9. TP - Méthodes de tri
9.1. Introduction
Dans ce TP, on s'intéresse à l'étude des méthodes de tri de tableaux d'entiers, notamment :
- le tris à bulles
- le tri par insertion
- le tri rapide
Les méthodes de tri à bulles et par insertion sont des méthodes de complexité en $O(n^2)$, plus précisément $(n^2)/2$ si $n$ est le nombre d'éléments à trier.
Par contre le tri rapide est une méthode de complexité en $O(n × log(n))$, ce qui la rend beaucoup plus rapide.
| Complexité | 10 | 100 | 1000 | 10000 |
|---|---|---|---|---|
| $n² ÷ 2$ | 50 | 5000 | 500000 | 50000000 |
| $n × log(n)$ | 23 | 461 | 6908 | 92103 |
Si on implante ces méthodes en C/C++ on s'aperçoit que la méthode de tri par insertion, bien que de complexité plus grande que celle du tri rapide, est plus efficace que le tri rapide pour des tailles de tableau $n ≤ 15$.
9.1.1. Rappels
Pour rappel en Python, pour trier une liste d'entiers ou de chaînes de caractères on peut utiliser :
- liste.sort()
- liste_triee = sorted(liste)
La méthode sort associée au type
Ces deux approches sont très rapides, cependant sorted est un peu plus lente car il faut créer une liste triée.
9.2. Implantation des méthodes de tri
Nous allons créer plusieurs fichiers :
tris.py le programme principal qui calculera le temps d'exécution des différentes méthodes de tris implantées pour différentes tailles de tableauxtri_a_bulles.py un fichier comprenant la méthode du tri à bullestri_par_insertion.py un fichier comprenant la méthode du tri par insertiontri_rapide.py un fichier comprenant la méthode du tri rapide
9.2.1. Programme principal
Exercice 9.1
Créez le fichier
raise Exception("tableau non trié")Une exception est une erreur qui peut être interceptée et traitée. Ici, comme l'exception ne sera pas traitée, elle termine le programme et le message d'erreur sera affiché.
9.2.2. Tri à bulles
Le tri à bulles est un tri assez simple : il consiste à faire remonter les éléments les plus grands vers les indices les plus hauts du tableau par échange de deux éléments consécutifs.
| Procédure tri_à_bulles() | |
|---|---|
| Entrée |
t tableau d'entiers |
| Sortie | aucune, le tableau est trié en ordre croissant |
| Variables globales |
aucune |
| Variables locales |
i, j : variables de boucle |
| Description |
Etant donné un tableau de n éléments, faire remonter au fur et à mesure
les éléments les plus grands vers les indices les plus hauts du tableau. Le tableau possède $n$ éléments situés aux indices $0$ à $n-1$. |
|
|
Exercice 9.2
Créez un fichier
9.2.3. Tri par insertion
Le tri par insertion est un tri qui consiste à parcourir le tableau $t$ et à le trier au fur et à mesure pour que les éléments soient dans l'ordre croissant. Le tri par insertion se fait sur place. Ainsi, à l'étape $k$, les $k–1$ premiers éléments du tableau sont triés et on insère le $k$-ième élément à sa place parmi les $k$ premiers éléments.
| Procédure tri_par_insertion() | |
|---|---|
| Entrée |
t tableau d'entiers |
| Sortie | aucune, le tableau est trié en ordre croissant |
| Variables globales |
aucune |
| Variables locales |
|
| Description | cf. description ci-dessus. |
|
|
Exercice 9.3
Créez un fichier
9.2.4. Tri rapide (Quicksort)
Le tri rapide est un algorithme de tri inventé par C.A.R. Hoare en 1961 et fondé sur la méthode de conception diviser pour régner. La méthode consiste à placer un élément du tableau (appelé pivot) à sa place définitive, en permutant tous les éléments de telle sorte que tous ceux qui sont inférieurs au pivot soient à sa gauche et que tous ceux qui sont supérieurs au pivot soient à sa droite.
On va donner ici une méthode très simple basée sur ce principe mais qui n'est pas la plus optimale. Elle consiste à créer des sous-tableaux et à retourner le tableau réordonné.
| fonction tri_rapide() | |
|---|---|
| Entrée |
t tableau d'entiers |
| Sortie | tableau d'entiers |
| Variables globales |
aucune |
| Variables locales |
|
| Description | cf. description ci-dessus. |
|
|
Exercice 9.4
Créez un fichier
9.2.5. Test des fonctions de tri
Exercice 9.5
Dans le programme principal
9.3. Comparaison des méthodes de tri
On va maintenant tester le temps d'exécution de chacune des méthodes de tri pour des tableaux de tailles différentes.
On prendra les tailles suivantes $[100, 1000, 10000, 20000]$ et on générera des tableaux avec des valeurs aléatoires.
Exercice 9.6
Dans le programme principal
import time
# ...
debut = time.time()
# ... code à chronométrer
fin = time.time()
temps_d_execution = fin - debut
Les temps obtenus sont en secondes.
Le sous-programme
Exercice 9.7
Dans le programme principal
Le sous-programme
Exercice 9.8
Dans le programme principal
Le sous-programme
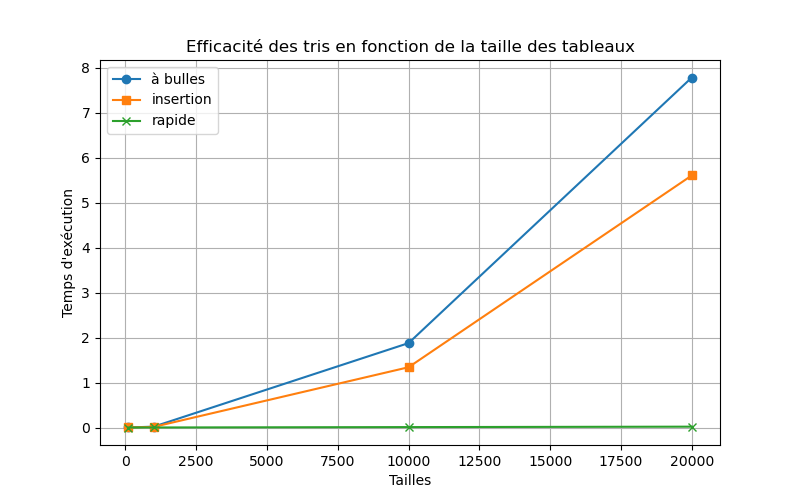
9.3.1. Comparaison visuelle
Utilisez
- CODE
- graphique.py
- import matplotlib.pyplot as plt
- tailles = [100, 1000, 10000, 20000]
- # taille de la figure
- plt.figure(figsize=(8, 5))
- plt.plot(tailles, t1, label='à bulles', marker='o')
- plt.plot(tailles, t2, label='insertion', marker='s')
- plt.plot(tailles, t3, label='rapide', marker='x')
- # Label the axes
- plt.xlabel('Tailles')
- plt.ylabel('Temps d\'exécution (s)')
- plt.title('Efficacité des tris en fonction de la taille des tableaux')
- plt.legend()
- plt.grid(True)
- plt.show()
Vous devriez obtenir un graphique similaire à celui-ci :