Ce site est en cours de reconstruction certains liens peuvent ne pas fonctionner ou certaines images peuvent ne pas s'afficher.
2. Application : analyse de données
Attention : la grande majorité du contenu de cette page a été généré avec Gemini de Google.
2.1. Problématique
Les Indiens Pimas sont une population amérindienne vivant principalement dans l'Arizona (États-Unis) et au Mexique. Ils sont mondialement connus dans la communauté scientifique et médicale en raison d'une triste réalité : ils présentent l'un des taux de diabète de type 2 et d'obésité les plus élevés au monde.
Cette situation s'explique par la combinaison de deux facteurs majeurs :
- une prédisposition génétique (l'hypothèse du gène économe) : Historiquement, les Pimas vivaient dans un environnement désertique aride où les famines étaient fréquentes. Leur métabolisme s'est adapté au fil des millénaires pour stocker extrêmement efficacement les graisses lors des périodes d'abondance afin de survivre aux périodes de disette.
- un changement radical de mode de vie : Au cours du 20ème siècle, notamment à cause du détournement de l'eau de leur rivière (la rivière Gila) par les colons, les Pimas de l'Arizona ont dû abandonner leur mode de vie agricole traditionnel (très actif, alimentation riche en fibres et faible en graisses) pour adopter un mode de vie occidental moderne (sédentarité, alimentation industrielle, riche en sucres et en mauvaises graisses).
Le contraste brutal entre leur génétique de "stockage" et l'abondance calorique moderne a provoqué une explosion des cas d'obésité et de diabète.
Le jeu de données (Pima Indians Diabetes Database) a été créé par le National Institute of Diabetes and Digestive and Kidney Diseases, ce dataset est devenu un standard en Machine Learning. Il contient les données médicales de femmes Pimas âgées d'au moins 21 ans. L 'objectif est prédictif : déterminer si une patiente va développer un diabète dans les 5 ans en se basant sur des mesures de diagnostic (taux de glucose, IMC, nombre de grossesses, insuline, etc.).
Le jeu de données possède 9 colonnes que nous appellerons :
- 8 variables prédictives (Features) :
- grossesses : nombre de fois où la patiente a été enceinte
- glucose : concentration de glucose plasmatique à 2 heures lors d'un test oral de tolérance au glucose
- pression : pression artérielle diastolique (en mm Hg)
- épaisseur : épaisseur du pli cutané tricipital (en mm), un indicateur de la masse graisseuse
- insuline : taux d'insuline sérique à 2 heures (en mu U/ml)
- IMC : Indice de Masse Corporelle (poids en kg / (taille en m)²)
- fonction (facteur de risque) : fonction d'hérédité du diabète (un score évaluant la probabilité de diabète en fonction des antécédents familiaux)
- age : âge de la patiente (en années)
- un variable cible (diabete) : variable binaire indiquant si la patiente a développé un diabète de type 2 dans les 5 années suivant ces mesures. (0 = Négatif, pas de diabète, 1 = Positif, diabète avéré)
Le champ glucose correspond au test HGPO (Hyperglycémie Provoquée par Voie Orale) qui est le test médical de référence mondial pour diagnostiquer le diabète et le prédiabète. Le test se déroule suivant le mode opératoire qui suit :
- à jeun : la patiente arrive au laboratoire le matin après avoir jeûné (sans manger ni boire de boissons sucrées) pendant 8 à 12 heures
- choc sucré : on lui fait boire très rapidement un liquide extrêmement sucré (75 grammes de glucose pur)
- attente : la patiente patiente calmement pendant exactement 2 heures
- prise de sang (à 2 heures) : prise de sang pour mesurer la concentration de glucose (le taux de sucre) dans son plasma sanguin
Comment interpréter le résultat ? Chez une personne saine dès que le glucose entre dans le sang, le pancréas détecte l'anomalie et libère immédiatement une forte dose d'insuline. L'insuline agit comme une clé qui ouvre les cellules pour qu'elles absorbent le sucre. Au bout de 2 heures, le sucre a été stocké et le taux dans le sang est redevenu normal.
Les valeurs du test sont donc interprétables ainsi :
- inférieur à 140 mg/dL : tolérance au glucose normale
- entre 40 et 199 mg/dL : intolérance au glucose (ou prédiabète)
- 200 mg/dL ou plus : diabète avéré
Le champ fonction évalue le risque génétique de la patiente en se basant sur ses antécédents familiaux. Plus ce score est élevé, plus le risque génétique (et donc la probabilité que l'algorithme prédise un diabète) est important. Dans le jeu de données Pima, cette valeur varie généralement entre 0.078 (risque génétique très faible) et 2.42 (risque génétique très élevé).
2.1.1. Description du problème
On désire analyser les données afin d'être en mesure de prédire si une patiente va développer un diabète.
On va donc jouer le rôle d'un data-analyste et faire du machine learning (apprentissage artificiel) et du deep-learning (apprentissage profond).
2.1.2. Analyse du problème
Le jeu de données comporte :
- 768 femmes d'origine Pima, âgées d'au moins 21 ans
- 8 variables explicatives (les caractéristiques de santé mesurées)
- 1 variable cible (le résultat que l'on cherche à prédire).
On va utiliser des packages Python qui permettent d'analyser les données et de les afficher de manière intelligible. On va notamment :
- générer des graphiques pour visualiser et comprendre les données
- créer une SVM (Support Vector Machine) pour prédire le diabète
- créer un réseau de neurones pour prédire le diabète
On dispose des packages :
- pandas : pour la gestion des donnnées (data frame)
- seaborn : pour la visualisation de données, il s'appuie sur matplotlib
- sklearn : pour l'apprentissage automatique (SVM)
- keras : pour le deep learning (réseaux de neurones)
2.2. Packages à installer
La liste des packages à installer est donnée par le fichier requirements.txt. On peut les installer grâce à la commande :
richer@solaris:~\$ pip install -r requirements.txt
...2.3. Script et analyse
Voici le script python, il est composé de plusieurs parties et fait un peu plus de 280 lignes :
Afficher le code ens/l1/python1/exemple_2/pimas_learning.py
- # ===================================================================
- # Jean-Michel Richer 2026
- # ===================================================================
- import sys
- import os
- # Désactive les avertissements d'information généraux de TensorFlow
- # repasser cette valeur à '0' pour les erreurs
- os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
- # Désactive spécifiquement le message d'avertissement de oneDNN
- os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
- # =================================================================
- # packages python
- # =================================================================
- import pandas as pd # pour les données
- import numpy as np # pour les données
- import matplotlib.pyplot as plt # pour les graphiques
- import seaborn as sns # pour les graphiques
- import sklearn.model_selection as skms
- import sklearn.preprocessing as skpre # for StandardScaler
- import sklearn.svm as sksvm # for SVM (Support Vector Machine)
- import sklearn.metrics as skmet # for accuracy_score, classification_report
- import sklearn.decomposition as skdec # for PCA (Principal Components Analysis)
- import tensorflow.keras as tf
- # palette de couleurs (sans / avec diabète)
- pal = ['green', 'red']
- """
- =================================================================
- Fonction qui affiche un titre
- =================================================================
- """
- def titre(s : str):
- print("\n"*3)
- print("="*50)
- print(f"{s.upper():^50}")
- print("="*50)
- """
- =================================================================
- Chargement du jeu de données relatif aux indiens pimas
- Affichage de statistiques concernant les colonnes de données
- =================================================================
- """
- def chargement():
- titre("chargement des données")
- url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
- df = pd.read_csv(url, names = ['grossesses', 'glucose', 'pression', 'epaisseur', 'insuline', 'IMC', 'fonction', 'age', 'diabete'])
- print(df.head())
- print(df.describe())
- diabete = df['diabete'].value_counts()
- print(f"- patientes sans diabète (0) : {diabete[0]}")
- print(f"- patientes avec diabète (1) : {diabete[1]}")
- print(f"-----------------------------------------")
- print(f"- total : {diabete.sum()}")
- return df
- """
- =================================================================
- Prétraitement des données
- - les colonnes contenant des 0 (absence de donnée) sont remplacées
- par la médiane
- =================================================================
- """
- def pretraitement(df, equalize):
- titre("prétaitrement")
- if equalize:
- print("- garde le même nombre de patientes avec et sans diabete")
- df_avec_diabete = df[df['diabete'] == 1]
- df_sans_diabete = df[df['diabete'] == 0]
- size = df_avec_diabete['diabete'].size
- print(f"size={size}")
- df_echantillon = df_sans_diabete.sample(n = size, random_state=42)
- df_equilibre = pd.concat([df_avec_diabete, df_echantillon])
- df = df_equilibre.sample(frac=1, random_state=42).reset_index(drop=True)
- median = df.median()
- colonnes_avec_zeros = ['glucose', 'pression', 'epaisseur', 'insuline', 'IMC']
- df[colonnes_avec_zeros] = df[colonnes_avec_zeros].replace(0, np.nan)
- df.fillna(df.median(), inplace=True)
- print(df[:5])
- return df
- """
- =================================================================
- Affichage de graphiques
- 1- répartition du diabète
- 2- matrice de corrélation
- 3- diabète en fonction de l'âge et du taux de glucose
- 4- pairplot
- =================================================================
- """
- def plots(df):
- global pal
- titre("génération des graphiques")
- # répartition du diabète
- plt.figure(figsize = (5,5))
- sns.countplot(x = 'diabete', data = df, hue = 'diabete', palette = pal, legend = False)
- plt.title("Répartition du diabète (0 = Non, 1 = Oui)")
- plt.savefig("repartition_diabete.png")
- plt.show()
- # matrice de corrélation
- plt.figure(figsize = (10,10))
- correlation = df.corr()
- sns.heatmap(correlation, cmap = 'flare', annot = True, fmt = ".2f")
- plt.title('Matrice de corrélation')
- plt.savefig("matrice_de_correlation.png")
- plt.show()
- # diabète en fn du glucose et de l'âge
- plt.figure(figsize = (10,10))
- sns.scatterplot(x = 'age', y = 'glucose', hue='diabete', data = df, palette = pal)
- plt.title("Diabète suivant âge et glucose")
- plt.savefig("diabete_age_glucose.png")
- plt.show()
- # pairplot en fonction des colonnes d'intérêt
- colonnes_interessantes = ['age', 'fonction', 'glucose', 'IMC', 'diabete']
- df_interet = df[colonnes_interessantes]
- sns.pairplot(df_interet, hue = 'diabete', palette = pal)
- plt.title("Analyse croisée des variables d'intérêt")
- plt.savefig("pair_plot.png")
- plt.show()
- """
- =================================================================
- Séparation et normalisation
- - séparation des données en lot d'entraînement (80%) et lot de
- test (20%)
- - normalisation avec un StandardScaler pour empêcher l'influence
- des grandes valeurs
- =================================================================
- """
- def separation_normalisation(df):
- titre("séparation et normalisation")
- # données en entrée tout sauf la colonne 'diabete'
- X = df.drop('diabete', axis = 1)
- # données en sortie : la colonne 'diabete'
- y = df['diabete']
- X_train, X_tests, y_train, y_tests = skms.train_test_split(X, y, test_size=0.2, random_state = 23, stratify = y)
- scaler = skpre.StandardScaler()
- X_train_scaled = scaler.fit_transform(X_train)
- X_tests_scaled = scaler.fit_transform(X_tests)
- print("\n- données initiales (5 premières lignes)")
- print("-"*60)
- print(X_train[:5])
- print("\n- données normalisées (5 premières lignes)")
- print("-"*60)
- print(X_train_scaled[:5])
- return X_train_scaled, X_tests_scaled, y_train, y_tests
- """
- =================================================================
- Prédiction avec Support Vector Machine
- - création de la SVM
- - apprentissage de la SVM
- - analyse du résultat (rapport de classification)
- - généère un graphique comparatif
- =================================================================
- """
- def prediction_svm(df, X_train, X_tests, y_train, y_tests):
- global pal
- titre("prédiction avec SVM")
- # création du prédicteur, entraînement et prédiction
- model = sksvm.SVC(kernel = 'rbf', C = 1.0, gamma = 'scale', class_weight='balanced')
- # apprentissage
- model.fit(X_train, y_train)
- # prédiction avec le classifier
- y_predict = model.predict(X_tests)
- # taux de prédiction
- model_accuracy = skmet.accuracy_score(y_tests, y_predict)
- # rapport d'analyse
- print(f"- précision de la SVM = {model_accuracy:.2f}")
- print("- rapport de classification")
- print(skmet.classification_report(y_tests, y_predict))
- # graphique comparatif
- pca = skdec.PCA(n_components = 2)
- print(pca)
- X_test_2d = pca.fit_transform(X_tests)
- plt.figure(figsize=(14, 6))
- # on positionne deux graphiques sur la même figure
- # celui de gauche correspond à la réalité
- # celui de droite correspond à la prédiction
- plt.subplot(1,2,1)
- sns.scatterplot(x = X_test_2d[:,0], y = X_test_2d[:,1], hue = y_tests, palette = pal)
- plt.title("Réalité")
- plt.xlabel("composante principale 1")
- plt.ylabel("composante principale 2")
- plt.legend(title='Diabète réel')
- plt.subplot(1,2,2)
- sns.scatterplot(x = X_test_2d[:,0], y = X_test_2d[:,1], hue = y_predict, palette = pal)
- plt.title("Prédiction")
- plt.xlabel("composante principale 1")
- plt.ylabel("composante principale 2")
- plt.legend(title='Diabète prédit')
- # affichage des graphiques
- plt.tight_layout()
- plt.savefig("svm.png")
- plt.show()
- """
- =================================================================
- Prédiction avec Réseau de Neurones
- - création du réseau
- - entraînement du réseau
- - analyse du résultat (rapport de classification)
- - génère un graphique comparatif
- =================================================================
- """
- def prediction_rn(df, X_train, X_tests, y_train, y_tests):
- global pal # palette
- titre("réseau de neurones")
- # création du réseau
- model = tf.Sequential([
- tf.layers.Input(shape=(8,)),
- tf.layers.Dense(12, activation = 'relu'),
- tf.layers.Dense(8, activation = 'relu'),
- tf.layers.Dense(1, activation='sigmoid')
- ])
- model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics=['accuracy'])
- # apprentissage du réseau
- print("- apprentissage, soyez patient")
- history = model.fit(X_train, y_train, epochs = 150, batch_size=32, verbose=0)
- # évaluation de la prédiction
- loss, accuracy = model.evaluate(X_tests, y_tests, verbose=0)
- print(f"- précision du réseau = {accuracy:.2f}")
- print(f"- perte = {loss:.2f}")
- print("- rapport de classification")
- y_predict_probabilite = model.predict(X_tests)
- y_predict = (y_predict_probabilite > 0.5).astype(int)
- y_predict = y_predict.flatten()
- print(skmet.classification_report(y_tests, y_predict))
- # sauvegarde des paramètres du réseau de neurones
- nom_fichier_keras = f"rn_model_{accuracy*100:.4f}.keras"
- model.save(nom_fichier_keras)
- # graphique comparatif
- pca = skdec.PCA(n_components = 2)
- print(pca)
- X_test_2d = pca.fit_transform(X_tests)
- plt.figure(figsize=(14, 6))
- # on positionne deux graphiques sur la même figure
- # celui de gauche correspond à la réalité
- # celui de droite correspond à la prédiction
- plt.subplot(1,2,1)
- sns.scatterplot(x = X_test_2d[:,0], y = X_test_2d[:,1], hue = y_tests, palette = pal)
- plt.title("Réalité")
- plt.xlabel("composante principale 1")
- plt.ylabel("composante principale 2")
- plt.legend(title='Diabète réel')
- plt.subplot(1,2,2)
- sns.scatterplot(x = X_test_2d[:,0], y = X_test_2d[:,1], hue = y_predict, palette = pal)
- plt.title("Prédiction")
- plt.xlabel("composante principale 1")
- plt.ylabel("composante principale 2")
- plt.legend(title='Diabète prédit')
- # affichage des graphiques
- plt.tight_layout()
- plt.savefig("rn.png")
- plt.show()
- """
- =================================================================
- Fonction principale
- - le programme accepte un éventuel paramètre "equalize" qui permet
- d'avoir un rapport 50/50 entre patientes avec ou sans diabète
- =================================================================
- """
- def main():
- equalize = False
- if len(sys.argv) > 1:
- if sys.argv[1] == "equalize":
- equalize = True
- pimas = chargement()
- pimas = pretraitement(pimas, equalize)
- plots(pimas)
- X_train_scaled, X_tests_scaled, y_train, y_tests = separation_normalisation(pimas)
- prediction_svm(pimas, X_train_scaled, X_tests_scaled, y_train, y_tests)
- prediction_rn(pimas, X_train_scaled, X_tests_scaled, y_train, y_tests)
- if __name__ == "__main__":
- main()
2.3.1. Chargement des données
On dispose d'une URL faisant référence au fichier .csv contenant les données mais sans le titre des colonnes. On fournit donc les noms des colonnes en français, puis on affiche les premières lignes du fichier ainsi que quelques statistiques.
- url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
- df = pd.read_csv(url, names = ['grossesses', 'glucose', 'pression', 'epaisseur', 'insuline', 'IMC', 'fonction', 'age', 'diabete'])
- print(df.head())
- print(df.describe())
grossesses glucose pression epaisseur insuline IMC fonction age diabete
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1
...
count 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578 0.471876 33.240885 0.348958
std 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160 0.331329 11.760232 0.476951
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.078000 21.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000 0.243750 24.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000 0.372500 29.000000 0.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000 0.626250 41.000000 1.000000
max 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000 2.420000 81.000000 1.000000
Par exemple la première colonne de statistiques concerne la grossesse :
- le minimum de grossesses est de 0
- le maximum de 17 (!)
- la moyenne est de 3,84
- l'écart-type est de 3,36 ce qui est important
- 25%, 50%, 75% sont les quartiles, dont notamment 50% qui correspond à la médiane
2.3.2. Première analyse des données
On évalue le nombre de patientes atteintes ou non de diabète :
- diabete = df['diabete'].value_counts()
- print(f"- patientes sans diabète (0) : {diabete[0]}")
- print(f"- patientes avec diabète (1) : {diabete[1]}")
- print(f"-----------------------------------------")
- print(f"- total : {diabete.sum()}")
On obtient
- 500 patientes sans diabète
- 268 patientes avec diabète
Soit une proportion 65% / 35%, ce qui indique que les patientes sans diabète sont presque deux fois plus importantes que celles avec diabète. La surreprésentation d'une catégorie par rapport à une autre peut biaiser les résultats.
2.3.3. Prétraitement des données
Dans la plupart des analyses de ce type, il existe beaucoup de données mais également beaucoup de données manquantes. On peut soit éliminer les patients avec trop de données manquantes soit modifier les données en remplaçant une donnée manquante par la médiane des données connues.
Ici, plusieurs colonnes sont concernées et pour lesquelles on fait le choix de la médiane, un zéro indiquant une donnée manquante.
Il faut bien comprendre que cela peut fausser les résultats !
- colonnes_avec_zeros = ['glucose', 'pression', 'epaisseur', 'insuline', 'IMC']
- df[colonnes_avec_zeros] = df[colonnes_avec_zeros].replace(0, np.nan)
- df.fillna(df.median(), inplace=True)
grossesses glucose pression epaisseur insuline IMC fonction age diabete
0 6 148.0 72.0 35.0 125.0 33.6 0.627 50 1
1 1 85.0 66.0 29.0 125.0 26.6 0.351 31 0
2 8 183.0 64.0 29.0 125.0 23.3 0.672 32 1
3 1 89.0 66.0 23.0 94.0 28.1 0.167 21 0
4 0 137.0 40.0 35.0 168.0 43.1 2.288 33 1
Attention, ici, pour l'insuline, la médiane donnée initialement était de 23.0 mais elle prenait en compte toutes les lignes qui contenaient des 0. La nouvelle médiane de 125.0 prend uniquement en compte les lignes qui n'ont pas de 0 pour cette colonne.
2.3.4. Génération de premiers graphiques
La visualisation graphique est souvent plus intéressante pour comprendre un jeu de données important. On génère ici trois graphiques.
- la répartition des patientes avec / sans diabète
- la matrice de corrélation des données dont le but est de voir si deux données sont corrélées (par exemple : IMC, poids, taille)
- le diabète en fonction du taux de glucose et de l'âge
- un pairplot qui compare deux à deux les facteurs les plus importants
2.3.4.a Répartition des patientes
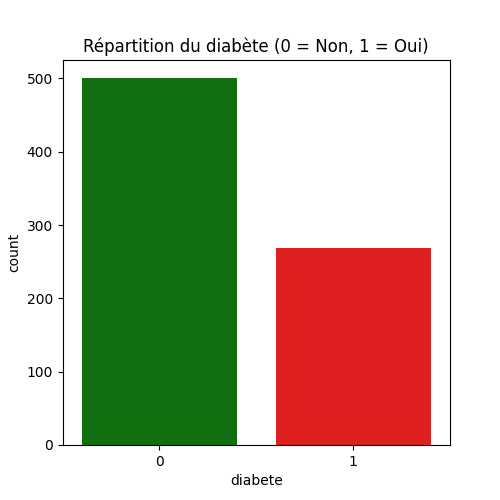
On voit graphiquement, comme indiqué précédemment, qu'il y à peu près deux fois plus de patientes sans diabète que de patientes avec diabète.
2.3.4.b Matrice de corrélation
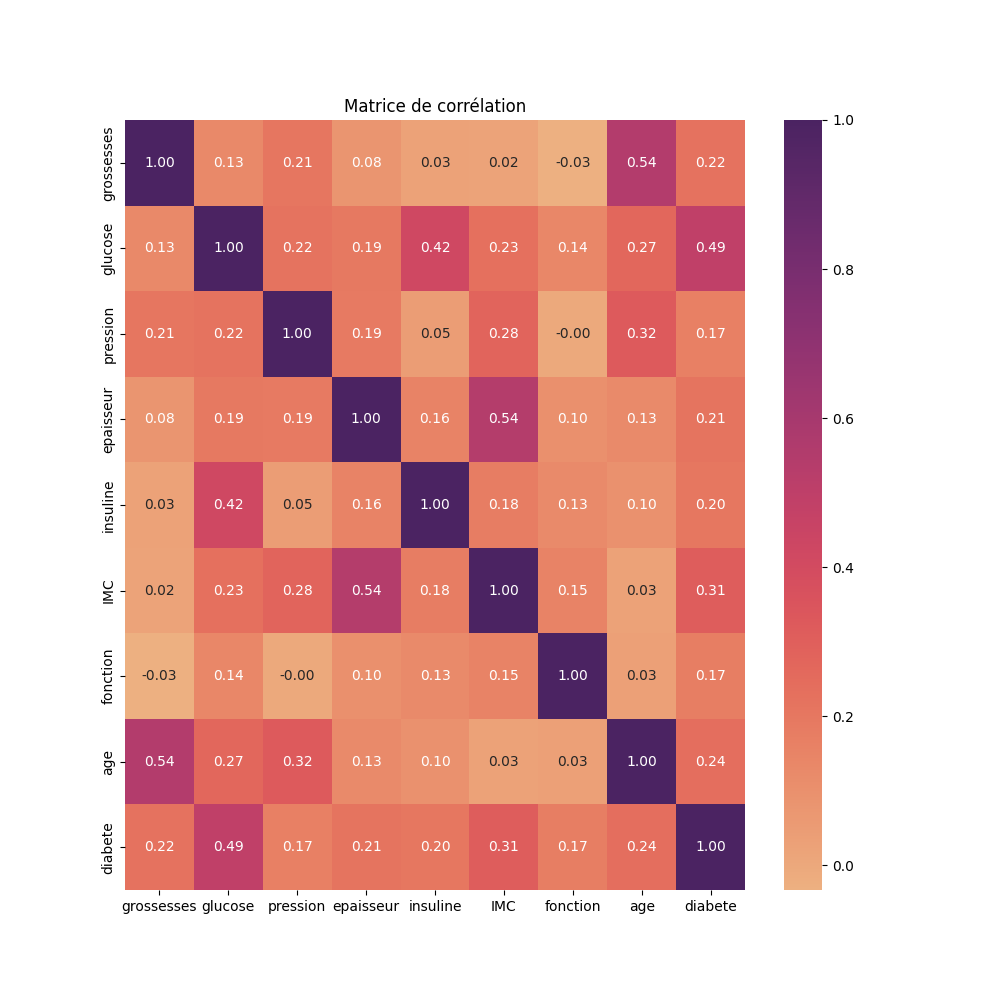
Pour ce graphique, plus les facteurs sont corrélés, plus on est proche de 1.0 (sauf pour la diagonale qui n'a pas de sens). On voit donc, si on regarde la partie triangulaire supérieure ou inférieure, que :
- grossesse et âge sont corrélés avec un valeur de 0.54, ce qui est logique : plus on est âgé, plus on a de grossesses
- glucose et diabète sont corrélés avec une valeur de 0.49 : plus le taux de glucose est elevé, plus on a de résistance à l'insuline et donc du diabète
- épaisseur de la peau et IMC sont corrélés avec une valeur de 0.54, logique également
- le nombre de grossesses et le taux d'insuline ne sont pas corrélés car la valeur est de 0.03
2.3.4.c Diabète en fonction du taux de glucose et de l'âge
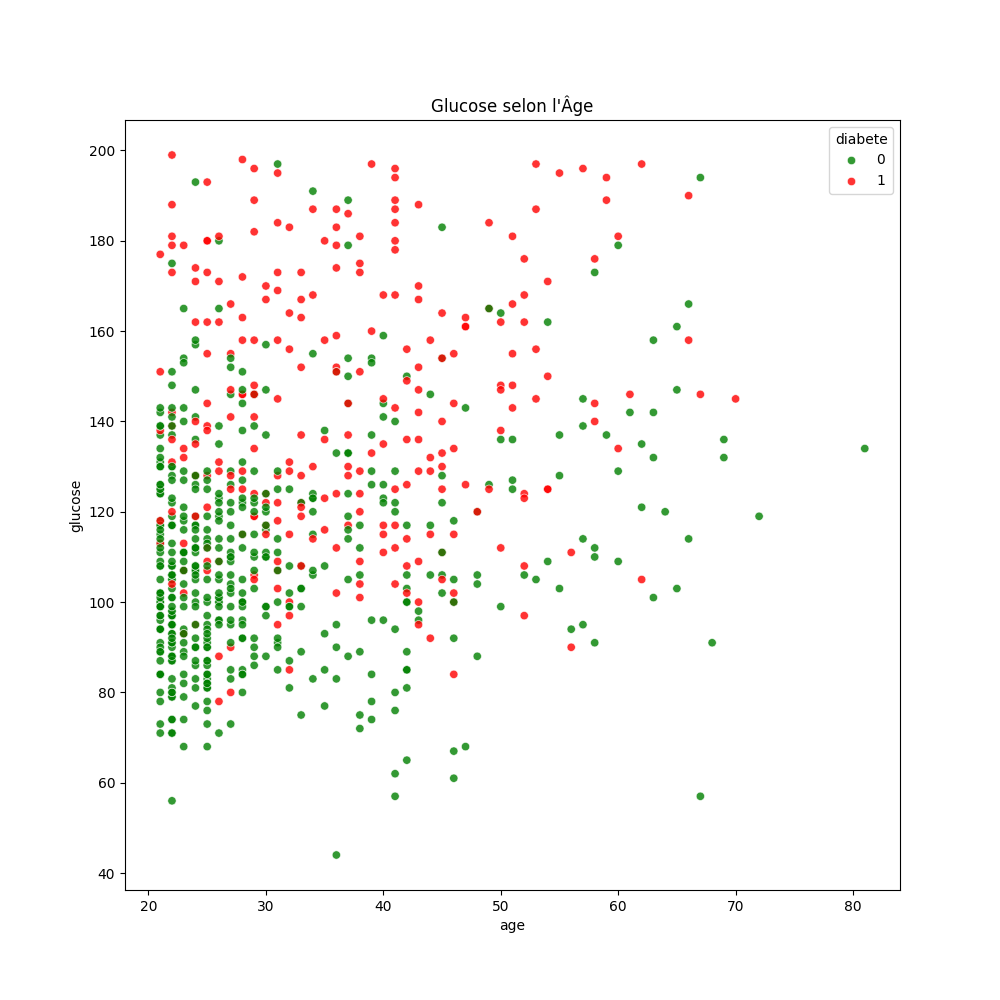
Le test du taux de glucose est très important pour déterminer le diabète. Sur le graphique on note beaucoup de points verts pour des patientes :
- de moins de 30 ans
- avec un taux de glucose de moins de 140 mg/dL ce qui indique une tolérance au glucose normale et que le corps gère bien le sucre
Cependant, on observe également deux patientes atteintes de diabète de moins de 30 ans et un taux de glucose < 80 mg/dL !
2.3.4.d Pair-plot
Le pair-plot visualise les relations par paires entre toutes (ou partie) des variables d'un jeu de données.
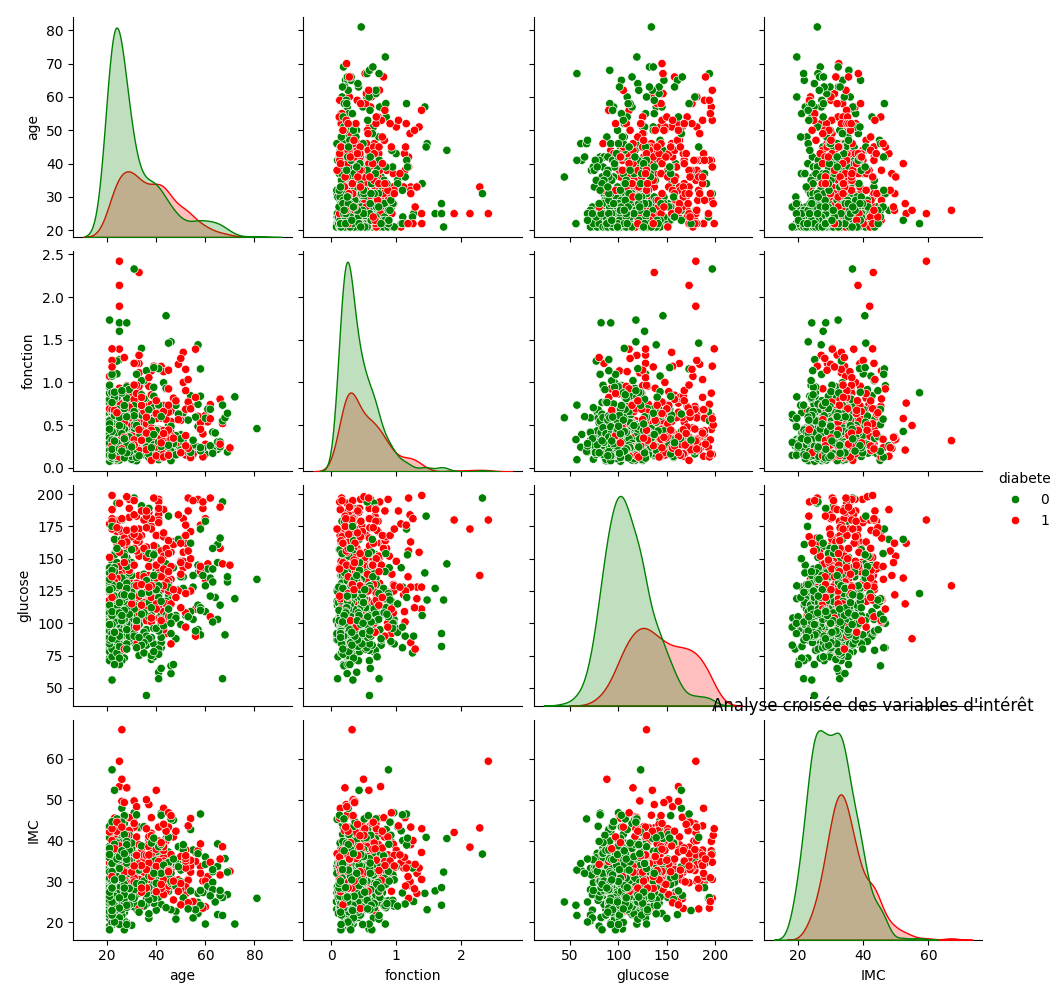
Le diagramme ci-dessus permet de voir clairement qu'il sera difficile de classer les données (présence / absence de diabète) car on ne peut pas tracer de frontière entre le points verts et les points rouge. Si on peut tracer une ligne, une courbe ou un patatoïde qui sépare les données en deux ensembles distincts alors il est plutôt facile de trouver une classification.

2.3.5. Séparation et normalisation des données
Deux étapes préalables au traitement des données sont généralement effectuées avant de mettre en place des algorithmes de prédiction :
- la première est la séparation des données en deux groupes :
- le groupe d'entraînement qui consiste à prendre 70 à 80% des données
- le groupe de test qui consiste à prendre 30 à 20% des données
- la normalisation des données des deux groupes
Au final on obtient :
- deux matrices
X_train etX_test qui sont les données (connues) en entrées - ainsi que deux vecteurs
y_train ety_test qui sont les données (également connues) mais que l'on veut prédire
La normalisation est nécessaire notamment pour les SVM et Réseaux de Neurones car si une variable possède de grandes valeurs ($v > 100$) et une autre variable de petites valeurs ($0 < w < 1$), alors la variable $w$ risque d'être totalement ignorée.
On utilise par exemple un
$$z = {x - μ}/σ $$
On soustrait la moyenne de la colonne ($μ$) à chaque valeur. Cela permet de "centrer" les données autour de 0. Puis on divise ensuite par l'écart-type de la colonne ($σ$). Cela permet d'avoir une dispersion (un écart-type) exactement égale à 1.
2.3.6. Prédiction par SVM
2.3.6.a Prédicteur
Une Machine à Vecteurs de Support (SVM) est un algorithme d'apprentissage automatique dont le but est de trouver la meilleure frontière possible pour séparer différentes catégories de données (hyperplan).
- # création du prédicteur, entraînement et prédiction
- model = sksvm.SVC(kernel = 'rbf', C = 1.0, gamma = 'scale', class_weight='balanced')
- model.fit(X_train, y_train)
- y_predict = model.predict(X_tests)
- model_accuracy = skmet.accuracy_score(y_tests, y_predict)
- # rapport d'analyse
- print(f"- précision du SVM = {model_accuracy:.2f}")
- print("- rapport de classification")
- print(skmet.classification_report(y_tests, y_predict))
Le réslutat obtenu est le suivant :
==================================================
PRÉDICTION AVEC SVM
==================================================
- précision du SVM = 0.73
- rapport de classification
precision recall f1-score support
0 0.85 0.70 0.77 100
1 0.58 0.78 0.67 54
accuracy 0.73 154
macro avg 0.72 0.74 0.72 154
weighted avg 0.76 0.73 0.73 154
On parvient à prédire 75% des données du jet de test ce qui est bien mais pas extraordinaire. Cela signifie que dans 75% des cas on prédit la réponse attendue, on a donc 25% de chance de commettre une erreur.
L'analyse plus fine indique qu'on a 100 patientes de classe 0 (sans diabète) et 54 de classe 1 (avec diabète).
- pour la classe 0, la classe majoritaire, on note :
- une précision (0.85) : quand le modèle prédit qu'un élément appartient à la classe 0, il a raison dans 85% des cas
- un recall / rappel (0.70) : le modèle a réussi à trouver 70% de tous les vrais éléments de la classe 0
- un f1-score (0.77) : c'est la moyenne harmonique entre la précision et le rappel très correct, le modèle est confiant sur cette classe
- pour la classe 1, on observe :
- une précision (0.58) : quand le modèle prédit la classe 1, il se trompe presque une fois sur deux (42 % de faux positifs)
- un recall / rappel (0.78), c'est plutôt bon
- un f1-score (0.65) : le modèle a un peu plus de mal à prédire la classe 1
A priori le SVM souffre d'un biais vers la classe majoritaire : il a tendance à prédire 0 (pas de diabète) plus souvent parce qu'il a vu plus d'exemples sans diabète pendant son entraînement.
2.3.6.b Graphique
Pour afficher le résultat obtenu et comparer au jeu initial, on peut créer un petit graphique :
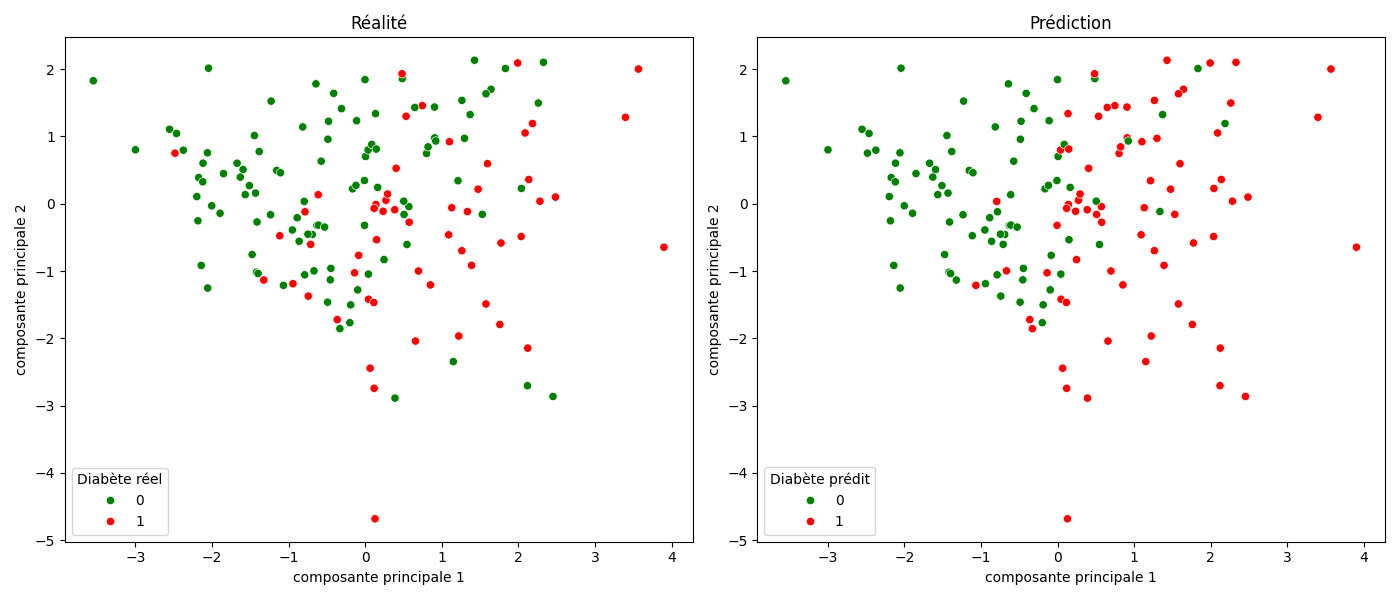
On affiche le graphique avec deux coordonnées fictives que l'on appelle des composantes principales. Chacune de ces composantes est une combinaison mathématique, une sorte de mélange, de toutes les colonnes d'origine.
L'analogie : si nos colonnes sont des fruits, la PCA ne choisit pas d'afficher une pomme et une banane. Elle crée un smoothie. La Composante Principale 1 est un jus composé, par exemple, à 60% de Glucose, 30% d'IMC, 5% d'Âge et 5% d'Insuline.
2.3.7. Prédiction par Réseau de Neurones
2.3.7.a Prédicteur
Un réseau de neurones (RN) agit comme un classifieur ou un prédicteur et dont le fonctionnement s'inspire du cerveau humain. Il dispose de plusieurs couches de neurones dont le but est de capturer une partie de l'information globale.
Le réseau de neurones est composé :
- d'un couche d'entrée de neurones (les données en entrée)
- d'une ou plusieurs couches intermédiaires de neurones
- d'une couche de sortie
- un classifieur a pour but de classer des données dans diverses catégories : en sortie on aura plusieurs neurones avec des valeurs 0 et normalement un seul neurone à la valeur 1
- un prédicteur prédit la donnée la plus probable : on sortie on aura plusieurs neurones avec des valeurs différentes qui résultent du calcul du RN
Il demande beaucoup de calculs car on doit entraîner le réseau à prédire le bon résultat par essais successifs et correction d'erreurs. On peut comparer le processus d'entraînement (également nommé apprentissage) à la minimisation d'une fonction d'énergie, où l'énergie est l'erreur par rapport aux bonnes prédictions.
Voici un exemple de réseau de neurone qui peut vous aider à comprendre le principe de fonctionnement des RN.
2.3.7.b Conception du réseau
On veut ici générer un classifieur qui indique si oui ou non une patiente va déclencher du diabète dans 5 ans.
- model = tf.Sequential([
- tf.layers.Input(shape=(8,)),
- tf.layers.Dense(12, activation = 'relu'),
- tf.layers.Dense(8, activation = 'relu'),
- tf.layers.Dense(1, activation='sigmoid')
- ])
- model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics=['accuracy'])
On crée un réseau composé :
- d'un couche d'entrée de 8 neurones qui seront nos 8 facteurs (grossesse, glucose, âge, ...)
- une première couche intermédiaire de 12 neurones avec une
fonction d'activation de type ReLU - une seconde couche intermédiaire de 8 neurones avec une fonction d'activation de type ReLU
- une couche de sortie de 1 neurone avec une fonction de type sigmoïde qui indiquera s'il y a ou non diabète
Le choix du nombre de couches intermédiaires ainsi que le nombre de neurones dans chaque couche intermédiaire est laissé au programmeur.
Les
- la fonction sigmoïde transforme n'importe quel nombre réel en une valeur comprise entre 0 et 1. Elle a une forme caractéristique en "S".
Sa formule mathématique est :
$$ sigmoid(x) = 1 / ( 1 + e^{-x})$$ - la fonction ReLU (Rectified Linear Unit) est beaucoup plus simple. Elle agit comme un filtre : elle laisse passer les
valeurs positives telles quelles et bloque (met à zéro) toutes les valeurs négatives. Sa formule mathématique est :
$$relu(x) = max(0,x)$$
2.3.7.c Entraînement du réseau et résultats
On passe en paramètre de l'apprentissage (fonction
On indique également de réaliser 150 évaluations en prenant les patientes par groupes de 32 personnes.
On évalue ensuite (fonction
- history = model.fit(X_train, y_train, epochs = 150, batch_size=32, verbose=0)
- loss, accuracy = model.evaluate(X_tests, y_tests, verbose=0)
- print(f"- précision = {accuracy:.2f}")
- print(f"- perte = {loss:.2f}")
- print("- rapport de classification")
- y_predict_probabilite = model.predict(X_tests)
- y_predict = (y_predict_probabilite > 0.5).astype(int)
- y_predict = y_predict.flatten()
- print(skmet.classification_report(y_tests, y_predict))
- précision du réseau = 0.75
- perte = 0.55
- rapport de classification
precision recall f1-score support
0 0.83 0.78 0.80 100
1 0.63 0.70 0.67 54
accuracy 0.75 154
macro avg 0.73 0.74 0.74 154
weighted avg 0.76 0.75 0.76 154
On obtient des résultats similaires à ceux d'une SVM avec un prédiction de 75% bonnes prédictions sur le jeu de test.
2.4. Modification des données
On a vu que les patientes sans diabète sont sur-représentées. Que se passe t-il si parmi les 500 patientes sans diabète, on en choisit aléatoirement autant (268) que de patientes avec diabète ?
Dans ce cas, on obtient un meilleure prédiction aux alentours de 77 à 78%.
2.5. En résumé
Il est très difficile de prédire de manière précise sur des données du vivant.
La normalisation des données peut introduire un biais non négligeable, la donnée est donc très importante et doit être la plus précise possible. Peut-être manque t-il également d'autres données : taux de triglycérides, etc qui permettrait d'augmenter le taux de bonnes prédictions.
Néanmoins, en quelques lignes de Python, on peut réaliser des traitements complexes et se faire passer pour un data-analyste.