5. Algorithmique 4 - Tris
5.1. Rappels
Voici un tableau récapitulatif des complexités des méthodes de tri :
| Méthode de tri | Complexité temporelle (pire des cas) |
Complexité temporelle (en moyenne) |
Complexité temporelle (meilleur des cas) |
| Tri à bulles | $O(n^2)$ | $O(n^2)$ | $O(n)$ |
| Tri par sélection | $O(n^2)$ | $O(n^2)$ | $O(n^2)$ |
| Tri par insertion | $O(n^2)$ | $O(n^2)$ | $O(n)$ |
| Tri rapide (Quicksort) | $O(n^2)$ | $O(n×log(n))$ | $O(n×log(n))$ |
| Tri fusion (Mergesort) | $O(n×log(n))$ | $O(n×log(n))$ | $O(n×log(n))$ |
| Tri par tas (Heapsort) | $O(n×log(n))$ | $O(n×log(n))$ | $O(n×log(n))$ |
On distingue donc les méthodes en
- $O(n^2)$ qui sont les moins efficaces en général, sauf si le tableau est déjà trié ou si $n$ est petit ($n < 15)$
- $O(n × log(n))$ qui sont les plus efficaces
Nous allons étudier quatre méthodes de tris :
- le tri par insertion (Insertion Sort)
- le tri fusion (Merge Sort)
- le tri rapide (Quick Sort)
- le tri rapide aidé du tri par insertion
5.2. Le tri par insertion
On l'appelle également tri du joueur de cartes. Il consiste à chaque étape à replacer l'élément t[i] dans le tableau trié t[1:i-1].
| i | j | 1 | 2 | 3 | 4 | 5 |
| ? | ? | 25 | 24 | 23 | 22 | 21 |
| 2 | 2 | 24 | 25 | 23 | 22 | 21 |
| 3 | 3 | 24 | 23 | 25 | 22 | 21 |
| 3 | 2 | 23 | 24 | 25 | 22 | 21 |
| 4 | 4 | 23 | 24 | 22 | 25 | 21 |
| 4 | 3 | 23 | 22 | 24 | 25 | 21 |
| 4 | 2 | 22 | 23 | 24 | 25 | 21 |
| 5 | 5 | 22 | 23 | 24 | 21 | 25 |
| ... | ... | ... | ... | ... | ... | ... |
- CODE
- tri_insertion.ezl
- proc insertion_sort( t is array[1..n] of int ) {
- for i in 2..n do
- var j = i
- while ((j > 0) and (t[ j ] < t[ j - 1 ])) do
- swap( t[ j - 1 ], t[ j ] )
- j = j - 1
- end while
- end for
- end proc
L'intérêt du tri par insertion et qu'il est généralement rapide sur des tableaux de petite taille, c'est à dire d'une vingtaine d'éléments.
Si le tableau est déjà trié, la complexité sera de $O(n)$.
Dans le cas général, la complexité est en $O(n^2)$.
Exercice 5.1
Essayez d'exécuter le tri par insertion sur le tableau suivant : [1, 7, 4, 3, 6, 8, 2].
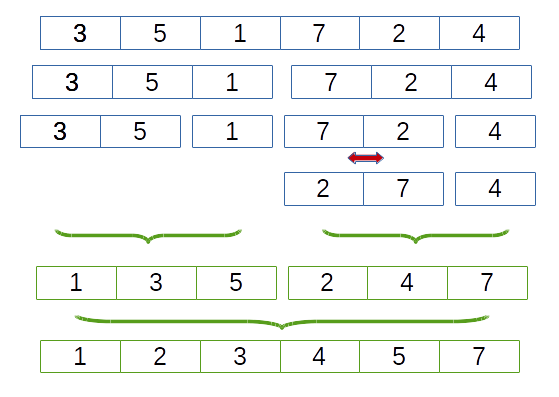
5.3. Le tri fusion
Le tri fusion consiste :
- dans une première phase récursive : à décomposer le tableau (split) en tableaux plus petits, on divise le tableau en 2 à chaque étape ce qui conduit à une décomposition arborescente en $log_2(n)$. L'important est qu'on ne crée pas de nouveaux tableaux mais on utilise les indices minimum et maximum du sous-tableau courant.
- lorsque le tableau a une taille :
- d'un élément on ne fait rien
- de deux éléments on échange les deux éléments du tableau si celui d'indice $i$ est plus grand que celui d'indice $i+1$
- dans une deuxième phase : à fusioner (merge) deux tableaux triés adjacents
- CODE
- tri_fusion.ezl
- // ------------------------------------------------------------------
- //
- // What:
- //
- // Main function that performs merge_sort
- //
- // Parameters:
- //
- // t an array of integers
- //
- // ------------------------------------------------------------------
- proc merge_sort( t is array[1..n] of int )
- // start recursive split
- split(t, 1, n)
- end proc
- // ==================================================================
- //
- // What:
- //
- // Recursively split the initial array in two subarrays
- //
- // Parameters:
- //
- // a is the minimum index of array t
- // b is the maximum index of array t
- //
- // ==================================================================
- proc split( t is array[1..n] of int; a, b are int )
- var size = b - a + 1
- if size = 1 then
- exit proc
- if size = 2 then
- if t[a] > t[a+1] then
- swap( t[a], t[a+1] )
- end if
- else
- // m is the middle index
- var m = (a + b + 1) / 2
- split( t, a, m-1 )
- split( t, m, b )
- merge( t, a, m, b )
- end if
- end proc
- // ==================================================================
- //
- // What:
- //
- // Merge two subarrays into a one array and copy result to
- // the initial array
- //
- // Parameters:
- //
- // t an array of integers
- // a is the minimum index of array t
- // m is the middle index of array t
- // b is the maximum index of array t
- //
- // ==================================================================
- proc merge( t is array[1..n] of int; a, m, b are int ) {
- // array which is the result of the merge of arrays
- // from [a..m] and [m+1..b]
- var tmp is array[1..b-a+1] of int
- var i = a
- var j = m
- // copy back data following order into tmp
- while (i < m) and(j < b+1) do
- if t[i] < t[j] then
- tmp[k] = t[i]
- i = i + 1
- k = k + 1
- else if t[j] < t[i] then
- tmp[k] = t[j]
- j = j + 1
- k = k + 1
- else
- tmp[k] = t[i]
- i = i + 1
- k = k + 1
- tmp[k] = t[j]
- j = j + 1
- k = k + 1
- end if
- end while
- while i < m do
- tmp[k] = t[i]
- i = i + 1
- k = k + 1
- end while
- while j < b+1 do
- tmp[k] = t[i2]
- j = j + 1
- k = k + 1
- end while
- // copy tmp to t[a]
- t[a..b] = tmp[1..t.size()]
- end proc
Exercice 5.2
Essayez d'exécuter le tri fusion sur le tableau suivant : [1, 7, 4, 3, 6, 8, 2].
5.4. Le tri rapide
Il s'agit d'une méthode de type divide and conquer (diviser pour régner). En informatique, diviser pour régner est une méthode de conception d'algorithmes réduisant récursivement un problème en un ou plusieurs sous-problèmes du même type qui sont indépendants.
Le principe du tri rapide consiste à réaliser une partition des éléments du sous-tableau [p..r] par rapport à une valeur pivot notée $x$ que l'on placera à un indice $q$ du tableau de telle sorte que :
- $∀ i ∈ [1..q-1]$ on a $t[i] < x $
- $∀ i ∈ [q+1..n]$, $t[i] > x $
On espère ainsi que statistiquement $q$ sera proche de $(p+r)/2$, donc placé au milieu du tableau.
On trie ensuite récursivement le sous-tableau gauche et le sous-tableau droit (cf. animation).
Pour que le tri soit le plus rapide possible il faudrait choisir à chaque fois une valeur pivot qui scinde le tableau initial en deux parties égales, ce qui n'est pas possible à moins d'examiner les valeurs à trier mais cela reviendrait à perdre du temps.
L'algorithme est le suivant :
- CODE
- tri_rapide.ezl
- proc _quick_sort( t is array[1..n] of int; a, b are int)
- if a < b then
- // pivot in the middle of the array
- var m = (b + a + 1) / 2
- var x = t[ m ]
- swap( t[ m ], t[ b ] )
- var q = a
- for i in a..b-1 do
- if t[ i ] < x then
- swap( t[ i ], t [q++ ])
- end if
- end for
- swap( t[ b ], t[ q ] )
- if (a < q) _quick_sort( t, a, q - 1 )
- if (q < b) _quick_sort( t, q + 1, b )
- end if
- end proc
- proc quick_sort( t is array[1..n] of int )
- _quick_sort( t, 1, n )
- end proc
Exercice 5.3
Essayez d'exécuter le tri rapide sur le tableau suivant : [1, 7, 4, 3, 6, 8, 2].
5.5. Le tri rapide aidé du tri par insertion
On reprend le même algorithme que pour le tri rapide, cependant lorsque le tableau à trier possède une taille inférieure ou égale à 15 éléments (voire jusqu'à 20 ou 24), on utilise le tri par insertion car on sait que celui-ci sera généralement plus rapide comme le montre le graphique suivant :
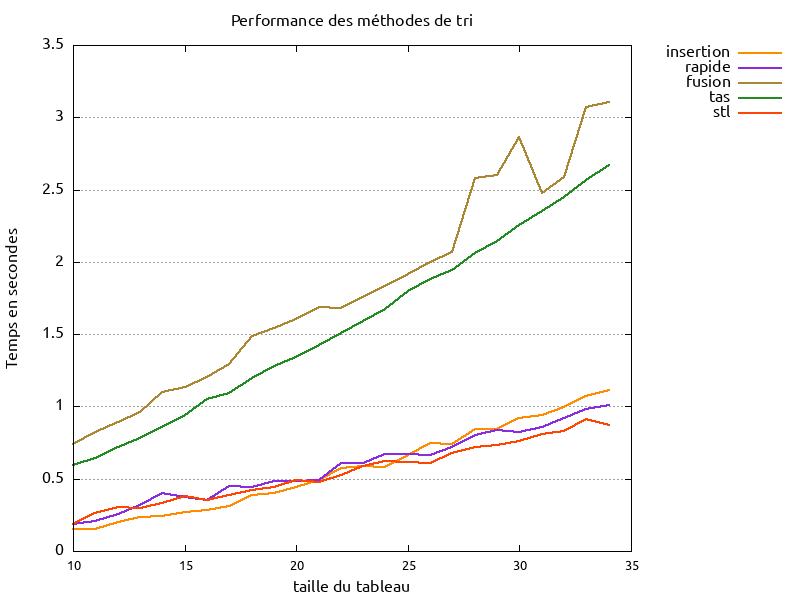
Temps sur AMD Ryzen 5 5600G pour 10 millions de tris du même tableau
Un rapide test, pour des tailles de tableaux de 15 ou 25 éléments, montre que le tri par insertion :
- est plus performant sur 15 éléments que le tri rapide
- devient moins performant que le tri rapide à partir de 20 éléments
| Méthode | Taille | Comparaisons | Swaps | Total | Ratio |
| tri rapide | 15 | 182.70 | 16.60 | 199.30 | 4.91 |
| tri insertion | 15 | 119.00 | 54.30 | 173.30 | 0.77 |
| tri rapide | 18 | 226.70 | 21.40 | 248.10 | 4.77 |
| tri insertion | 18 | 170.00 | 75.20 | 245.20 | 0.76 |
| tri rapide | 20 | 252.20 | 23.40 | 275.60 | 4.6 |
| tri insertion | 20 | 209.00 | 87.40 | 296.40 | 0.74 |
| tri rapide | 25 | 330.30 | 30.20 | 360.50 | 4.48 |
| tri insertion | 25 | 324.00 | 139.70 | 463.70 | 0.74 |
Ici le ratio représente le nombre total d'opérations (comparaisons + swaps) divisé par la complexité de la méthode dans le pire des cas.
- pour le tri rapide on a en moyenne une complexité de $4.7 × n × log(n)$
- pour le tri par insertion on a en moyenne une complexité de $0.75 × n^2$
Pour le tri rapide, le facteur multiplicatif diminue progressivement à mesure que la taille du tableau augmente :
- il est de $4,91$ pour $n=15$
- de $3,44$ pour $n=10^5$
- de $3,38$ pour $n=10^6$
- de $3,3$ pour $n=10^7$
Dernier point : sur le graphique précédent le tri rapide est plus performant que le tri par insertion à partir de 25 éléments et non pas 20 comme le montre la complexité. Cela est dû à l'implantation du code. La méthode du tri rapide est récursive et les appels de fonctions ne sont pas pris en compte dans le calcul de la complexité. Ces appels récursifs influent sur le temps de calcul.
- // tri rapide avec insertion
- proc _quick_insertion_sort( t is array[1..n] of int; a, b are int)
- if (b - a) > 15 then
- if a < b then
- // pivot in the middle of the array
- var m = (b + a + 1) / 2
- var x = t[ m ]
- swap( t[ m ], t[ b ] )
- var q = a
- for i in a..b-1 do
- if t[ i ] < x then
- swap( t[ i ], t [q++ ])
- end if
- end for
- swap( t[ b ], t[ q ] )
- if (a < q) _quick_insertion_sort( t, a, q - 1 )
- if (q < b) _quick_insertion_sort( t, q + 1, b )
- else
- insertion_sort( t, a , b );
- end if
- end proc
- proc quick_insertion_sort( t is array[1..n] of int )
- _quick_insertion_sort( t, 1, n )
- end proc
5.6. Code source
Le code source pour Linux est disponible ici. Il a été compilé avec gcc 10.3 sans générer d'erreur ou de warning.
Pour compiler, exécuter : make dans le terminal.
Pour lancer le script de tests lancer : ./test_tris.sh
5.7. Résultats
Voici quelques résultats de performance. On reporte le temps d'exécution moyen pour 10 exécutions pour différentes méthodes de tri pour des tableaux remplis par des valeurs aléatoires.
| Méthode | Taille | Temps(s) |
| insertion | 15 | 0.000001 |
| fusion | 15 | 0.000003 |
| rapide | 15 | 0.000001 |
| rapide + insertion | 15 | 0.000000 |
| insertion | 100 | 0.000019 |
| fusion | 100 | 0.000009 |
| rapide | 100 | 0.000007 |
| rapide + insertion | 100 | 0.000005 |
| insertion | 1k | 0.000979 |
| fusion | 1k | 0.000089 |
| rapide | 1k | 0.000052 |
| rapide + insertion | 1k | 0.000042 |
| insertion | 10k | 0.064443 |
| fusion | 10k | 0.000814 |
| rapide | 10k | 0.000523 |
| rapide + insertion | 10k | 0.000557 |
| insertion | 100k | 6.217739 |
| fusion | 100k | 0.009813 |
| rapide | 100k | 0.007587 |
| rapide + insertion | 100k | 0.005696 |
| insertion | 1m | 573.051 |
| fusion | 1m | 0.085273 |
| rapide | 1m | 0.056630 |
| rapide + insertion | 1m | 0.054368 |
| fusion | 10m | 0.965430 |
| rapide | 10m | 0.642476 |
| rapide + insertion | 10m | 0.599273 |
| fusion | 100m | 10.831880 |
| rapide | 100m | 7.275618 |
| rapide + insertion | 100m | 6.9855 |
| fusion | 1M | 121.696 |
| rapide | 1M | 82.441 |
| rapide + insertion | 1M | 78.947 |
Dans le tableau précédent :
- 1k signifie 1000 éléments
- 1m signifie 1_000_000 éléments
- 1M signifie 1_000_000_000 éléments
On remarque donc que :
- la méthode de tri par insertion est prohibitive (temps d'exécution très élevé) : plus de 9 min à partir de 1 millions d'éléments
- les méthodes de tri fusion et tri rapide sont beaucoup plus performantes que le tri par insertion
- la méthode de tri rapide est plus performante que la méthode de tri fusion
- la méthode de tri rapide aidée du tri par insertion est la plus performante mais reste très proche du tri rapide
5.8. Autres améliorations (ChatGPT)
L'implémentation la plus efficace du tri rapide (Quicksort) repose sur plusieurs améliorations et optimisations. Certaines des améliorations notables sont :
- Choisir un pivot efficace : Choisir un bon pivot est crucial pour assurer une bonne performance du tri rapide. Une approche courante pour choisir un pivot efficace consiste à utiliser la "médiane de trois", qui sélectionne le pivot comme étant la médiane des trois éléments (premier, milieu et dernier éléments). Cette méthode réduit la probabilité de tomber sur le pire des cas.
- Insertion sort pour les petits tableaux : Lorsque la taille du sous-tableau à trier devient suffisamment petite, le tri par insertion est généralement plus rapide que le tri rapide. Par conséquent, on peut utiliser le tri par insertion pour les petits sous-tableaux, en définissant un seuil (par exemple, 10 à 20 éléments).
- Utiliser une approche "introspective" : L'introsort est une variante du tri rapide qui combine le tri rapide, le tri par insertion et le tri par tas. L'idée est de commencer par le tri rapide et de passer au tri par tas si la profondeur de récursion dépasse une certaine limite (généralement basée sur la taille du tableau). Le tri par insertion est utilisé pour les petits sous-tableaux, comme mentionné précédemment.
- Tri rapide en parallèle : Le tri rapide peut être parallélisé pour tirer parti des architectures multi-cœurs. Plusieurs implémentations parallèles existent, comme le "parallel Quicksort" qui divise les sous-tableaux en parallèle.
En résumé, l'implémentation la plus efficace du tri rapide dépend de plusieurs facteurs, tels que la méthode de sélection du pivot, l'utilisation d'autres algorithmes de tri pour des cas spécifiques et la parallélisation pour tirer parti des ressources matérielles disponibles. La méthode de Hoare ou de Lomuto pour la partition ne fait pas une différence significative en termes d'efficacité globale.