chr_replace
Implantation de la fonction suivante et comparaison avec une implantation SSE.
int chr_replace(char *src, char *dst, int n, char c, char d) {
int changes=0;
for (int i=0; i < n; ++i) {
if (src[i] == c) {
dst[i] = d;
++changes;
} else {
dst[i] = src[i];
}
}
return changes;
}
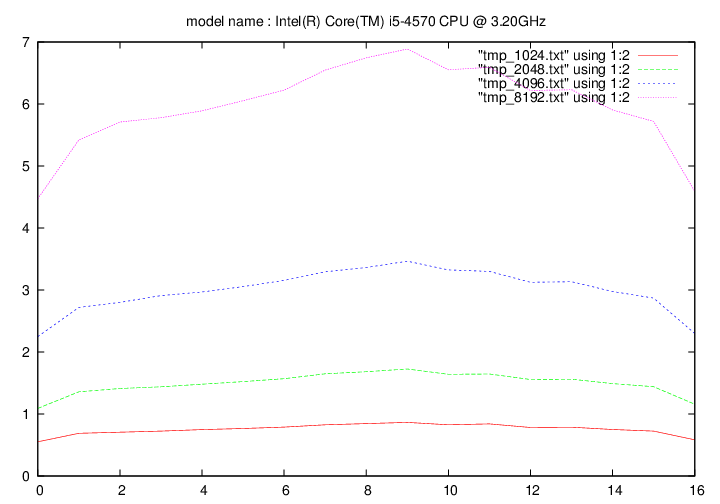
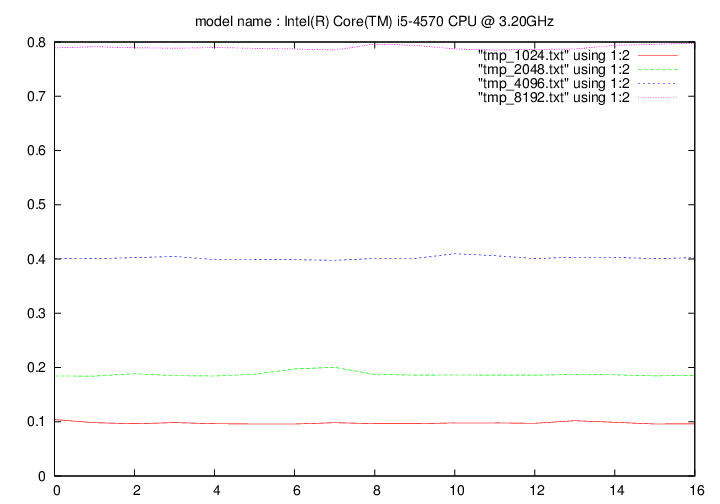
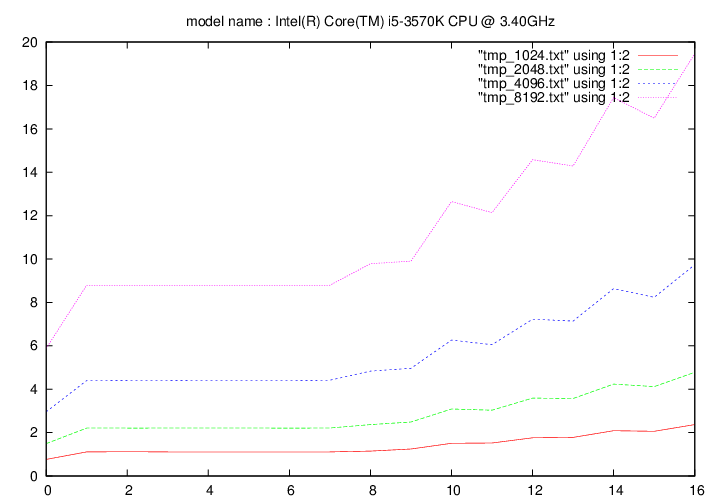
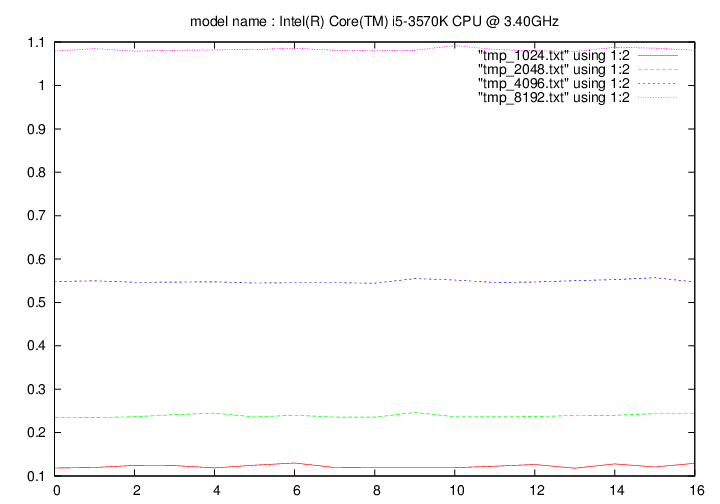
Les figures qui suivent affichent le temps d'exécution de la fonction de remplacement d'un caractère pour différentes longueurs de chaines (1024, 2048, 4096, 8192). On fait figurer :
- en ordonnée : temps en secondes
- en abscisse : nombre de caractères à remplacer par groupe de 16 caractères
Intel Core i5 4570 - 3.2 Ghz (Haswell)
- method 1:
- method 2:
Intel Core i5 3570k - 3.5 Ghz (Ivy Bridge)
- method 1:
- method 2:
Intel Core i7 2600k - 3.4 Ghz (Sandy Bridge)
- method 1:
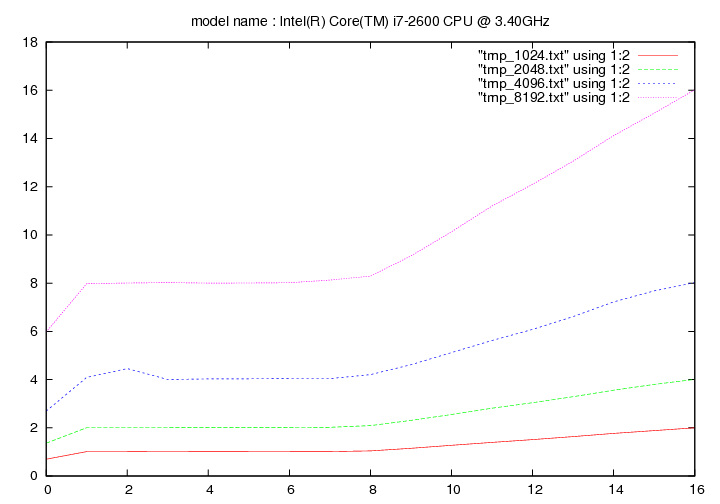
- method 2:
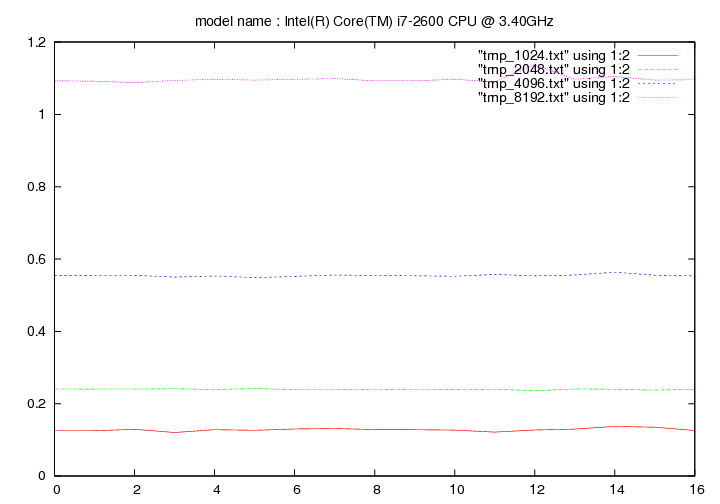
Intel Core i7 860 - 2.8 Ghz (Lynnfield)
- method 1:
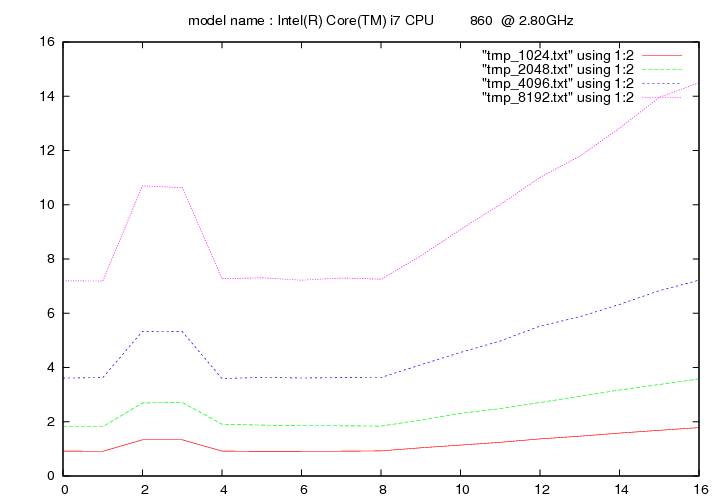
- method 2:
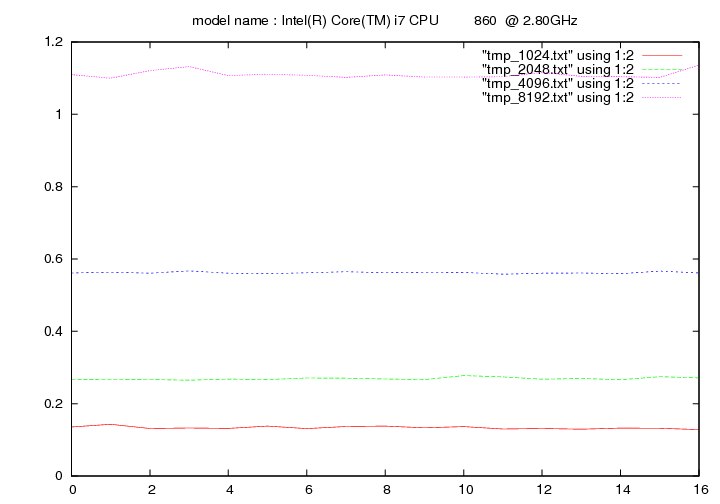
Intel Atom N450 - 1.66 Ghz (Diamondville)
- method 1:
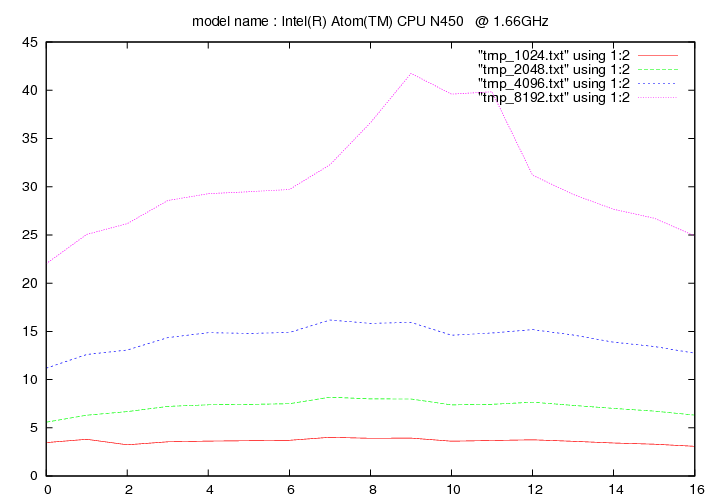
- method 2:
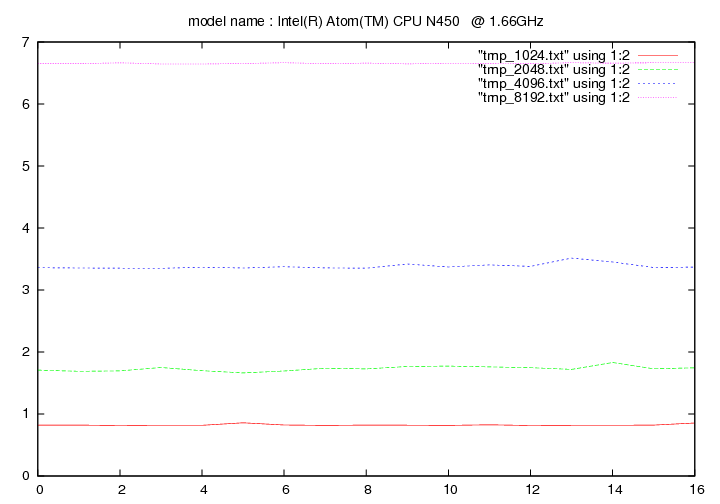
AMD Phenom II X6 1090T - 3,2 Ghz (Thuban)
- method 1:
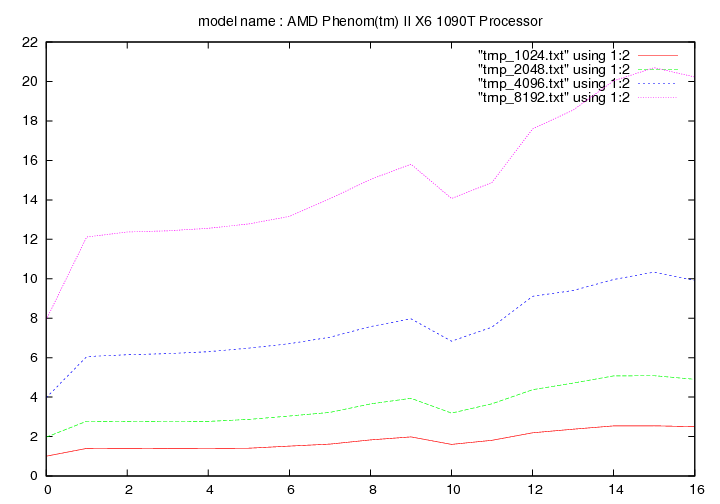
- method 2:
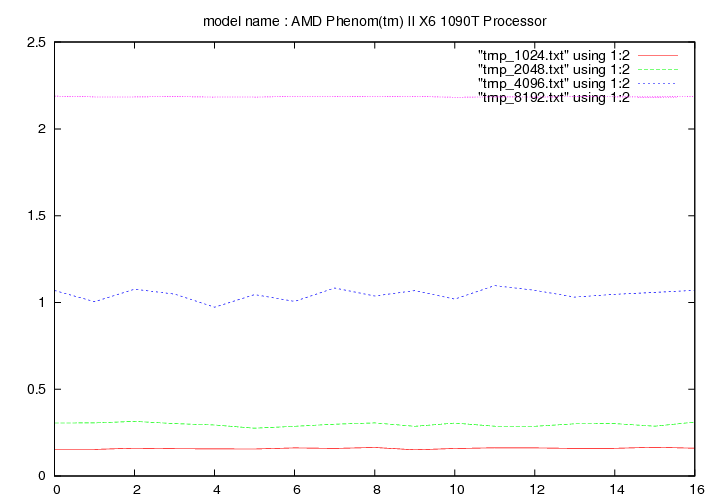
Intel Core Quad 9300 - 2.5 Ghz (Yorkfield)
- method 1:
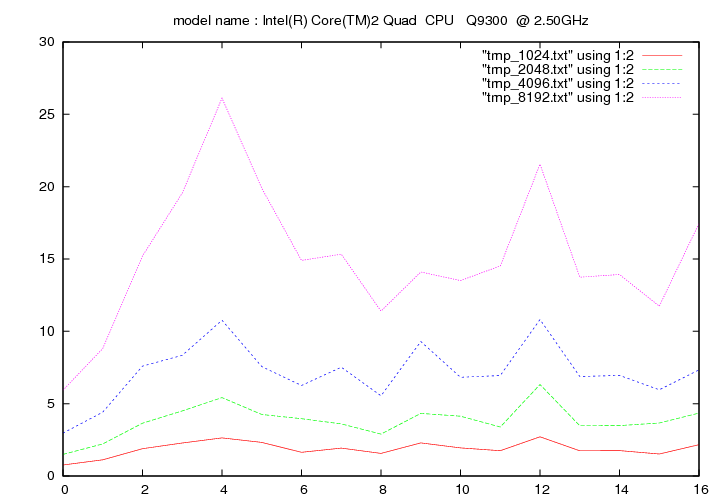
- method 2:
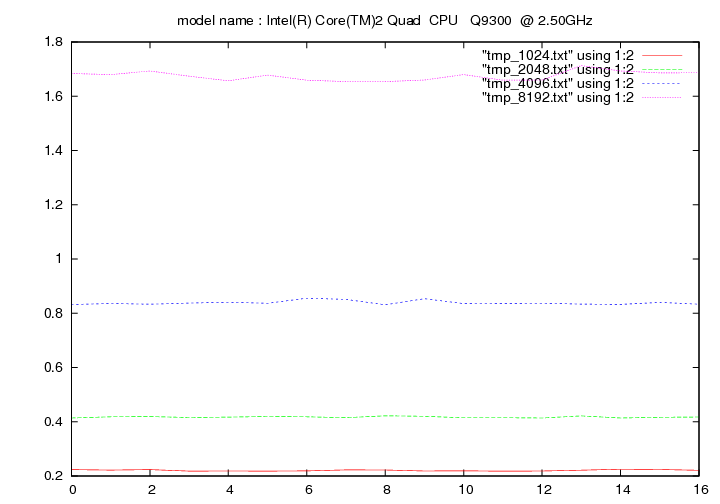
Intel Core Quad 6600 - 2.4 Ghz (Kentsfield)
- method 1:
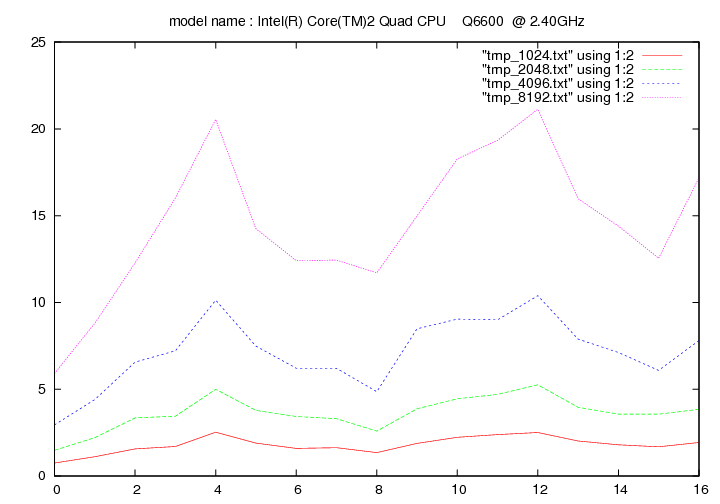
- method 2:
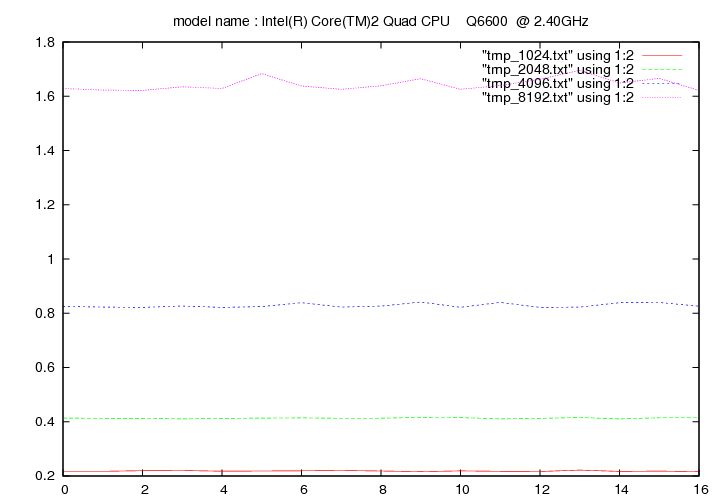
Intel Core 2 Duo E8400 - 3.0 Ghz (Dual Core - Wolfdale)
- method 1:
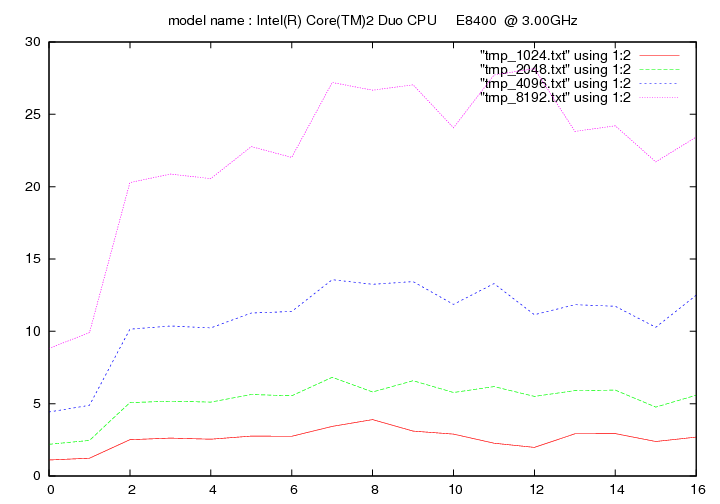
- method 2:
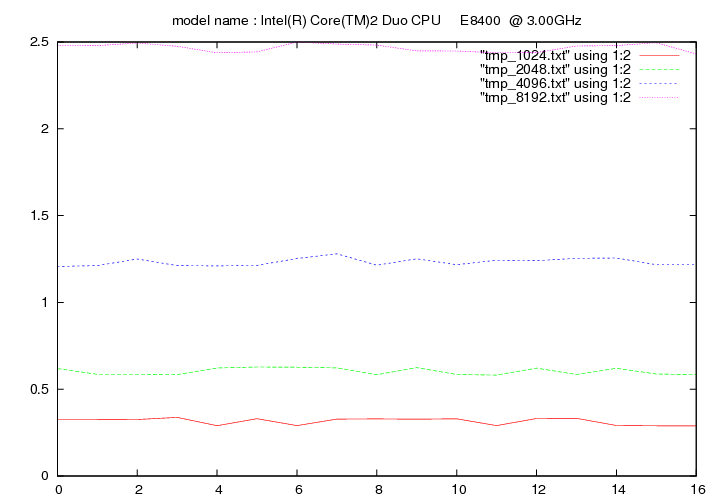
Le code
- /*
- * char_replace_sse42i.cpp
- *
- * Created on: Mar 8, 2017
- * Author: richer
- */
- int char_replace_sse42i(char *dst, char *src, int size, char c, char d) {
- int i, changes=0;
- __m128i v_src, v_c, v_d, v_cmp, v_res;
- // create a vector of 16 bytes containing c
- v_c = _mm_cvtsi32_si128(c * 0x01010101);
- v_c = _mm_shuffle_epi32(v_c, 0x00);
- // create a vector of 16 bytes containing d
- v_d = _mm_cvtsi32_si128(d * 0x01010101);
- v_d = _mm_shuffle_epi32(v_d, 0x00);
- // make loop a multiple of 16 bytes
- // and treat the remaining later
- for (i = 0; i < (size & ~15); i+= 16) {
- // load source data
- v_src = _mm_load_si128( (__m128i *) &src[i]);
- // compare to v_c
- v_cmp = _mm_cmpeq_epi8(v_src, v_c);
- // move comparison data to GPR
- int local_changes = _mm_movemask_epi8(v_cmp);
- // count number of differences
- #ifdef CPP_POPCOUNT_COMPLIANT
- #ifdef CPP_ARCHITECTURE_32_BITS
- changes += _mm_popcnt_u32(local_changes);
- #else
- changes += _mm_popcnt_u64(local_changes);
- #endif
- #else
- changes += __builtin_popcount(local_changes);
- #endif
- // conditionally copy bytes
- v_res = _mm_blendv_epi8(v_src, v_d, v_cmp);
- // store result
- _mm_store_si128( (__m128i *) &dst[i], v_res);
- }
- // treat remaining data
- while (i<size) {
- if (src[i] == c) {
- dst[i] = d;
- ++changes;
- } else {
- dst[i] = src[i];
- }
- ++i;
- }
- return changes;
- }
- global char_replace_sse20
- section .text
- ; int char_replace_sse2(char *dst, char *src, int n, char c, char d);
- ; esi, xmm3 = src
- ; edi = dst,
- ; edx = n / 4
- ; xmm0 = 0xff....ff
- ; xmm2 = c
- ; xmm3 = d
- ; eax = changes
- char_replace_sse20:
- push ebp
- mov ebp,esp
- push esi
- push edi
- push ebx
- movzx eax, byte PARAM_C
- ; mov ah,al
- ; mov cx,ax
- ; shl eax, 16
- ; or ax, cx
- ; movd xmm2, eax
- ; pshufd xmm2,xmm2,0
- movd xmm2, eax
- punpcklbw xmm2, xmm2
- punpcklbw xmm2, xmm2
- pshufd xmm2, xmm2, 0
- movzx eax, byte PARAM_D
- ; mov ah,al
- ; mov cx,ax
- ; shl eax, 16
- ; or ax, cx
- ; movd xmm3, eax
- ; pshufd xmm3,xmm3,0
- movd xmm3, eax
- punpcklbw xmm3, xmm3
- punpcklbw xmm3, xmm3
- pshufd xmm3, xmm3, 0
- xor eax, eax
- xor ecx, ecx
- mov esi, PARAM_SRC
- mov edi, PARAM_DST
- mov edx, PARAM_SIZE
- shr edx, 4
- test edx, edx
- jz .next_x1
- .loop_x16:
- movdqa xmm0, [esi] ; xmm0 = src[i:i+15]
- movdqa xmm1, xmm0 ; make a copy in xmm1
- ;
- ; compare xmm0 == xmm2 [c,...,c]
- ; if xmm0[i] == xmm2[i] then xmm0[i] = 0xFF else xmm0[i] = 0x00
- ;
- pcmpeqb xmm0, xmm2
- ; move mask to ebx
- ; if xmm0 = [ 0xFF, 0x00, 0xFF, 0xFF, 0x00, 0xFF, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00]
- ; then ebx = 0000.0000.0000.0000.1011.0100.1111.0000_b = 000B4F0_h
- pmovmskb ebx, xmm0
- movdqa xmm4, xmm0
- pand xmm0, xmm3
- ; PANDN xmm1, xmm2 => xmm1 = NOT(xmm1) & xmm2
- pandn xmm4, xmm1
- por xmm0, xmm4
- movdqa [edi], xmm0
- popcnt ebx, ebx
- add eax, ebx
- add edi, 16
- add esi, 16
- dec edx
- jnz .loop_x16
- .next_x1:
- mov edx, PARAM_SIZE
- and edx, 15
- test edx, edx
- jz .end
- .loop_x1:
- mov cl, byte [esi]
- cmp cl, byte PARAM_C
- jne .next
- mov cl, byte PARAM_D
- add eax, 1
- .next:
- mov byte [edi], cl
- inc esi
- inc edi
- dec edx
- jnz .loop_x1
- .end:
- pop ebx
- pop edi
- pop esi
- mov esp,ebp
- pop ebp
- ret
The PUNPCKLBW instruction interleaves the low-order bytes of the source and destination operands :
mov eax, 48
movd xmm2, eax [48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
punpcklbw xmm2, xmm2 [48, 48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
punpcklbw xmm2, xmm2 [48, 48, 48, 48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
pshufd xmm2, xmm2, 0 [48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48, 48]
La corps de la fonction principale réalise le traitement qui suit. On remplace 30_h par 40_h, le principe repose sur l'utilisation d'un masque :
movdqa xmm0, [esi] [30, 31, 32, 33 | 30, 30, 31, 31 | 31, 30, 30, 30 | 30, 31, 30, 30]
movdqa xmm1, xmm0
pcmpeqb xmm0, xmm2 [FF, 00, 00, 00 | FF, FF, 00, 00 | 00, FF, FF, FF | FF, 00, FF, FF]
pmovmskb ebx, xmm0 DE31_h = 1101.1110.0011.0001 (lire xmm2 à l'envers)
movdqa xmm4, xmm0 [FF, 00, 00, 00 | FF, FF, 00, 00 | 00, FF, FF, FF | FF, 00, FF, FF]
pand xmm0, xmm3 [40, 00, 00, 00 | 40, 40, 00, 00 | 00, 40, 40, 40 | 40, 00, 40, 40]
pandn xmm4, xmm1 [00, 31, 32, 33 | 00, 00, 31, 31 | 31, 00, 00, 00 | 00, 31, 00, 00]
por xmm0, xmm4 [40, 31, 32, 33 | 40, 40, 31, 31 | 31, 40, 40, 40 | 00, 31, 40, 40]