Tri Fusion avec vecteur SSE
1.1. Introduction
Le but de ce projet est de comparer deux implantations du tri fusion (merge sort) sur les entiers 32 bits :
- la première est une implantation classique
- la seconde utilise un tri de quatre entiers adjacents dans un registre vectoriel SSE
En triant quatre valeurs dans un registre SSE, on se trouve confronté à trois problèmes majeurs :
- Le premier tient au fait que le réordonnancement des quatre entiers sera réalisé
par l'instruction PSHUFD qui n'admet qu'un paramètre constant.
On fait le choix ici de modifier ce paramètre à la volée dans le code.PSHUFD xmm0, xmm1/m128, imm8 - Le second concerne la modification de l'instruction qui n'est pas possible directement dans le segment de code car celui-ci est protégé en écriture. On peut alors, soit mettre le code dans la section de données ou alors utiliser mprotect pour rendre le segment de code inscriptible. Nous testerons les deux possibilités.
- Enfin, afin de déterminer la valeur imm8 qui indique comment seront réordonnées les valeurs, il est nécessaire de trouver un moyen qui permet de manière unique de savoir comment faire. Nous calculerons donc une valeur servant d'identifiant, mais pour obtenir cette valeur de manière efficace il faut utiliser l'instruction PEXT qui fait partie du jeu d'instructions BMI (Bit Manipulation). Il y a deux jeux d'instructions (BMI1 et BMI2) introduits à partir de l'architecture Haswell (2013). Certains ordinateurs anciens ne comportent donc pas ce jeu d'instruction, il est donc nécessaire de remplacer PEXT par une série de AND/OR/SHR qui potentiellement ralentissent le traitement. Nous verrons si cela est confirmé.
1.2. Rappels sur le tri fusion (Merge Sort)
L'algorithme du tri-fusion est composé de deux phases :
- une phase de séparation (split) qui consiste à diviser le tableau à trier de $N$ éléments en deux sous tableaux de $N/2$ éléments de manière récursive
- une phase de fusion (merge) qui intervient quand on a atteint une taille de 1 (ou 2 éléments suivant les implantations) et qui consiste à réordonner les valeurs de deux sous tableaux triés pour n'en faire qu'un seul.
Voir le principe sur Wikipedia
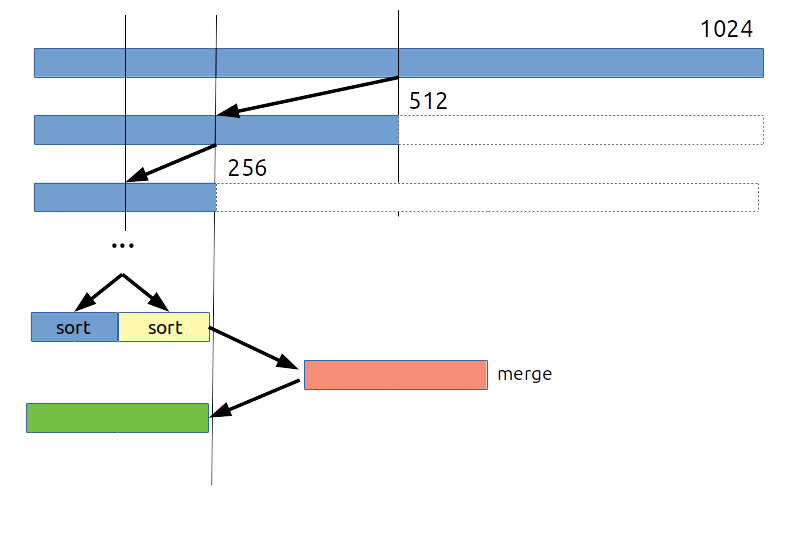
Le principal avantage du tri fusion est qu'il possède une complexité en $N × log(N)$ mais l'étape de fusion nécessite la création d'un tableau temporaire comme le montre le code suivant :
- CODE
- merge_sort.cpp
- #include <iostream>
- #include <algorithm>
- #include <stdlib.h>
- #include <string.h>
- using namespace std;
- /**
- * improved version of merge
- * t is an array of size n that was divided
- * at index m
- * @param t array to merge which is composed of two sub arrays
- * from [0,m[ and [m,n[
- * @param n size of the array
- * @param m index of the element in the middle
- */
- void merge(int *t, int n, int m) {
- int i, j, k;
- int *x = new int[n];
- for (i = 0, j = m, k = 0; k < n; ++k) {
- x[k] = (j == n) ? t[i++]
- : (i == n) ? t[j++]
- : t[j] < t[i] ? t[j++]
- : t[i++];
- }
- delete [] x;
- }
- /**
- * Recursively split initial array t of size sz into two smaller arrays
- * until array size is less or equal than two
- * @param t array to sort
- * @param sz size of array
- */
- void split(int *t, int sz) {
- if (sz <= 1) {
- return ;
- }
- // divide array t in its middle
- int m = (sz / 2);
- // split into two sub arrays
- split(t, m);
- split(t + m, sz - m);
- // merge sub arrays
- merge(t, sz, m);
- }
- /**
- * check if array is sorted, return true if it is the case
- */
- bool is_sorted(int *t, int sz) {
- for (int i = 1; i < sz; ++i) {
- if (t[i-1] > t[i]) return false;
- }
- return true;
- }
- /**
- * main function
- */
- int main(int argc, char *argv[]) {
- int *tab;
- int size = 1024;
- // get size of array from command line argument if provided
- if (argc > 1) {
- }
- cout << "size=" << size << endl;
- // create array and fill with values in descending order
- tab = new int [ size ];
- for (int i=0;i<size; ++i) tab[i] = size-i;
- // print first elements before sort
- cout << "tab.before=[";
- for (int i=0; i<10; ++i) cout << tab[i] << " ";
- cout << "]\n";
- // sort in ascending order
- split(tab, size);
- // check if array is really sorted
- if (!is_sorted(tab, size)) {
- cout << "!!! NOT SORTED !!!" << endl;
- }
- // print first elements after sort
- cout << "tab.after=[";
- for (int i=0; i<10; ++i) cout << tab[i] << " ";
- cout << "]\n";
- return 0;
- }
Voici un ordre de grandeur sous Ryzen 1700X des temps d'éxécution de l'implantation pour différentes tailles de tableaux :
| Taille | Temps (s) |
| 2_097_152 (2^21) | 0.07 |
| 4_194_304 (2^22) | 0.16 |
| 8_388_608 (2^23) | 0.29 |
| 16_777_216 (2^24) | 0.64 |
| 33_554_432 (2^25) | 1.32 |
| 67_108_864 (2^26) | 2.61 |
| 134_217_728 (2^27) | 5.45 |
1.3. Tri Fusion modifié
1.3.1. Modification de l'algorithme
La modification de l'algorithme consiste
- à arrêter l'étape de split quand la taille du tableau est égale à 4. Le tri ne fonctionnera alors correctement que si la taille du tableau est multiple de 4.
/** * Recursively split initial array t of size sz into two smaller arrays * until array size is equal to 4 */ void split_vec(int *t, int sz) { if (sz == 4) { asm_sse_sort(t); return ; } // divide array t in its middle int m = (sz / 2); // split into two sub arrays split_vec(t, m); split_vec(t + m, sz - m); // merge sub arrays merge(t, sz, m); } - à trier quatre entiers adjacents dans un vecteur SSE grâce à la fonction asm_sse_sort
Il faut donc trouver un moyen pour savoir comment les ordonner.
1.3.2. Comment ordonner les valeurs
Pour ordonner les valeurs on dispose de l'instruction PSHUFD mais celle-ci n'admet qu'un argument de type constante qui indique comment sélectionner les valeurs.
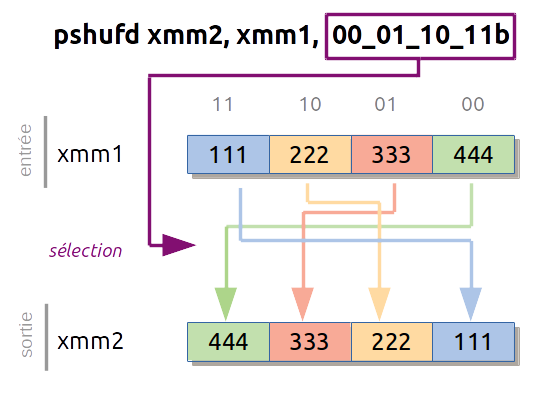
Comme indiqué préalablement on modifiera la constante de l'instruction à la volée.
0x66, 0x0f, 0x70, 0xc0, 0xe0 ; pshufd xmm0,xmm0,0xe0
Pour trouver un identifiant unique lié à la réorganisation des valeurs, on va comparer 4 entiers adjacents à des réordonnancements de ces 4 valeurs comme sur l'exemple suivant, on compare le vecteur V1 à V2 et V3
- V1 est le vecteur initial (ici, il est déjà trié)
- V2 est un décalage à droite de V1 de 32 bits
- V3 est un décalage à droite de V2 de 32 bits
| V1 (xmm0) = | 1 | 2 | 3 | 4 |
| V2 (xmm1) = | 4 | 1 | 2 | 3 |
| V3 (xmm2) = | 3 | 4 | 1 | 2 |
Pour réaliser la comparaison, on s'appuiera sur l'instruction PCMPGTD (Compare Packed Signed Integers for Greater Than) qui permet de comparer deux registres SSE.
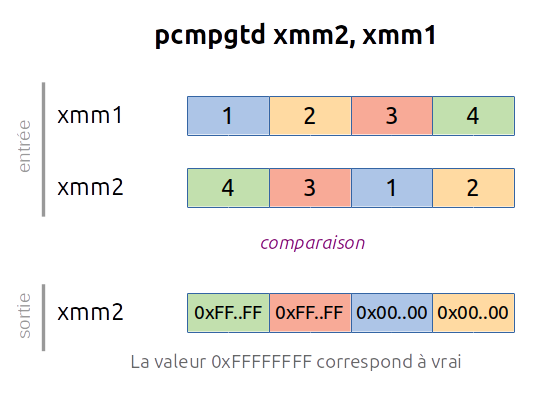
Dans l'exemple précédent, si on compare V1 à V2, puis V1 à V3, on obtient les résultats suivants mais on voudrait obtenir des valeurs comme dans la colonne de droite :
| Cmp(V2,V1) | 0xFFFFFFFF | 0x00000000 | 0x00000000 | 0x00000000 | = 1000_b = 8 |
| Cmp(V3,V1) | 0xFFFFFFFF | 0xFFFFFFFF | 0x00000000 | 0x00000000 | = 1100_b = 12 |
Puis en fonction des deux valeurs obtenues sur 4 bits, on génère une valeur sur 8 bits :
| C = 16 * Cmp(V2,V1) + Cmp(V3,V1) = 16 * 8 + 12 = 140 |
Ce qui permet pour chaque cas ( [1,2,3,4], [1,4,3,2], [1,2,2,3], ...) d'obtenir une valeur unique et de calculer la constante à utiliser pour PSHUFD.
Le problème est que pour récupérer le résultat de la comparaison on est contraint de passer par l'instruction PMOVMSKB (Move Byte Mask) :
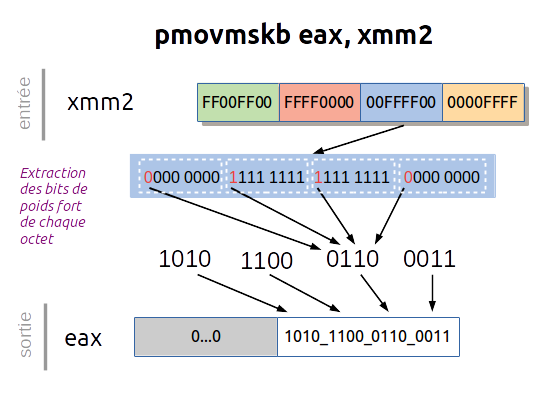
PMOVMSKB appliqué aux comparaisons de V2 avec V1 et V3 avec V1 donne les résultats suivants et on désire récupérer les bits en rouge :
| PMOVMSKB de Cmp(V2,V1) | 0xF000 | 1111_0000_0000_0000_b |
| PMOVMSKB de Cmp(V3,V1) | 0xFF00 | 1111_1111_0000_0000_b |
Pour cela on dispose de l'instruction PEXT (Parallel Bits Extract) qui utilise le masque du troisième opérande afin de sélectionner les bits du second opérande et mettre le résultat dans le premier opérande :
PEXT r32a, r32b, r/m32Dans notre cas, il suffira d'appliquer le masque 0x1111 sur le résultat de PMOVMSKB.
1.3.3. Modification du code à la volée
La modification de l'instruction à la volée est un véritable challenge pour le processeur puisque l'instruction est probablement en train d'être décodée, voire traitée. et il faut la recharger.
1.3.4. Le code principal
On charge le vecteur [4, 3, 2, 1], dans la suite les valeurs contenues dans les registres SSE sont affichées dans l'ordre inverse afin d'afficher la partie haute du registre SSE à gauche et la partie basse à droite :
| Instruction | Valeur / Vecteur |
| movdqu xmm0, [ecx] | [00 00 00 01_00 00 00 02_00 00 00 03_ 00 00 00 04] |
| pshufd xmm1, xmm0, 00111001b ; 0x39 | [00 00 00 04_00 00 00 01_00 00 00 02_00 00 00 03] |
| pshufd xmm2, xmm0, 01001110b ; 0x4E | [00 00 00 03_00 00 00 04_00 00 00 01_00 00 00 02] |
| push ebx | |
| mov edx, 0x1111 | edx=00.00.11.11_h |
| pcmpgtd xmm1, xmm0 | [FF FF FF FF_00 00 00 00_00 00 00 00_00 00 00 00] |
| pmovmskb eax, xmm1 | eax = F000 |
| pext ebx, eax, edx | ebx= 1000_b = 8 |
| shl ebx, 4 | ebx * 16 = 128 |
| pcmpgtd xmm2, xmm0 | [FF FF FF FF_FF FF FF FF_00 00 00 00_00 00 00 00] |
| pmovmskb eax, xmm2 | eax = FF00 |
| pext eax, eax, edx | eax = 1100_b = 12 |
| add eax, ebx | eax = 140 |
| mov edx, pshufd_label_text | |
| movzx eax, byte [pshufd_table + eax] | eax = 1B = 27 |
Au final le réarrangement est 1B_h = 0001_1011_b
- ; ------------------------------------------------------------------
- ; Author: Jean-Michel RICHER
- ; Email: jean-michel.richer@univ-angers.fr
- ; Date: September 2018
- ; ------------------------------------------------------------------
- ;
- ; version with .text section writable
- ; so the instruction in the .text section is modified
- ;
- %include "src/asm_config.inc"
- global asm_sse_sort
- ; ==============
- ; ==== DATA ====
- ; ==============
- section .data
- ; -------------------------------------
- ; table of values for PSHUFD
- align 16
- pshufd_table: db 228,0,0,0,0,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 228,0,0,0,0,0,0,0,
- db 108,0,0,0,0,0,0,0,
- db 0,225,177,0,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 180,0,180,0,0,0,0,0,
- db 156,0,0,0,0,0,0,0,
- db 0,0,0,210,0,198,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,216,0,0,210,0,0,
- db 120,0,0,114,0,0,0,0,
- db 0,225,225,0,0,201,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,228,0,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,0,0,0,0,0,147,
- db 0,0,0,27,0,0,0,0,
- db 0,0,0,0,0,0,0,99,
- db 99,0,0,75,0,0,0,0,
- db 0,0,141,0,0,45,0,0,
- db 135,0,0,39,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 147,0,0,0,0,0,0,0,
- db 0,0,0,54,0,54,0,0,
- db 0,0,0,30,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,0,78,0,0,0,0,
- db 0,0,0,0,0,57,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,0,0,0,0,0,0,
- db 0,0,0,0,0,0,0
- ; ==============
- ; ==== TEXT ====
- ; ==============
- section .text
- ; ------------------------------------------
- ; !!!!!!!!!!!!!!!!!! Note !!!!!!!!!!!!!!!!!!
- ; this is a fast call subprogram so first
- ; parameter t is placed in ECX in 32 bits
- ; for GCC/G++
- ;
- ; void asm_sse_sort(int *t)
- ;
- ; ------------------------------------------
- asm_sse_sort:
- movdqu xmm0, [ecx]
- ; xmm1 is a rotation of xmm0
- pshufd xmm1, xmm0, 00111001b ; 0x39
- ; xmm2 is a rotation of xmm0
- pshufd xmm2, xmm0, 01001110b ; 0x4E
- ; save ebx cause it will be modified
- push ebx
- ; mask for PEXT instruction
- mov edx, 0x1111
- ; compare xmm1 to xmm0 and get result in xmm1
- pcmpgtd xmm1, xmm0
- ; get result of comparison
- pmovmskb eax, xmm1
- pext ebx, eax, edx
- shl ebx, 4
- ; compare xmm2 to xmm0 and get result in xmm2
- pcmpgtd xmm2, xmm0
- pmovmskb eax, xmm2
- pext eax, eax, edx
- ; compute identifier
- add eax, ebx
- ; modify PSHUFD constant
- mov edx, pshufd_label_text
- movzx eax, byte [pshufd_table + eax] ;
- mov [edx+4], al
- ; restore EBX
- pop ebx
- pshufd_label_text:
- pshufd xmm0,xmm0,0xe0 ; <---- modify here
- movdqu [ecx],xmm0
- ret
1.3.5. Permettre la modification de la section .text
- #include <errno.h>
- #include <unistd.h>
- #include <sys/mman.h>
- int change_page_permissions_of_address(void *addr) {
- int page_size = getpagesize();
- addr -= (unsigned long)addr % page_size;
- int protection = PROT_READ | PROT_WRITE | PROT_EXEC;
- if(mprotect(addr, page_size, protection) == -1) {
- return -1;
- }
- return 0;
- }
- extern "C" {
- // note that for fast call parameter t is in ECX
- void asm_sse_sort(int *t) __attribute__((fastcall));
- }
- int main(int argc, char *argv[]) {
- void *proc_addr = (void*)asm_sse_sort;
- if(change_page_permissions_of_address(proc_addr) == -1) {
- cerr << "Error while changing page permissions" << endl;
- return 1;
- }
- ....
- }
1.3.6. remplacer PEXT par AND/SHR/OR
Comme indiqué dans l'introduction, certains processeurs ne disposent pas de l'instruction PEXT qui est relativement récente et date de 2013. On va donc la remplacer par une série de décalages et sélection de bits.
Ici eax est l'entrée et contient une valeur du type 000X.0000Y.000Z.000T_b et on veut obtenir XYZT_b. Le registre edx contient le masque de sélection 0001.0001.0001.0001_b = 1111_h :
; par exemple
; eax = 1111.1110.1110.1111_b
; edx = 0001.0001.0001.0001_b
and eax, edx ; eax = 0001.0000.0000.0001_b application du masque
mov ebx, eax ; ebx = 0001.0000.0000.0001_b sauvegarde dans ebx de eax
shr eax, 3 ; eax = 00010.0000.0000_b décalage vers la droite
or ebx, eax ; ebx = 0001.0010.0000.0001_b
shr eax, 3 ; eax = 00.0100.0000_b
or ebx, eax ; ebx = 0001.0010.0100.0001_b
shr eax, 3 ; eax = 0000.1000_b
or ebx, eax ; ebx = 0001.0010.0100.1001_b
and ebx, 1111b ; ebx = 0000.0000.0000.1001_b
On peut écrire la même chose en C :
z = ((z & 0x1000) >> 9) + ((z & 0x0100) >> 6) + ((z & 0x0010) >> 3) + (z & 1);
Par exemple GCC traduira le code précédent sous la forme suivante :
mov ecx, DWORD [esp+4] ; ecx = z
mov eax, ecx ; eax = z
mov edx, ecx ; edx = z
shr eax, 9 ; récupère les deux bits de poids fort
shr edx, 6
and eax, 8
and edx, 4
or edx, eax
mov eax, ecx ; récupère les deux bits de poids faible
and ecx, 1
shr eax, 3
and eax, 2
or ecx, eax
lea eax, [edx+ecx]
1.3.7. Switch / Case of
Enfin, on peut se demander si utiliser un switch dégraderait ou améliorerait la performance de l'algorithme. Plutôt que de modifier la constante de PSHUFD, on va se diriger vers du code spécifique :
L'idée est d'utiliser une table avec les adresses du code à exécuter:
- ; ------------------------------------------------------------------
- ; Author: Jean-Michel RICHER
- ; Email: jean-michel.richer@univ-angers.fr
- ; Date: September 2018
- ; ------------------------------------------------------------------
- ;
- ; version with .text section writable
- ; so the instruction in the .text section is modified
- ;
- %include "src/asm_config.inc"
- global asm_sse_sort
- section .data
- align(16)
- section .text
- ; ------------------------------------------
- ; !!!!!!!!!!!!!!!!!! Note !!!!!!!!!!!!!!!!!!
- ; this is a fast call subprogram so first
- ; parameter t is placed in ECX in 32 bits
- ; for GCC/G++
- ;
- ; void asm_sse_sort(int *t)
- ;
- ;%define BMI2
- ; PEXT result, input, mask
- %ifdef BMI2
- %macro BMI2_PEXT 3
- pext %1, %2, %3
- %endmacro
- %else
- %macro BMI2_PEXT 3
- and %2, %3
- mov %1, %2
- shr %2, 3
- or %1, %2
- shr %2, 3
- or %1, %2
- shr %2, 3
- or %1, %2
- and %1, 1111b
- %endmacro
- %endif
- asm_sse_sort:
- ; xmm0 = [1, 2, 3, 4]
- movdqu xmm0, [ecx]
- ; xmm1 = [4, 1, 2, 3]
- pshufd xmm1, xmm0, 00111001b ; 0x39
- ; xmm2 = [3, 4, 1, 2]
- pshufd xmm2, xmm0, 01001110b ; 0x4E
- push ebx ; save EBX
- mov edx, 0x1111 ; mask for pext
- pcmpgtd xmm1, xmm0
- pmovmskb eax, xmm1
- BMI2_PEXT ebx, eax, edx
- ; and eax, edx
- ; mov ebx, eax
- ; shr eax, 3
- ; or ebx, eax
- ; shr eax, 3
- ; or ebx, eax
- ; shr eax, 3
- ; or ebx, eax
- ; and ebx, 1111b
- shl ebx, 4
- pcmpgtd xmm2, xmm0
- pmovmskb eax, xmm2
- %ifdef BMI2
- BMI2_PEXT eax, eax, edx
- %else
- push ebx
- mov ebx, eax
- BMI2_PEXT eax, ebx, edx
- pop ebx
- %endif
- add eax, ebx
- pop ebx ; restore EBX
- mov eax, dword [cases_table + eax * 4]
- jmp eax
- LP0:
- pshufd xmm0,xmm0,0
- movdqu [ecx],xmm0
- ret
- LP228:
- pshufd xmm0,xmm0,228
- movdqu [ecx],xmm0
- ret
- LP108:
- pshufd xmm0,xmm0,108
- movdqu [ecx],xmm0
- ret
- LP225:
- pshufd xmm0,xmm0,225
- movdqu [ecx],xmm0
- ret
- LP177:
- pshufd xmm0,xmm0,177
- movdqu [ecx],xmm0
- ret
- LP180:
- pshufd xmm0,xmm0,180
- movdqu [ecx],xmm0
- ret
- LP156:
- pshufd xmm0,xmm0,156
- movdqu [ecx],xmm0
- ret
- LP210:
- pshufd xmm0,xmm0,210
- movdqu [ecx],xmm0
- ret
- LP198:
- pshufd xmm0,xmm0,198
- movdqu [ecx],xmm0
- ret
- LP216:
- pshufd xmm0,xmm0,216
- movdqu [ecx],xmm0
- ret
- LP120:
- pshufd xmm0,xmm0,120
- movdqu [ecx],xmm0
- ret
- LP114:
- pshufd xmm0,xmm0,114
- movdqu [ecx],xmm0
- ret
- LP201:
- pshufd xmm0,xmm0,201
- movdqu [ecx],xmm0
- ret
- LP147:
- pshufd xmm0,xmm0,147
- movdqu [ecx],xmm0
- ret
- LP27:
- pshufd xmm0,xmm0,27
- movdqu [ecx],xmm0
- ret
- LP99:
- pshufd xmm0,xmm0,99
- movdqu [ecx],xmm0
- ret
- LP75:
- pshufd xmm0,xmm0,75
- movdqu [ecx],xmm0
- ret
- LP141:
- pshufd xmm0,xmm0,141
- movdqu [ecx],xmm0
- ret
- LP45:
- pshufd xmm0,xmm0,45
- movdqu [ecx],xmm0
- ret
- LP135:
- pshufd xmm0,xmm0,135
- movdqu [ecx],xmm0
- ret
- LP39:
- pshufd xmm0,xmm0,39
- movdqu [ecx],xmm0
- ret
- LP54:
- pshufd xmm0,xmm0,54
- movdqu [ecx],xmm0
- ret
- LP30:
- pshufd xmm0,xmm0,30
- movdqu [ecx],xmm0
- ret
- LP78:
- pshufd xmm0,xmm0,78
- movdqu [ecx],xmm0
- ret
- LP57:
- pshufd xmm0,xmm0,57
- movdqu [ecx],xmm0
- ret
- cases_table:
- dd LP228, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;9
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP228, LP0, LP0, ;19
- dd LP0, LP0, LP0, LP0, LP0, LP108, LP0, LP0, LP0, LP0, ;29
- dd LP0, LP0, LP0, LP0, LP225, LP177, LP0, LP0, LP0, LP0, ;39
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP180, ;49
- dd LP0, LP180, LP0, LP0, LP0, LP0, LP0, LP156, LP0, LP0, ;59
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP210, LP0, ;69
- dd LP198, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;79
- dd LP0, LP0, LP0, LP216, LP0, LP0, LP210, LP0, LP0, LP120, ;89
- dd LP0, LP0, LP114, LP0, LP0, LP0, LP0, LP0, LP225, LP225, ;99
- dd LP0, LP0, LP201, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;109
- dd LP0, LP0, LP0, LP0, LP0, LP228, LP0, LP0, LP0, LP0, ;119
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;129
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP147, LP0, LP0, LP0, ;139
- dd LP27, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;149
- dd LP0, LP0, LP99, LP99, LP0, LP0, LP75, LP0, LP0, LP0, ;159
- dd LP0, LP0, LP0, LP141, LP0, LP0, LP45, LP0, LP0, LP135, ;169
- dd LP0, LP0, LP39, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;179
- dd LP0, LP0, LP0, LP0, LP0, LP147, LP0, LP0, LP0, LP0, ;189
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP54, LP0, LP54, LP0, ;199
- dd LP0, LP0, LP0, LP0, LP30, LP0, LP0, LP0, LP0, LP0, ;209
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;219
- dd LP78, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;229
- dd LP57, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;239
- dd LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, LP0, ;249
- dd LP0, LP0, LP0, LP0, LP0, LP0,
1.4. Résultats
Voici un tableau comparatif concernant quelques architectures :
| Processeur | BMI2 | std::vector | .data + SSE | .text + SSE | case + SSE |
| AMD Ryzen 1700X | Oui | 6.42 | 7.20 | 7.24 | 6.29 |
| Intel i5-7400 | Oui | 7.32 | 11.42 | 12.28 | 7.32 |
| Intel i3-6100 | Oui | 6.29 | 9.68 | 10.42 | 6.23 |
| Intel i7-4790 | Non | 5.23 | 8.10 | 8.67 | 4.95 |
| Intel i5-3570K | Non | 8.96 | 11.70 | 12.27 | 8.71 |
| Intel i7 860 | Non | 14.33 | 17.35 | 17.99 | 14.53 |
| Intel N3060 | Non | 18.25 | 23.84 | 23.99 | 17.85 |
Quelles remarques peut on faire ?
- L'implantation avec vecteur et switch est la plus efficace
- les deux autres implantations avec vecteur sont moins efficaces, cela peut être dû notamment à la modification de l'instruction PSHUFD
- modifier l'instruction PSHUFD dans la section .text semble un peu plus pénalisant que dans la section .data
- l'absence ou la présence de l'instruction PEXT ne semble pas pénaliser le code