2. Algorithmique 4 - Listes
2.1. Qu'est-ce qu'une liste ?
La structure de liste est un conteneur qui stocke des objets et permet de les insérer ou de les supprimer en fonction de leur position :
- en tête, c'est à dire en début de liste
- en queue, c'est à dire en fin de liste
- ou à une position donnée par la position de l'élément dans la liste
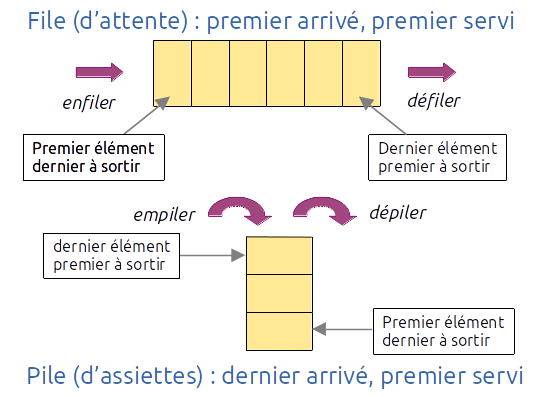
Une liste pour laquelle tout nouvel élément est ajouté en tête et tout élément est retiré en fin est appelée une file (queue en anglais), c'est une structure FIFO (First In, First Out).
Une liste pour laquelle tout nouvel élément est ajouté en queue et tout élément est retiré également en queue est appelée une pile (stack en anglais), c'est une structure LIFO (Last In, First Out).
2.2. Implantation d'une liste
On peut donner plusieurs implantation des listes :
- sous forme de tableau extensible
- sous forme de liste simplement chaînée
- sous forme de liste doublement chaînée
- sous forme de liste doublement chaînée circulaire
Une liste possède plusieurs avantages :
- on peut retirer ou supprimer des élements n'importe où dans la liste
- elle n'est pas de taille fixe
Elle possède également des inconvénients :
- pour les listes chaînées : accéder au $n$-ième élément requiert de parcourir $n$ éléments (maillons)
- pour les listes implantées par un tableau, insérer un nouvel élément requiert de déplacer d'un rang vers la droite tous les éléments qui suivent
2.3. Cas des listes simplement chaînées
On va utiliser la structure de données suivante pour implanter une liste simplement chaînée :
- #pragma once
- // ----------------------------------------------
- //
- // type de donnée stocké par la liste
- //
- // il suffira de modifier ce type si on veut
- // travailler sur une liste de personnes
- //
- // ----------------------------------------------
- // définition du type de la valeur stockée par un élément de la liste
- using type_valeur = int;
- // définition d'un élément (maillon) de la liste
- struct type_element_de_liste
- {
- // pointeur sur l'élément suivant
- type_element_de_liste *suivant;
- // valeur stockée par cet élément
- type_valeur valeur;
- };
- // définition d'une liste comme un pointeur sur un élément
- using liste = type_element_de_liste *;
- // définition de la liste vide
- const liste liste_vide = nullptr;

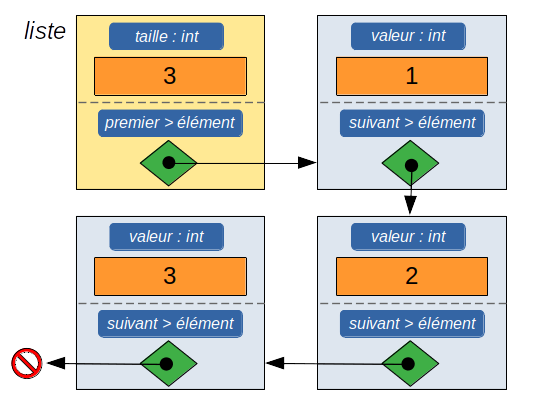
Une liste peut se réduire à l'utilisation d'éléments (maillons) chaînés entre eux, mais il est généralement préférable de définir un autre type liste qui stocke un pointeur sur le premier élément et le nombre d'éléments de la liste.
- typedef struct liste {
- // pointeur sur le premier élément de la liste
- type_element_de_liste *premier;
- // nombre d'éléments dans la liste
- int taille;
- } liste;
2.4. Variations sur les listes
Voici six exemples de l'implantation des listes sur le même thème issu du cours.
Ici, on ne dispose pas d'une structure de liste qui contient la taille de la liste et un pointeur sur le premier élément. Une liste est ici un pointeur sur un élément comme en cours.
2.4.1. Implantation à base de pointeurs de pointeurs
- itérative : il s'agit d'une implantation itérative utilisant des pointeurs et la synatxe du C/C++. On passe en paramètre de chaque sous-programme un pointeur sur la liste pour gérer les modifications (ajout, suppression)
- récursive : il s'agit de l'implantation récursive de la première version
- itérative, pointeurs, macros : amélioration de la première version en utilisant un type 'pointeur_sur_liste' et des macro-instructions afin de rendre le code plus lisible
- itérative, référence, macros : amélioration de la version précédente mais en utilisant l'opérateur de référence
2.4.2. Implantation à base de pointeurs
- itérative, macros : amélioration de la première version mais qui n'utilise pas de pointeur de pointeur pour passer une liste en paramètre. On passe la liste en paramètre et si on la modifie à l'intérieur du sous-programme, on retourne la nouvelle tête de liste
- récursive, macros : amélioration de la première version mais qui n'utilise pas de pointeur de pointeur pour passer une liste en paramètre. On passe la liste en paramètre et si on la modifie à l'intérieur du sous-programme, on retourne la nouvelle tête de liste
Les deux dernières versions sont probablement les plus sympathiques ;-) car :
- on n'utilise que des pointeurs et non des pointeurs de pointeurs ou des références sur pointeur
- on n'a les mêmes prototypes (signatures) de sous-programme en itératif ou en récursif
2.4.3. Application
Voici un exemple qui reprend l'implantation itérative avec des listes pour une personne qui est un struct composé de deux chaînes : nom et prénom.
Il est nécessaire de redéfinir deux opérateurs pour une personne :
- l'opérateur de sortie << pour l'affichage
- l'opérateur de comparaison > pour le tri
Voir le code liste de personnes.
2.4.4. Listes et récursion
La récursion sur les listes n'est pas une bonne chose en général.
En effet, définir un traitement récursif sur l'ajout en queue peut provoquer une saturation de la pile d'exécution du programme ou ralentir les traitements.
Heureusement, le compilateur gcc/g++ dérécursive la grande majorité des sous-programmes récursifs. Un simple test montre par exemple que sur AMD Ryzen 5600 G, si on utilise effectivement la récursion (il faut compiler avec g++ -O1), l'ajout en queue de $200\_000$ entiers dans une liste prend $50$ secondes alors que sans récursion on ne met plus que $18$ secondes.
Un autre test montre que si on utilise une structure de personne (nom, prénom et téléphone sous forme de string, comme en TP), l'ajout de la 43662 ième personne provoque une erreur de segmentation car la pile est saturée. En effet, on passe en paramètres de la fonction nom, prénom et téléphone à chaque appel de fonction.
En architecture 64 bits, la pile est initialement dans la méthode main à la valeur 238024d0_h . Elle descend jusqu'à 230047d0_h, soit une différence de 7fdd00_h $= 8\_379\_648_{10}$. Or la pile occupe 8 Mo soit $8\_388\_608$ octets, et, une fois dans la méthode main, on a déjà utilisé une partie de la pile. On a donc bien saturé la pile avec ces nombreux appels récursifs.