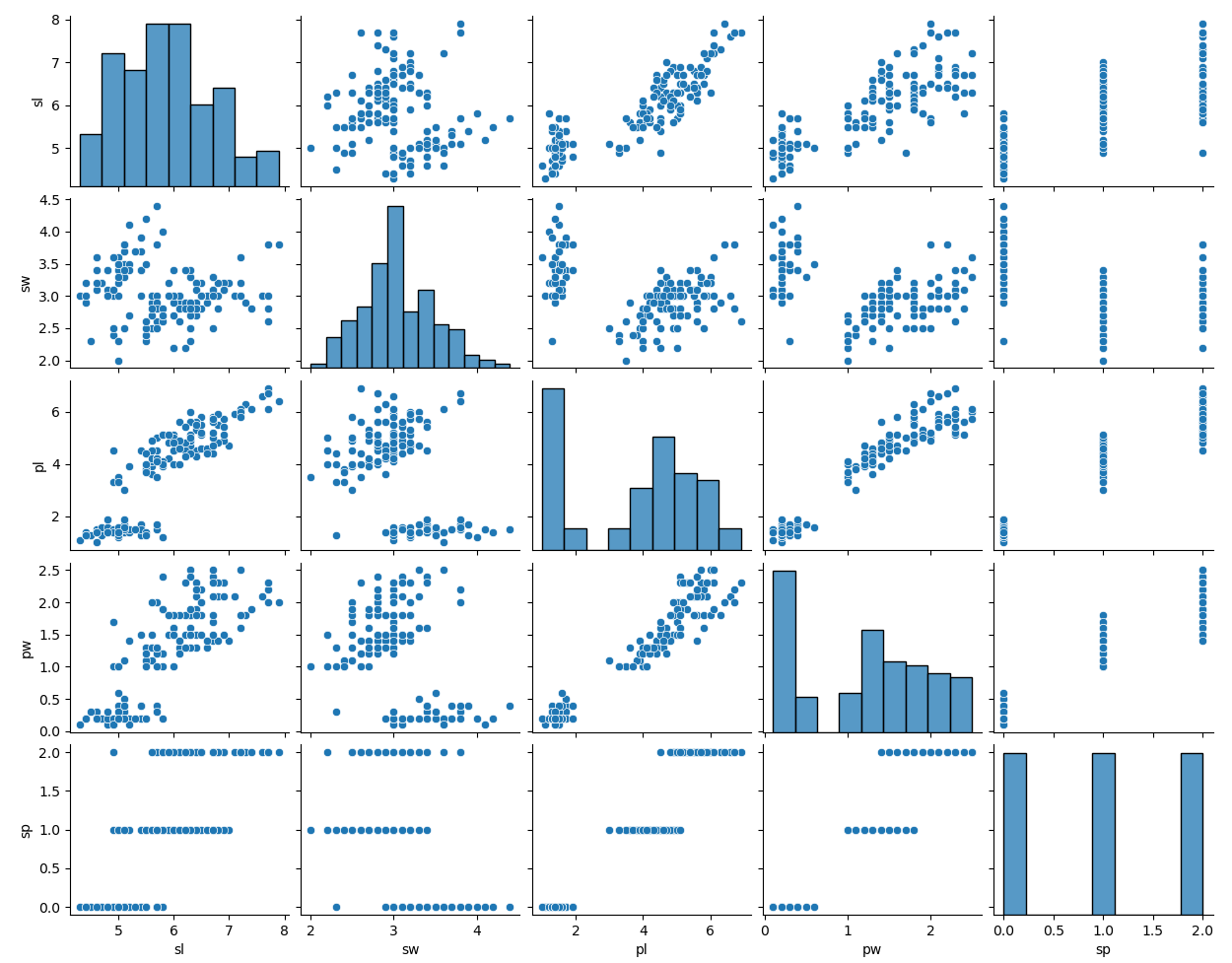
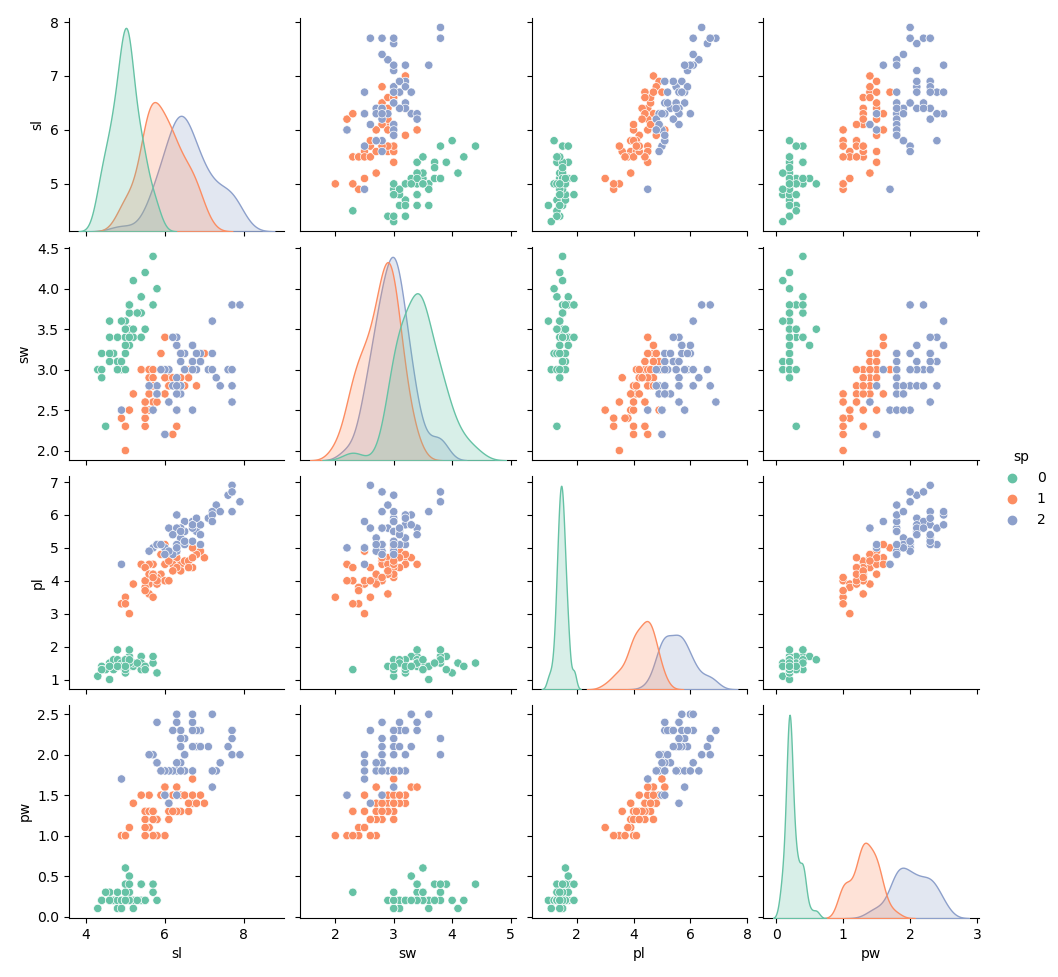
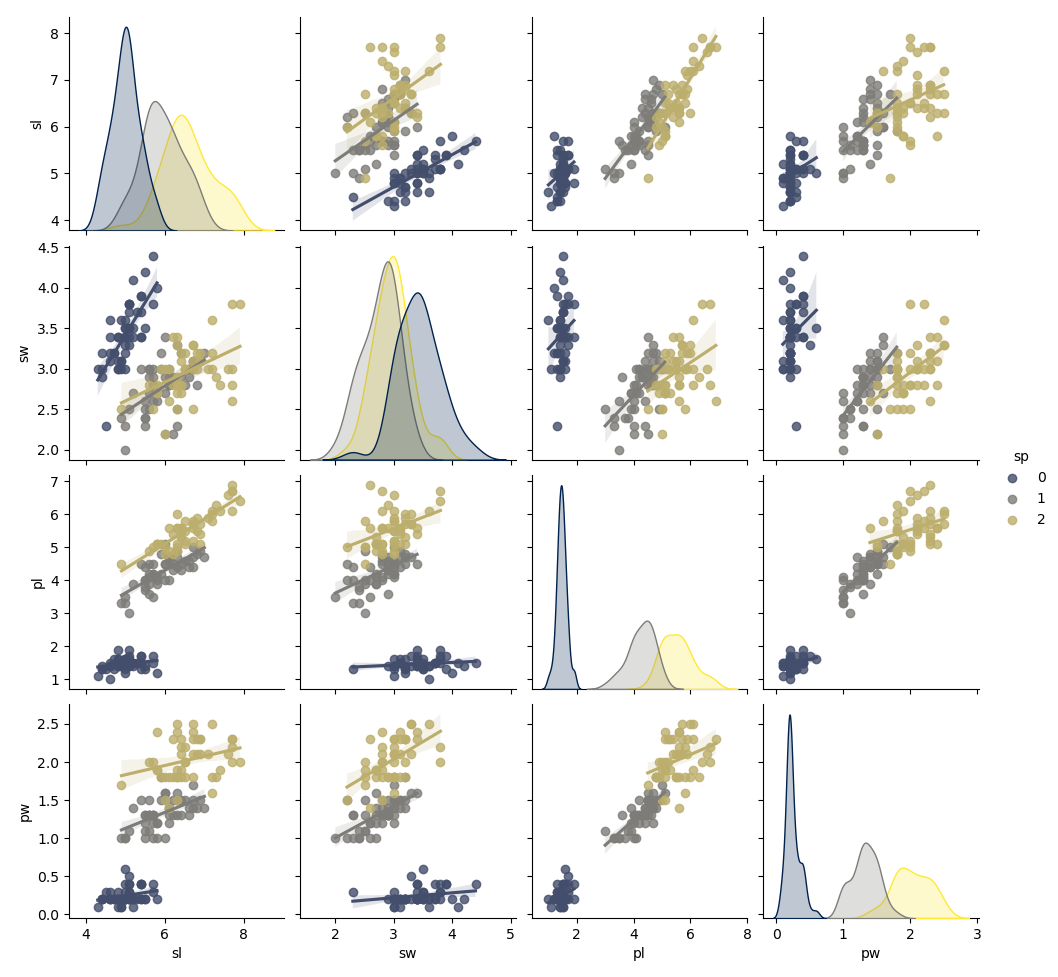
Le paquet seaborn est une librairie de visualisation de données basée sur matplotlib. Elle permet par exemple d'afficher une matrice de corrélation des données ou des pairplot qui donne un aperçu visuel des relations existantes entre les données.
Afficher le code
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- iris = pd.read_csv("http://www.info.univ-angers.fr/~richer/polytech/iris.csv", sep=",")
- print(iris.head())
- iris.columns = ["sl","sw","pl","pw","sp"]
- print(iris.head())
- def conv_species(x):
- if x == "Setosa":
- return 0
- if x == "Versicolor":
- return 1
- if x == "Virginica":
- return 2
- iris.sp = iris.sp.apply( conv_species )
- # correlation matrix
- corr = iris.corr()
- sns.heatmap(corr, cmap=sns.color_palette("coolwarm"), linewidths=.5, \
- annot=True, xticklabels=corr.columns.values, \
- yticklabels=corr.columns.values)
- plt.title("Matrice de corrélation")
- plt.show()
- # relational plot
- cmap = sns.color_palette("hls", len(set(iris.sp)))
- g = sns.relplot(data=iris, x="pw", y="pl",
- hue="sp", size="sl", palette=cmap)
- plt.show()
- # pairplots
- sns.pairplot(iris, corner=True)
- sns.pairplot(iris, hue="sp", palette= 'Set2', kind='scatter')
- sns.pairplot(iris, hue="sp", palette= 'cividis', kind='reg')
- plt.show()
On voit notamment la corrélation entre :
- la longueur des pétales (pl) et l'espèce (sp = variety)
- la largueur des pétales (pw) et l'espèce (sp = variety)
- la longueur des pétales (pl) et la largeur des pétales (pw)